
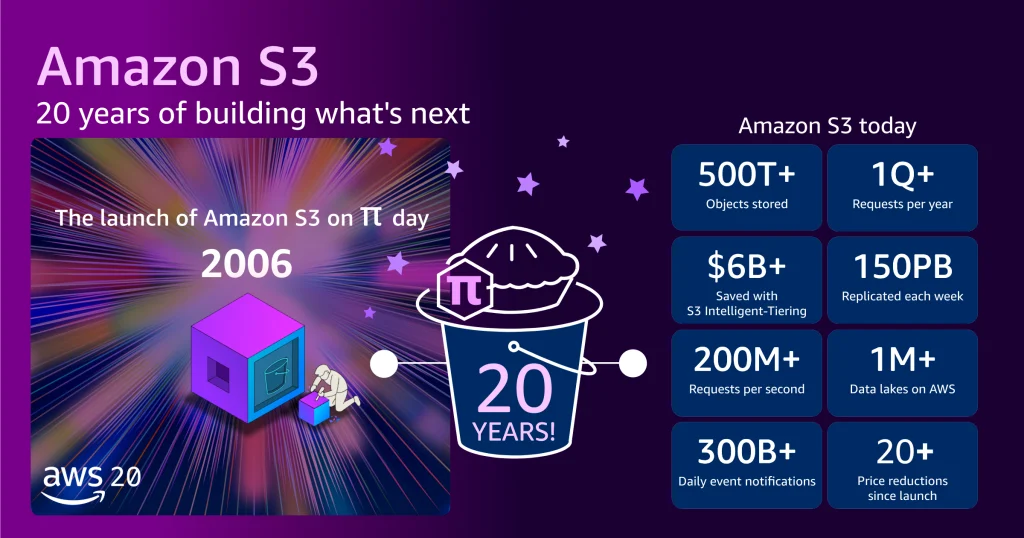
On March 14, 2026, Amazon Simple Storage Service (Amazon S3) commemorates its twentieth anniversary, a milestone marking two decades since its quiet debut fundamentally reshaped the landscape of data storage and cloud computing. Launched with a modest one-paragraph announcement on the AWS What’s New page in 2006, S3 introduced a paradigm shift, democratizing access to scalable, reliable, and cost-effective storage for developers worldwide. What began as a simple web service to store and retrieve data has evolved into a global infrastructure giant, underpinning countless applications, data lakes, and AI workloads, with a scale that was once unimaginable.
The Genesis of a Revolution: From Humble Beginnings to Cloud Foundation
The year 2006 was a nascent period for cloud computing. Before S3, data storage was predominantly an on-premises challenge, characterized by significant capital expenditure, complex hardware management, and the perpetual struggle of scaling. Businesses invested heavily in Storage Area Networks (SANs), Network Attached Storage (NAS), and direct-attached storage, requiring dedicated teams for provisioning, maintenance, and disaster recovery. This created a high barrier to entry for startups and imposed substantial operational overhead on established enterprises.
It was against this backdrop that Amazon Web Services (AWS) began to offer its internal infrastructure capabilities as services to the public. Amazon S3, along with Amazon Elastic Compute Cloud (EC2) which followed later that year, represented the very first public offerings of what would become the world’s leading cloud platform. The initial announcement for S3, succinct and understated, described it as "storage for the Internet," designed to "make web-scale computing easier for developers." It promised a "simple web services interface" to "store and retrieve any amount of data, at any time, from anywhere on the web," offering developers access to the "same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of web sites."
Jeff Barr’s accompanying blog post, penned hastily before a flight to a developer event, further underscored the low-key launch. There were no grand ceremonies, no elaborate demos, nor any immediate recognition of the profound impact S3 would have. Yet, this unassuming debut introduced two powerful primitives—PUT to store an object and GET to retrieve it—and a philosophy that would define cloud services: abstracting away the "undifferentiated heavy lifting" of infrastructure management, thereby liberating developers to innovate at higher levels of the application stack.
Foundational Principles: The Pillars of Unwavering Reliability
From its inception, S3 was engineered around five core fundamentals that have remained steadfast for two decades, serving as the bedrock for its unprecedented growth and reliability:
- Security: Data protection by default has always been paramount. S3 offers robust access control mechanisms, encryption options (in transit and at rest), and integration with other AWS security services, ensuring that data stored within its boundaries is safeguarded against unauthorized access.
- Durability: Designed for "11 nines" (99.999999999%) of durability, S3 is engineered to be lossless. This extraordinary level of durability means that for every 10 million objects stored, one would statistically expect to lose only one object once every 10,000,000 years. This is achieved through automatic replication across multiple devices and Availability Zones within an AWS Region, continuous data integrity checks, and self-healing mechanisms that proactively detect and repair any signs of data degradation.
- Availability: Built on the assumption that failure is an inherent part of any large-scale distributed system, S3’s architecture incorporates redundancy at every layer. Data is distributed across multiple, isolated Availability Zones within a region, ensuring that even in the event of a significant outage in one zone, data remains accessible and operations continue uninterrupted.
