
Amazon Web Services (AWS) has announced the general availability of Amazon S3 Files, a groundbreaking new file system designed to seamlessly integrate AWS compute resources with Amazon Simple Storage Service (Amazon S3). This innovation marks a significant evolution in cloud storage, effectively blurring the long-standing architectural distinction between object storage and traditional file systems, a separation that has challenged cloud architects and developers for over a decade. By enabling high-performance, fully-featured file system access directly to data residing in S3 buckets, S3 Files promises to simplify cloud architectures, eliminate data silos, and unlock new possibilities for data-intensive applications, particularly in the burgeoning fields of artificial intelligence (AI) and machine learning (ML).
Historically, the cloud storage landscape has been characterized by a fundamental dichotomy between object storage and file systems. Object storage, exemplified by Amazon S3, offers unparalleled scalability, durability, and cost-effectiveness, ideal for vast quantities of unstructured data, backups, archives, and data lakes. However, its object-based nature means data is treated as immutable units, making it less suitable for workloads requiring granular, byte-range modifications or hierarchical directory structures and POSIX-compliant file operations. File systems, on the other hand, provide the familiar hierarchical structure, metadata, and interactive capabilities essential for traditional applications, operating systems, and shared storage environments. Cloud providers have offered various file system services, such as Amazon Elastic File System (EFS) and Amazon FSx, to meet these needs, but these typically involved moving or duplicating data from S3 or maintaining separate storage infrastructures. This often led to data synchronization complexities, increased operational overhead, and elevated costs for organizations needing to leverage both storage paradigms.
The launch of S3 Files directly addresses this challenge by transforming S3 into the first and only cloud object store that offers fully-featured, high-performance file system access to its data. This means that S3 buckets can now be mounted and accessed as native file systems by a wide array of AWS compute resources, including Amazon Elastic Compute Cloud (EC2) instances, containers running on Amazon Elastic Container Service (ECS) or Amazon Elastic Kubernetes Service (EKS), and even AWS Lambda functions. The implications are profound: organizations no longer have to choose between the robust cost, durability, and scalability benefits of Amazon S3 and the interactive, POSIX-compliant capabilities of a file system. S3 is elevated to a central hub for all organizational data, accessible directly via a familiar file system interface.

Technical Architecture and Performance Capabilities
Underpinning the robust performance of S3 Files is its intelligent architecture, which leverages Amazon Elastic File System (EFS) for its high-performance storage layer. This integration ensures that active data benefits from sub-millisecond latencies, typically around 1ms, crucial for interactive and latency-sensitive workloads. When data is accessed through the S3 Files file system, associated file metadata and contents are strategically placed onto this high-performance EFS-backed storage. This intelligent tiering ensures that frequently accessed or "hot" data remains readily available with minimal latency.
For files that do not require ultra-low latency access, such as those involved in large sequential reads, S3 Files intelligently serves this data directly from Amazon S3. This maximizes throughput for such operations, preventing unnecessary movement of vast datasets to the high-performance tier and optimizing costs. Furthermore, for byte-range reads—a common requirement in many data processing scenarios—only the specifically requested bytes are transferred, significantly minimizing data movement and associated data transfer costs. The system also incorporates intelligent pre-fetching capabilities, anticipating data access patterns to further enhance performance and responsiveness. Users retain fine-grained control over this optimization, allowing them to decide whether to load full file data or metadata only, tailoring the system to their specific application access patterns.
