
This counterintuitive outcome stems from a fundamental mismatch: as teams grow and AI-generated code increases, the critical human expertise required for code review does not scale proportionally. Measuring AI adoption solely by metrics like merge request (MR) volume, lines of code generated, or seat usage provides an incomplete picture, tracking only inputs rather than the true constraints on development velocity. The latest data from the 2025 DORA (DevOps Research and Assessment) program highlights this disconnect. Key delivery metrics such as lead time, deployment frequency, change failure rate, and mean time to recovery (MTTR) have shown no significant improvement despite the increased adoption of AI tools. Intriguingly, teams demonstrating the lowest rates of change failures are also the least likely to utilize AI-assisted development tools, according to recent analyses. This observation does not necessarily imply that AI tools are detrimental, but it serves as a crucial reminder against the assumption that a higher volume of MRs directly translates to enhanced productivity.
The Review Queue Becomes the Bottleneck
A recent engagement with a customer’s AI enablement engineering team, focused on scrutinizing their software delivery metrics, revealed this phenomenon starkly. While the rollout of their AI coding tool showed robust adoption across the board, a deeper segmentation of cycle time data by reviewer exposed a critical bottleneck. Engineers possessing the most comprehensive system knowledge found themselves overwhelmed with review requests. Their queues grew so large that code review effectively became their primary responsibility, significantly diminishing their capacity for higher-value activities like system design and architectural planning.
This pattern is not isolated; it appears to be a recurring challenge across multiple development teams. As MR volume escalates, the time required for thorough code reviews lengthens. Consequently, senior engineers, who are often the custodians of intricate system context, security-sensitive domains, and critical ownership boundaries, find their schedules consumed by review tasks. Mid-level engineers, lacking the deep system understanding, are unable to step in to review these complex and critical changes, creating a dependency on a small cadre of experienced personnel.
The primary consequence of this concentration of review workload is attention fragmentation. Senior engineers are subjected to frequent interruptions, inevitably leading to a decline in the quality of reviews. This can manifest as superficial approvals driven by the pressure to clear lengthy queues, or significant delays when complex merge requests languish, awaiting the scarce availability of a senior reviewer.
Beyond CI: The Cost of Human Judgment in Review
While automated checks, such as Continuous Integration (CI) pipelines, can efficiently handle a growing volume of code, the scalability of human judgment remains a significant constraint. Even when a pipeline indicates successful compilation and testing, human reviewers, particularly in regulated environments, must perform a deeper assessment. This involves understanding the underlying intent of the code, evaluating its potential impact on the system, verifying adherence to authorization boundaries, scrutinizing failure scenarios, and ensuring compliance with audit trails.
The proliferation of AI-generated code exacerbates this challenge. While the code may syntactically correct—compiling, passing unit tests, and adhering to linting standards—reviewers are still tasked with verifying its functional correctness and alignment with the system’s overall purpose. This includes ensuring proper data classification, adherence to security policies, and avoidance of unintended consequences. This verification process can often be more time-consuming when code is generated primarily for syntactic accuracy rather than for deep system-level intent. As review queues lengthen, the time allocated per MR inevitably shrinks, creating a dual pressure to expedite reviews while maintaining stringent quality standards.
Generation Scales, But Judgment Remains a Human Endeavor
It is important to acknowledge the tangible benefits that AI coding tools bring to the development process. They demonstrably accelerate code generation, facilitate rapid refactoring, and empower teams to tackle a greater number of features within a single sprint. This constitutes a significant and undeniable value proposition for development teams.
However, the capacity for effective code review is intrinsically linked to human cognitive abilities, specifically contextual understanding and personal accountability. When a senior engineer approves a change to a critical component, such as an identity service within a highly regulated industry, they assume a significant organizational risk. This inherent responsibility does not diminish, regardless of how rapidly the code was initially generated.