- Performance: S3 is optimized to handle virtually any amount of data without degradation in performance. Its massively parallel architecture can scale to millions of requests per second, supporting diverse workloads from high-throughput data ingestion to low-latency content delivery.
- Elasticity: The system automatically scales up and down as data is added or removed, requiring no manual intervention from users. This inherent elasticity eliminates the need for capacity planning, allowing developers to consume exactly the storage they need, when they need it, without worrying about provisioning or over-provisioning.
These principles, meticulously implemented and continuously refined, have made S3 a service that, for most users, simply "just works," obscuring the immense complexity of its underlying engineering.
Two Decades of Unprecedented Growth and Scale
The journey from its humble beginnings to its current colossal scale is a testament to S3’s robust design and relentless innovation.
- Initial Capacity (2006): S3 launched with approximately one petabyte (PB) of total storage capacity, distributed across roughly 400 storage nodes in 15 racks spanning three data centers. It was designed to store tens of billions of objects, with a maximum object size of 5 gigabytes (GB). The initial pricing stood at 15 cents per gigabyte per month.
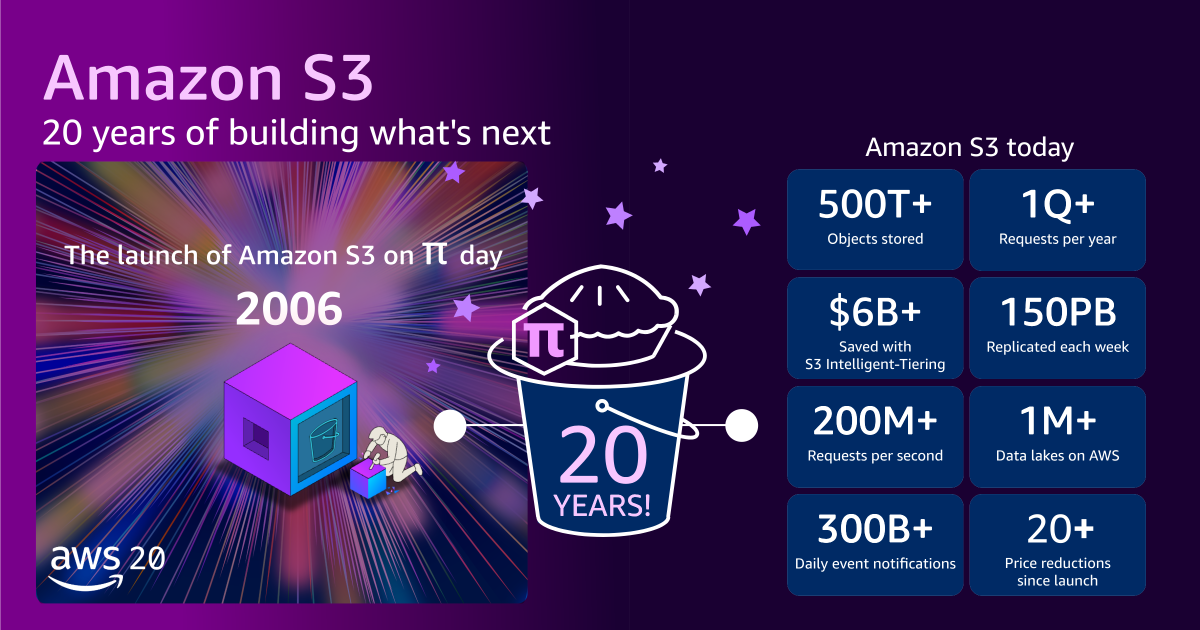
- Current Scale (2026): Today, two decades later, S3 stores over 500 trillion objects—a staggering 500,000-fold increase in object count capacity—and serves more than 200 million requests per second globally. This vast ocean of data, spanning hundreds of exabytes (EB), is housed across 123 Availability Zones in 39 AWS Regions, serving millions of customers across every conceivable industry. The maximum object size has expanded exponentially from 5 GB to 50 terabytes (TB), representing a 10,000-fold increase, accommodating massive datasets required for modern analytics and AI. To put its physical footprint into perspective, if all the tens of millions of hard drives comprising S3 were stacked, they would reach the International Space Station and almost back.
Alongside this monumental growth in scale and capability, the cost of S3 storage has plummeted. From the initial 15 cents per gigabyte, AWS now charges slightly over 2 cents per gigabyte for standard storage—an approximate 85% price reduction since launch. Furthermore, AWS has introduced a spectrum of storage classes, such as Amazon S3 Intelligent-Tiering, which automatically moves data to the most cost-effective tier based on access patterns. This innovation alone has saved customers collectively more than $6 billion in storage costs compared to using standard S3.
The S3 API has also transcended its origins, becoming a de facto industry standard. Numerous vendors and open-source projects now offer S3-compatible storage tools and systems, implementing the same API patterns and conventions. This widespread adoption means that skills and tools developed for S3 are highly transferable, fostering a more accessible and interoperable storage landscape across the entire technology ecosystem.