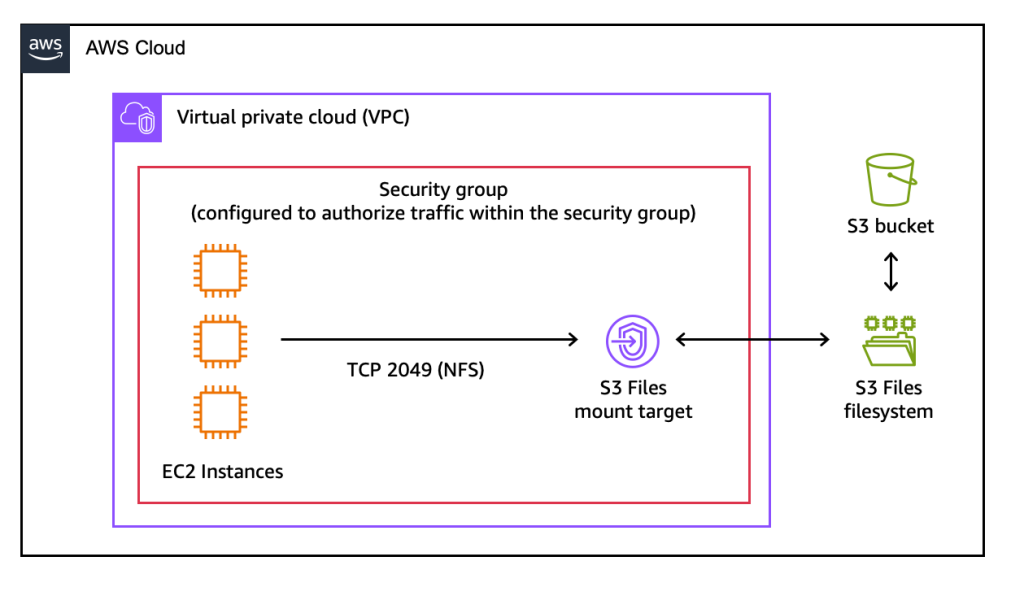
S3 Files supports all Network File System (NFS) v4.1+ operations, including creating, reading, updating, and deleting files and directories. This broad compatibility ensures that existing applications and tools that rely on POSIX file system semantics can now operate directly on S3 data without modification. The system also provides concurrent access from multiple compute resources, coupled with NFS close-to-open consistency. This consistency model is vital for collaborative and shared workloads where multiple agents or processes are simultaneously reading and writing to the same files, ensuring data integrity and predictable behavior across distributed environments.

Operational Simplicity and Synchronization
The operational aspect of S3 Files is designed for simplicity. Users can create an S3 file system directly from the AWS Management Console, the AWS Command Line Interface (CLI), or through infrastructure as code (IaC) tools. The process involves specifying an S3 bucket to be exposed as a file system, and AWS automatically provisions the necessary mount targets—network endpoints within the user’s Virtual Private Cloud (VPC)—to facilitate access from EC2 instances or other compute resources. Mounting the file system on an EC2 instance, for example, is as straightforward as executing a standard mount command.
A critical feature of S3 Files is its automatic synchronization mechanism. Changes made to files via the mounted file system are automatically reflected as new objects or new versions of existing objects in the underlying S3 bucket, typically within minutes. Conversely, changes or additions to objects directly within the S3 bucket are visible through the file system within seconds, though occasional updates might take up to a minute or longer. This near real-time, bi-directional synchronization ensures data consistency across both storage paradigms, eliminating the need for complex, manual synchronization scripts or third-party tools. This level of automation significantly reduces the operational burden on development and operations teams.
Diverse Use Cases and Industry Impact
The introduction of S3 Files is poised to revolutionize how various workloads interact with cloud data, particularly those requiring shared, interactive, and hierarchical access patterns.
- Agentic AI Systems: The rise of agentic AI, where autonomous AI agents collaborate and interact with tools and each other, often relies on file-based communication, Python libraries, and shell scripts. S3 Files provides these agents with direct, low-latency access to shared datasets and intermediate outputs stored in S3, enabling more complex and collaborative AI workflows without the overhead of data movement.
- Machine Learning (ML) Training Pipelines: ML model training often involves large datasets that need to be accessed, processed, and sometimes modified by multiple training instances or workers. S3 Files allows ML pipelines to treat S3 data as a local file system, simplifying data preparation, feature engineering, and model training processes. The ability to share data across compute clusters without duplication, combined with high-performance access to active data, can accelerate model development and deployment.
- Production Applications: Many legacy and modern production applications are designed to interact with file systems. S3 Files enables these applications to leverage the immense scalability and durability of S3 without requiring significant code refactoring or architectural changes. This facilitates easier migration of on-premises workloads to the cloud and allows existing applications to tap into vast S3-based data lakes.