The notion of simply “adding AI code review” as a panacea is an oversimplification. Current AI-assisted review capabilities, while advancing rapidly, are not yet reliably capable of substituting the nuanced, contextual judgment that defines valuable senior-level review, particularly in high-risk code paths. In practice, accelerating code generation without a corresponding redesign of the review process will not resolve the underlying bottleneck.
Cases Where AI Review Truly Streamlined the Process
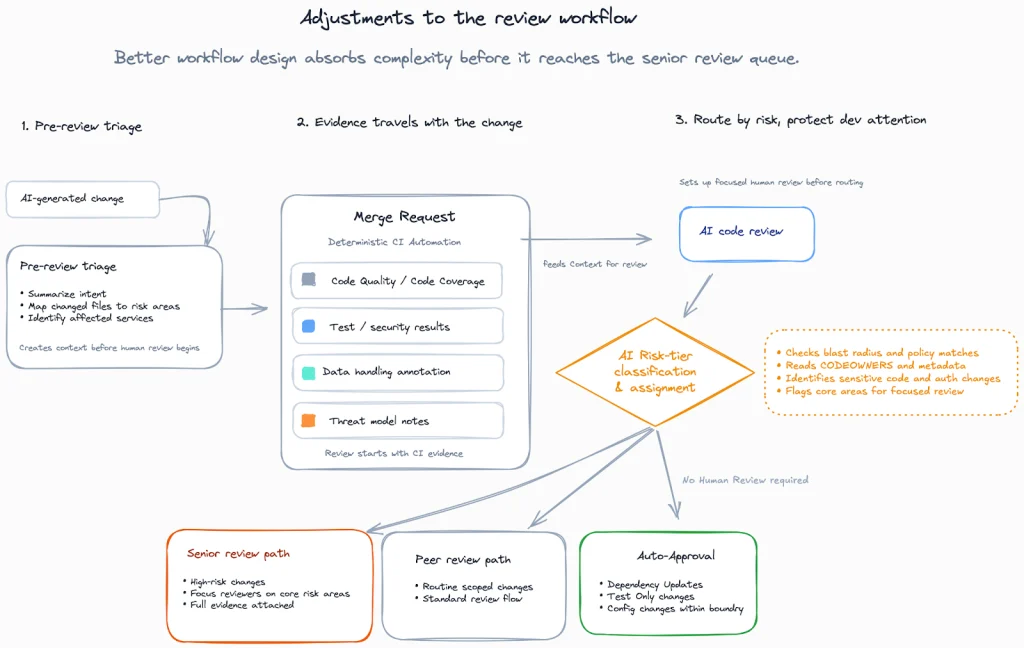
In certain instances, AI-assisted review has demonstrably reduced the burden on senior engineers. One notable example involved a team that had already established robust CI pipelines, clear code ownership models, standardized service templates, and well-defined review checklists. The introduction of AI tools here focused on pre-triage functions: summarizing the intent of changes, flagging modifications to policy-sensitive files, and identifying code diffs that matched known patterns. This allowed senior reviewers to concentrate their efforts on genuinely high-risk changes, thereby expediting cycle times without compromising defect rates.

Conversely, broad implementation of AI coding tools without accompanying workflow adjustments has led to negative outcomes. In one regulated company, the workload for senior reviewers surged dramatically after widespread AI adoption. Attempts to mitigate this by throttling code generation or mandating larger, fewer MRs inadvertently created larger batch sizes and more complex reviews. The truly effective solution in this scenario involved a fundamental redesign of the workflow. This included enforcing strict scope limitations for small diffs, requiring detailed author summaries and risk declarations, automating policy checks, and implementing a system of rotating trained “risk captains” to manage high-risk triage. The strategic goal was to ensure that most changes were low-risk by design, allowing experts to dedicate their attention to exceptions.
