
AWS has announced the launch of Amazon S3 Files, a groundbreaking new file system designed to seamlessly connect any AWS compute resource with Amazon Simple Storage Service (Amazon S3). This innovation marks a significant evolution in cloud storage, effectively eliminating a long-standing architectural trade-off between the cost-effectiveness and durability of object storage and the interactive capabilities of traditional file systems. The introduction of S3 Files empowers organizations to leverage Amazon S3 as a universal data hub, directly accessible via standard file system interfaces, thereby simplifying cloud architectures and accelerating a wide range of data-intensive workloads, including those in artificial intelligence (AI) and machine learning (ML).
Historical Context and the Evolution of Cloud Storage Paradigms
For over a decade, cloud architects and engineers have navigated the fundamental differences between object storage and file systems. Amazon S3, launched in 2006, revolutionized data storage with its massive scalability, unparalleled durability, and cost-efficiency, presenting data as immutable objects rather than hierarchical files. This object-based paradigm, while ideal for vast data lakes, backups, and static content, presented challenges for applications requiring byte-range writes, in-place modifications, or concurrent, interactive access common in traditional file-based workflows. The analogy often used was comparing S3 objects to books in a library – to change a single page, one would typically replace the entire book, starkly contrasting with the page-by-page editability of files on a local computer.

This distinction necessitated customers choosing between S3’s compelling benefits and the interactive, shared capabilities of a file system. AWS subsequently introduced services like Amazon Elastic File System (EFS) for scalable, shared network file system (NFS) access and the Amazon FSx family (for Lustre, NetApp ONTAP, OpenZFS, and Windows File Server) to address specific performance and compatibility requirements for various enterprise workloads. While these services provided robust file system solutions, they often required data movement or synchronization layers to interact with data residing in S3, introducing complexity, potential latency, and additional operational overhead. Amazon S3 Files directly addresses this historical dichotomy, offering a unified approach that combines the best attributes of both worlds.
Key Features and Technical Architecture of S3 Files
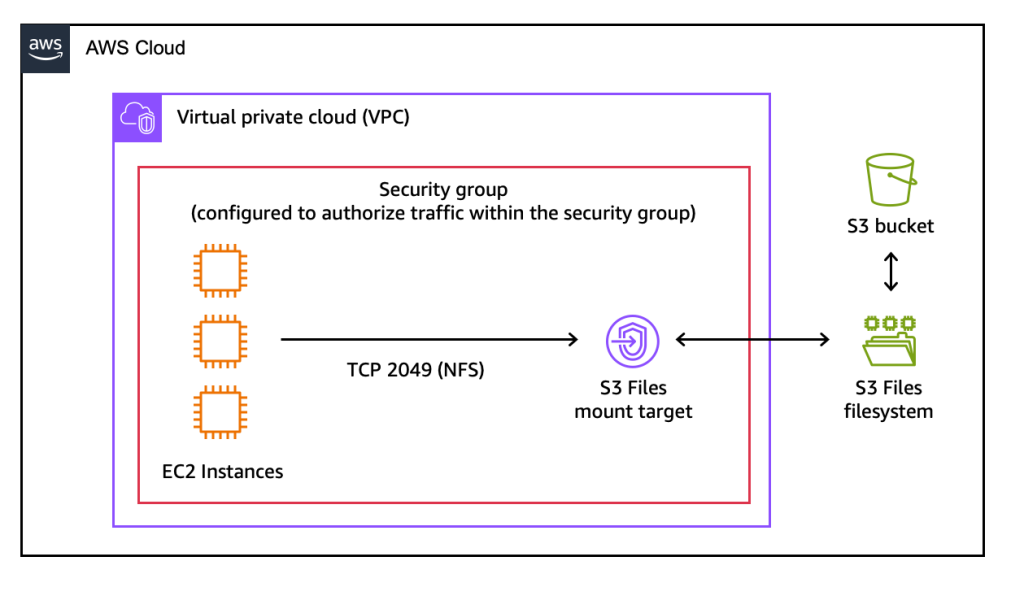
Amazon S3 Files positions S3 as the first and only cloud object store to offer fully-featured, high-performance file system access directly to data. It transforms S3 buckets into mountable file systems, enabling applications to interact with S3 objects as if they were local files and directories. This capability supports a comprehensive set of Network File System (NFS) v4.1+ operations, including creating, reading, updating, and deleting files, which are automatically reflected in the underlying S3 bucket.
Underpinning S3 Files’ high performance is its intelligent architecture, which leverages Amazon Elastic File System (Amazon EFS) for its active data tier. This integration delivers sub-millisecond latencies, typically around 1ms, for frequently accessed data. When data is accessed through the S3 Files interface, relevant file metadata and contents are intelligently placed onto this high-performance storage layer. For files that do not require low-latency access, such as those necessitating large sequential reads, S3 Files automatically serves them directly from Amazon S3, optimizing for maximum throughput and minimizing unnecessary data movement. Crucially, for byte-range reads, only the specific requested bytes are transferred, further reducing data transfer costs and improving efficiency.