- Media and Entertainment: For tasks like video editing, rendering, and content production, where multiple artists or systems need concurrent, high-speed access to large media files, S3 Files offers a compelling solution. It allows shared access to project files directly from S3, streamlining collaborative workflows and centralizing media assets.
- Scientific Research and HPC: Researchers often work with massive datasets that require high-performance computing clusters. S3 Files provides a unified access layer to these datasets, allowing scientific simulations and analyses to read and write directly to S3 with file system semantics, potentially simplifying data management for complex research projects.
Positioning within the AWS Storage Ecosystem
AWS maintains a comprehensive portfolio of storage services, each optimized for specific use cases. Understanding where S3 Files fits alongside existing services like Amazon EFS and Amazon FSx is crucial for architects.
- Amazon EFS: This service provides a simple, scalable, elastic NFS file system for use with AWS Cloud services and on-premises resources. EFS is ideal for general-purpose, POSIX-compliant file storage, especially for workloads that require shared access across multiple EC2 instances, containers, or serverless functions, and where data originates and primarily lives within the file system itself. S3 Files, while utilizing EFS under the hood for its high-performance layer, is specifically designed to provide file system access to data that originates and primarily resides in S3.
- Amazon FSx: This family of services offers fully managed third-party file systems for specific enterprise workloads. Amazon FSx for Lustre is optimized for high-performance computing (HPC) and GPU clusters, providing extremely high throughput and low latency for petabyte-scale workloads. Amazon FSx for NetApp ONTAP, OpenZFS, and Windows File Server cater to workloads requiring specific file system features, protocols, or compatibility with on-premises NAS environments. These services are often chosen for lift-and-shift migrations or highly specialized applications. S3 Files does not aim to replace FSx for these specialized needs but rather complements it by providing a direct file system interface to S3 for a broader range of interactive, shared, and collaborative workloads.
The key differentiator for S3 Files is its focus on S3 data. It allows organizations to keep their data in the highly durable, scalable, and cost-effective S3 object store while gaining the interactivity and shared access capabilities of a file system. This eliminates the "data gravity" problem often associated with specialized file systems, where data needs to be moved out of S3 into another storage service, creating copies and increasing management complexity.
Pricing and Availability
Amazon S3 Files is available today in all commercial AWS Regions, offering broad accessibility to AWS customers globally. The pricing model follows AWS’s typical "pay-as-you-go" approach, ensuring cost-effectiveness. Customers incur charges for the portion of data stored in their S3 file system (the high-performance EFS-backed layer), for small file read and all write operations to the file system, and for S3 requests generated during data synchronization between the file system and the S3 bucket. This granular pricing ensures that costs are directly tied to usage, encouraging efficient resource allocation and preventing over-provisioning. The detailed pricing structure is available on the Amazon S3 pricing page, allowing organizations to accurately estimate costs based on their anticipated workloads.
Broader Implications and Future Outlook
The launch of Amazon S3 Files represents a pivotal moment in cloud storage, addressing a long-standing architectural gap and further solidifying S3’s role as the foundational data layer for the AWS cloud. By enabling direct file system access to S3, AWS simplifies cloud architectures, reduces operational complexity, and eliminates the need for manual data movement or elaborate synchronization strategies between object and file storage.
Industry analysts predict that this innovation will accelerate the adoption of S3 for a wider range of workloads, especially those previously constrained by the lack of file system semantics. It democratizes access to S3’s vast benefits for traditional applications and new, dynamic AI/ML paradigms alike. This move also intensifies competition within the cloud storage market, pushing other providers to enhance their own object storage offerings with similar file system capabilities. While some providers offer FUSE-based solutions or specialized gateways, S3 Files offers a managed, high-performance integration directly within the AWS ecosystem.
Ultimately, S3 Files empowers organizations to build more agile, scalable, and cost-efficient cloud solutions. Whether it’s running production tools that inherently work with file systems, developing cutting-edge agentic AI systems that leverage file-based Python libraries, or preparing massive datasets for ML training, S3 Files ensures that these interactive, shared, and hierarchical workloads can access S3 data directly and efficiently. This marks a significant step towards a more unified and simplified data management experience in the cloud, solidifying Amazon S3’s position as the ubiquitous central hub for all enterprise data.