The critical takeaway from these contrasting experiences is that the tool itself was not the sole determinant of success. In the effective case, clear review standards and mature workflows, managed through principles of ownership, iteration, and feedback, were foundational. AI served to enhance these existing processes. In environments with less mature standards, AI-driven triage often introduces noise that reviewers learn to disregard, failing to deliver its intended benefit.
The Compounding Tax: Seams, Exceptions, and Ownership of Risk
The most challenging code reviews often revolve around policy adherence and the integrity of system boundaries. This includes areas like data classification, logging mechanisms, authorization protocols, and robust failure handling. At a global financial institution employing over 4,000 engineers across security, platform, and delivery teams, each group operated with its own distinct metrics. Security focused on reducing vulnerabilities, platform aimed to improve uptime, and engineering sought to accelerate deployments. However, the handoffs between these teams frequently introduced significant delays, and no single entity owned the full cycle time of a change.
The increased volume of AI-generated code can exacerbate this inter-team dynamic by generating more boundary-crossing changes, unless workflows are specifically designed to contain them. Even the adoption of smaller MRs as a best practice can hinder overall flow if each smaller change still necessitates cross-team reviews, security approvals, or extensive compliance documentation.
Measuring the Constraint, Not Just the Output
A critical oversight in many organizations is the failure to measure reviewer capacity directly. Without this crucial data, the impact of AI on development teams can be easily misinterpreted. Metrics that help distinguish genuine throughput from congestion include:
- Reviewer Queue Depth: The number of outstanding merge requests assigned to each reviewer.
- Average Review Time: The duration from when an MR is opened to when it is approved or rejected.
- Time Spent on Review vs. Development: The proportion of a senior engineer’s time dedicated to reviews versus new feature development or architectural design.
- Defect Escape Rate: The number of bugs found in production that should have been caught during the review process.
The distribution of these metrics is often more telling than simple averages. A small number of overloaded senior engineers can become a significant bottleneck, delaying critical system updates even if overall team metrics appear healthy. The true indicator of success is not merely an increase in opened MRs, but rather the ability of senior engineers to reclaim time for design and architectural work while maintaining or improving code quality.
Structuring for Scale Through Workflow Design
The optimal approach is not to prohibit AI tools or to blindly approve all AI-generated code. Instead, the focus must be on introducing structure that prevents the increased volume of AI-generated code from disproportionately escalating the cognitive load on senior engineers. A potential framework for achieving this could involve:
- Automated Policy Checks: Implementing automated checks for compliance with security policies, data classification rules, and logging standards.
- Intelligent Triage: Utilizing AI to categorize MRs by risk level, flagging those that require deeper human scrutiny.
- Contextual Review Prompts: Providing reviewers with AI-generated summaries of the code’s intent and potential impact to expedite understanding.
- Specialized Reviewer Pools: Establishing dedicated teams or individuals for reviewing high-risk or specialized code areas, such as security or compliance.
- Clear Ownership and Escalation Paths: Defining explicit ownership for different code modules and establishing clear escalation procedures for complex or contentious reviews.
- Feedback Loops: Continuously analyzing review data to refine AI models and workflow processes.
The Decision Rule for Expanding AI Usage
A practical leadership test for determining the appropriate expansion of AI usage is to ask: following AI adoption, did the time-in-review for high-risk changes decrease, or did the workload disproportionately concentrate among fewer senior reviewers? If the latter scenario is true, it indicates that code generation is outpacing the available review capacity.
Senior review attention should be treated as a governed resource, subject to explicit limits, defined routing rules, and established escalation procedures. AI-assisted code generation should only be expanded to new repositories or teams when reviewer workload and defect escape rates remain within acceptable parameters.
A critical weekly practice for engineering leadership should be to ask: "Who are the two individuals currently limiting the merging of high-risk changes, and what is the current depth of their review queue?" If this question cannot be answered, it signifies a lack of visibility into the system’s constraints. If the number of such individuals or their queue depths consistently grows week over week, this represents the “hidden tax” that AI adoption can impose when not managed effectively.