The system also incorporates intelligent pre-fetching capabilities, anticipating data access patterns to proactively load data that applications are likely to need next. Users are afforded fine-grained control over this caching mechanism, allowing them to decide whether to load full file data or metadata only, thus optimizing for specific access patterns and cost considerations. This dual-tier approach—high-performance caching for active data and direct S3 access for less active or large sequential reads—ensures both responsiveness and cost-effectiveness.
Furthermore, S3 Files supports concurrent access from multiple compute resources, maintaining NFS close-to-open consistency. This feature is paramount for collaborative and interactive workloads where multiple agents or processes might simultaneously read from and write to the same files, making it an ideal solution for modern, distributed applications. Changes made to files via the S3 Files interface are automatically managed and exported as new objects or versions back to the S3 bucket within minutes, while changes made directly to S3 objects become visible in the file system typically within seconds, though sometimes up to a minute or longer, ensuring a robust synchronization mechanism.
Transformative Potential and Broad Use Cases
The implications of Amazon S3 Files are far-reaching, particularly for workloads that have historically struggled with the object storage paradigm.
- Artificial Intelligence and Machine Learning (AI/ML): AI/ML training pipelines often require fast, shared access to large datasets, with models frequently making iterative, small updates to checkpoints or intermediary results. S3 Files allows ML engineers to leverage the vast, cost-effective storage of S3 for their datasets while providing the low-latency, file-system access required by training frameworks, Python libraries, and various ML tools. Agentic AI systems, which rely on collaborative interactions through file-based tools and scripts, will find S3 Files invaluable for shared state and communication.
- Data Analytics: For big data analytics engines that traditionally interact with HDFS-like file systems or require local file access, S3 Files provides a performant bridge, enabling direct access to S3-resident data lakes without complex data movement or intermediate processing layers. This simplifies data architectures for tools like Apache Spark, Presto, and Hive.
- DevOps and Production Applications: Many existing production applications and DevOps tools are designed to work with traditional file systems. S3 Files enables these applications to seamlessly integrate with S3, leveraging its durability and scalability without requiring significant code refactoring or custom connectors. This is particularly beneficial for lift-and-shift migrations of legacy applications to the cloud.
- Content Creation and Media Workflows: Industries dealing with large media files, such as video editing, animation, and graphic design, often require high-performance, shared storage. S3 Files can provide collaborative access to media assets stored in S3, streamlining workflows and reducing the need for costly, dedicated file servers.
- General Purpose Shared Storage: For any workload requiring shared, interactive access to mutable data across multiple compute instances, containers, or serverless functions, S3 Files offers a compelling solution. It eliminates data duplication across clusters and simplifies data sharing, leading to more efficient resource utilization and reduced operational complexity.
Architectural Simplification and Strategic Importance
The introduction of S3 Files represents a strategic move by AWS to further solidify S3’s position as the central data hub for all organizational data in the cloud. By dissolving the object-file distinction, AWS aims to simplify cloud architectures, eliminate data silos, and reduce the need for complex, manual data movement or synchronization processes between different storage types. This consolidation provides a unified approach to data management, governance, and security across an organization’s entire data estate.
AWS executives are expected to highlight S3 Files as a pivotal development for customers seeking to standardize on S3 for all data, from archival to actively processed data. A spokesperson for AWS might emphasize that "S3 Files empowers customers to unlock new levels of agility and innovation by making their S3 data directly accessible to any AWS compute resource, fostering a truly unified data environment." Industry analysts suggest this move will significantly lower the barrier to entry for many traditional enterprise workloads into the S3 ecosystem, potentially accelerating cloud adoption and the migration of on-premises file-based systems.
Comparing S3 Files with Existing AWS File Services
With S3 Files entering the AWS storage portfolio, customers now have an even broader range of choices, necessitating a clear understanding of each service’s optimal use case. AWS proactively addresses this potential confusion by outlining distinct scenarios for its file services:
- Amazon S3 Files: Ideal for interactive, shared access to data primarily residing in Amazon S3, through a high-performance file system interface. It excels in workloads where multiple compute resources—be they production applications, agentic AI agents using Python libraries and CLI tools, or machine learning (ML) training pipelines—need to read, write, and mutate data collaboratively. Its strength lies in its automatic synchronization with the S3 bucket and sub-millisecond latency for active data, all while leveraging S3’s cost and durability.
- Amazon Elastic File System (EFS): Best suited for workloads that require a fully managed, scalable NFS file system with elastic capacity and performance. EFS is a general-purpose file system designed for a broad range of applications, including web serving, content management, home directories, and development environments. While S3 Files leverages EFS under the hood for its performance tier, EFS itself is a standalone file system not intrinsically tied to an S3 bucket in the same direct, synchronized manner.