Perhaps the most remarkable achievement in S3’s two-decade history is its unwavering commitment to backward compatibility. Code written to interact with S3 in 2006 still functions seamlessly today, without modification. While the underlying infrastructure has undergone countless generations of upgrades, including migrations across different disk types and storage systems, and the entire request handling code has been rewritten multiple times, the data stored twenty years ago remains accessible, a testament to AWS’s dedication to a "just works" service experience.
Engineering Excellence: The Unseen Innovation Powering Scale
Achieving and sustaining S3’s scale and reliability demands continuous, cutting-edge engineering innovation. Insights into this complex machinery were recently shared in an in-depth interview between Mai-Lan Tomsen Bukovec, VP of Data and Analytics at AWS, and Gergely Orosz of The Pragmatic Engineer, revealing some of the sophisticated techniques employed.
At the heart of S3’s vaunted durability lies a highly distributed system of microservices. These "auditor services" perpetually inspect every single byte across the entire fleet of storage devices. The moment any signs of degradation are detected, these services automatically trigger repair mechanisms, ensuring data integrity and preventing data loss. This proactive, self-healing architecture is crucial for maintaining the "lossless" design goal, where the 11 nines durability reflects the meticulous sizing of replication factors and the re-replication fleet.
S3 engineers employ rigorous formal methods and automated reasoning in production environments to mathematically prove the correctness of critical system components. For instance, when new code is introduced to the index subsystem, automated proofs verify that consistency properties have not regressed. This same approach is used to ensure the correctness of complex features like cross-Region replication and intricate access policies, guaranteeing predictable and reliable behavior at scale.
Over the past eight years, AWS has embarked on a progressive rewrite of performance-critical code in the S3 request path using Rust. Components responsible for blob movement and disk storage have already been re-engineered in Rust, with ongoing efforts across other parts of the system. Beyond raw performance gains, Rust’s strong type system and memory safety guarantees eliminate entire classes of bugs at compile time, a critical advantage when operating a system with S3’s scale and correctness requirements.
A guiding principle for S3’s architectural design is "Scale is to your advantage." Engineers intentionally design systems such that increased scale inherently improves attributes for all users. For S3, this means that as the service grows larger, workloads become increasingly de-correlated, leading to enhanced overall reliability for every customer. The sheer volume of diverse operations helps smooth out individual anomalies, making the system more resilient.
Looking Ahead: The Universal Data Foundation for AI
The vision for Amazon S3 extends far beyond its role as a premier object storage service. AWS envisions S3 as the universal foundation for all data and artificial intelligence (AI) workloads. This forward-looking strategy is built on a simple premise: customers should be able to store any type of data once in S3 and work with it directly, without the need to move it between specialized systems. This approach significantly reduces costs, eliminates operational complexity, and removes the necessity for maintaining multiple copies of the same data across different platforms.
Recent innovations highlight this trajectory, transforming S3 into a powerful hub for analytics and AI:
- S3 Object Lambda: This capability allows developers to add their own code to process data as it is being retrieved from S3. This enables use cases like redacting sensitive information, converting data formats on the fly, or resizing images, without changing the original object or requiring additional infrastructure.
- Amazon S3 Storage Lens: A comprehensive analytics and visibility tool that provides organization-wide insights into S3 storage usage and activity. It helps customers understand, analyze, and optimize their storage costs and performance across thousands of accounts and buckets.
- Amazon S3 Access Points: Simplifying data access for applications at scale by providing unique hostnames and access policies for each application, improving manageability and security for large datasets.
- Strong Read-After-Write Consistency: A significant enhancement introduced in 2020, guaranteeing that after a successful write of an object, all subsequent read requests will immediately return the latest version of the object. This simplifies application development by removing the need to manage eventual consistency.
- S3 Intelligent-Tiering: Continuously optimizes storage costs by automatically moving objects between four access tiers when access patterns change, without performance impact or operational overhead.
- S3 Glacier Deep Archive: Offering the lowest-cost storage in the cloud, suitable for long-term data archival that is accessed rarely, further expanding S3’s capabilities for cost-effective data retention.
Each of these capabilities operates within the economic framework of S3, making it feasible to handle diverse data types and complex processing tasks that traditionally demanded expensive databases or specialized systems. This integration of processing directly at the storage layer is pivotal for the future of data-intensive applications and the burgeoning field of AI.
From a single petabyte to hundreds of exabytes, from 15 cents to 2 cents per gigabyte, and from simple object storage to the foundational layer for AI and advanced analytics, Amazon S3’s journey has been one of continuous transformation. Yet, through all these revolutionary changes, its five core fundamentals—security, durability, availability, performance, and elasticity—have remained immutable, ensuring that the code written for S3 in 2006 continues to function seamlessly today. As Amazon S3 enters its third decade, its legacy as a cornerstone of cloud computing is firmly established, and its future as the universal data foundation for an AI-driven world appears brighter than ever.