- Amazon FSx Family: This suite of services is designed for specific, specialized file system needs.
- Amazon FSx for Lustre: Optimized for high-performance computing (HPC) and GPU clusters, offering extremely low latency and high throughput for bursty workloads, often used with data from S3 but managed distinctly.
- Amazon FSx for NetApp ONTAP, Amazon FSx for OpenZFS, and Amazon FSx for Windows File Server: These are tailored for workloads migrating from on-premises NAS environments, providing familiar features, APIs, and compatibility with specific enterprise file system protocols and functionalities. They are ideal when applications require specific features or performance characteristics inherent to these specialized file systems.
In essence, S3 Files simplifies access to S3 for file-based workloads, making S3 the primary source of truth. EFS provides a general-purpose, scalable NFS solution, and FSx offers specialized file systems for niche, high-performance, or compatibility-driven requirements. The key differentiator for S3 Files is its direct, transparent, and synchronized link to an S3 bucket, making the object store inherently file-addressable.
Availability and Pricing Structure
Amazon S3 Files is available today in all commercial AWS Regions, enabling immediate adoption for global customers. This broad availability underscores AWS’s commitment to making this foundational capability accessible across its vast infrastructure.
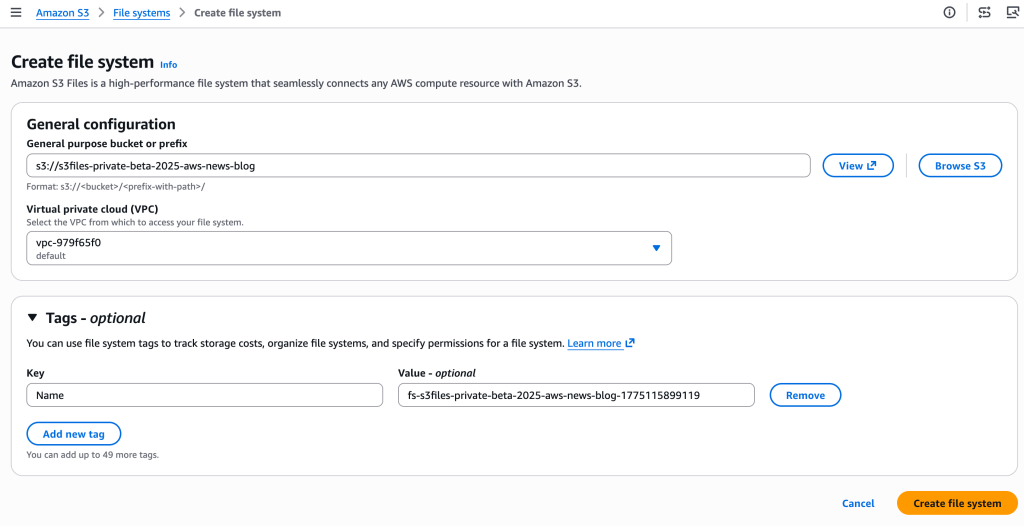
The pricing model for S3 Files is structured to reflect its hybrid nature, combining elements of file system and object storage costs. Customers will pay for:
- Data stored in the S3 file system: This refers to the portion of data that resides in the high-performance file system tier (powered by EFS) for active access.
- Small file read and all write operations to the file system: These operations incurred on the active file system layer.
- S3 requests during data synchronization: Costs associated with the underlying S3 PUT, GET, LIST, and other requests made to the S3 bucket as data is synchronized between the file system and S3.
Detailed pricing information, including specific rates for storage, data transfer, and request types, is available on the Amazon S3 pricing page. This transparent pricing model allows organizations to effectively estimate costs based on their specific usage patterns and data access needs.
Conclusion and Future Outlook
The launch of Amazon S3 Files marks a pivotal moment in cloud storage, fundamentally altering how organizations can interact with their data in AWS. By seamlessly integrating the vast scalability and durability of Amazon S3 with the interactive, high-performance capabilities of a file system, AWS has effectively resolved a long-standing architectural challenge. This innovation is expected to significantly simplify cloud architectures, reduce operational complexities, and unlock new possibilities for data-intensive applications across various industries.
The ability to use S3 as a universal data repository, directly accessible via familiar file system commands from any AWS compute instance, container, or function, will accelerate development in areas like agentic AI, advanced analytics, and hybrid cloud migrations. As organizations continue to generate and process ever-increasing volumes of data, S3 Files offers a robust, cost-effective, and flexible solution that positions Amazon S3 even more strongly as the undisputed foundation for cloud data strategies worldwide. The cloud community will undoubtedly be keen to explore the full potential of this new capability, leveraging it to build more agile, efficient, and scalable data architectures.