
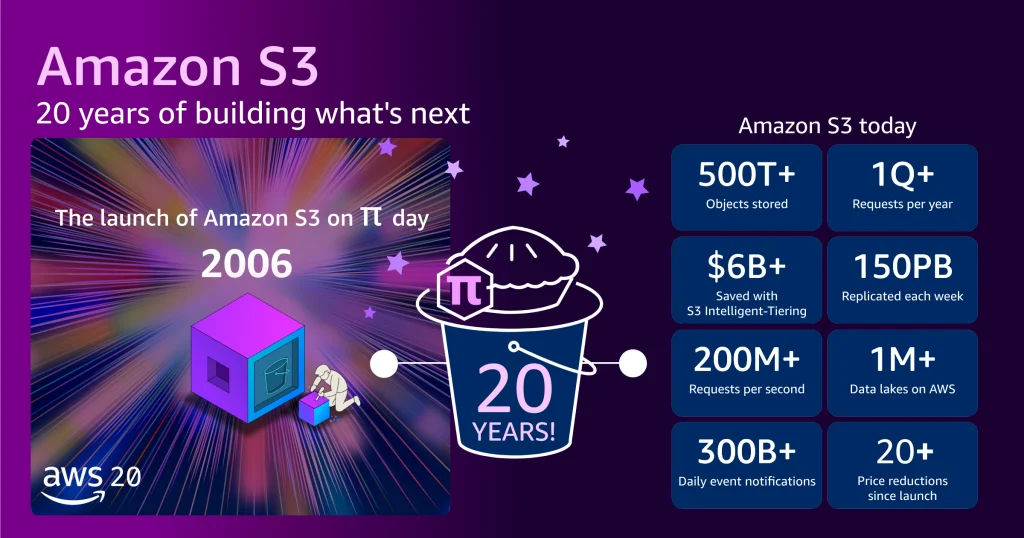
March 14, 2006, marked a seemingly unassuming date in the annals of technology, as Amazon Simple Storage Service (Amazon S3) made its debut with a modest, one-paragraph announcement on the AWS What’s New page. Titled "Announcing Amazon S3 – Simple Storage Service," the initial communiqué described it as "storage for the Internet," designed to simplify web-scale computing for developers by offering "a simple web services interface" to store and retrieve data "at any time, from anywhere on the web." This quiet launch, accompanied by a brief blog post from AWS evangelist Jeff Barr, provided little indication of the profound impact it would have, not only on Amazon’s burgeoning cloud division but on the entire digital landscape. Nobody could have predicted that this foundational service would underpin a vast portion of the internet, democratize access to scalable infrastructure, and ultimately become a cornerstone for the age of artificial intelligence and big data.
The Genesis of a Giant: A Look Back at 2006
Before S3, the concept of "cloud storage" as a utility was largely nascent. Businesses and developers were typically tethered to managing their own physical storage infrastructure—procuring hard drives, configuring RAID arrays, dealing with backups, and wrestling with the complexities of scaling data centers. This "undifferentiated heavy lifting" consumed valuable resources and stifled innovation, particularly for startups and small-to-medium enterprises that lacked the capital or expertise for extensive IT investments. Amazon, itself a pioneer in large-scale internet operations, recognized this universal pain point. Its internal need for scalable, reliable storage for its own e-commerce platform provided the crucible for S3’s development.
The initial offering was starkly simple, presenting just two core primitives: PUT to store an object and GET to retrieve it. This simplicity, however, masked a revolutionary philosophy: abstract away the hardware and infrastructure complexities, allowing developers to focus solely on their applications and data. The promise was access to "the same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of web sites." At its launch, S3 offered approximately one petabyte (PB) of total storage capacity, spread across roughly 400 storage nodes in 15 racks within three data centers, with a total bandwidth of 15 gigabits per second (Gbps). It was designed to store tens of billions of objects, each with a maximum size of 5 gigabytes (GB), and priced at 15 cents per gigabyte per month. These figures, while impressive for the time, pale in comparison to S3’s current scale, underscoring the exponential growth witnessed over two decades.
Foundational Principles: The Pillars of S3’s Success
From its inception, S3 was engineered around five immutable fundamentals that have guided its development and remain core to its operation today:
- Security: Data protection is paramount. S3 was designed to ensure data is protected by default, offering robust access controls, encryption options, and integration with AWS Identity and Access Management (IAM) to safeguard customer information.
- Durability: The service is designed for 11 nines of durability (99.999999999%). This extraordinary figure translates to an average annual expected loss of 0.000000001% of objects, meaning that if you stored 10 million objects, you might expect to lose one object every 10,000 years. This is achieved through automatic replication across multiple devices within a minimum of three Availability Zones (AZs) in an AWS Region, combined with continuous data integrity checks and self-healing mechanisms.
- Availability: Designed into every layer, S3 operates on the fundamental assumption that failures are inevitable and must be gracefully handled. Its distributed architecture ensures that data remains accessible even in the event of hardware failures or localized outages.
- Performance: S3 is optimized to handle virtually any amount of data and any number of requests without degradation. Its highly parallel and distributed design allows for consistent high-throughput and low-latency access, crucial for modern applications.
- Elasticity: The system automatically scales to accommodate growing data volumes and request loads without manual intervention. Developers no longer need to provision storage in advance, as S3 seamlessly expands and contracts with their needs.
These principles, often taken for granted today, were revolutionary in 2006. They enabled developers to build applications with unprecedented confidence in their underlying storage infrastructure, freeing them to innovate at higher levels of the application stack. As AWS Vice President of Data and Analytics, Mai-Lan Tomsen Bukovec, often emphasizes, the goal was to make the service "so straightforward that most of you never have to think about how complex these concepts are."
From Petabytes to Exabytes: S3’s Unprecedented Growth
The journey from a few petabytes to hundreds of exabytes illustrates S3’s staggering growth. Today, S3 stores more than 500 trillion objects and serves over 200 million requests per second globally. This data resides across hundreds of exabytes of storage, distributed across 123 Availability Zones in 39 AWS Regions, serving millions of customers worldwide. The maximum object size has expanded from 5 GB to a colossal 50 terabytes (TB), a 10,000-fold increase that accommodates massive datasets for everything from scientific research to media archives. To put this physical scale into perspective, if one were to stack all the tens of millions of hard drives comprising S3’s infrastructure, they would reportedly reach the International Space Station and almost back.
This incredible expansion has been coupled with a relentless commitment to cost reduction. The initial price of 15 cents per gigabyte has plummeted by approximately 85% since launch, with AWS now charging slightly over 2 cents per gigabyte for standard storage. Furthermore, AWS has introduced a variety of storage classes, such as S3 Standard-Infrequent Access (S3 Standard-IA), S3 One Zone-Infrequent Access (S3 One Zone-IA), S3 Glacier, and S3 Glacier Deep Archive, tailored for different access patterns and cost efficiencies. A standout innovation, Amazon S3 Intelligent-Tiering, automatically moves data between different access tiers based on usage patterns, allowing customers to optimize storage spend without manual intervention. This feature alone has saved customers collectively more than $6 billion in storage costs compared to using S3 Standard storage.
A Standard Bearer: S3’s Industry-Wide Influence
Beyond its internal growth, S3’s most significant external impact might be its role in shaping the broader storage industry. The S3 API has become a de facto standard, adopted and referenced by countless vendors across the storage landscape. This widespread adoption means that skills and tools developed for S3 are often transferable to other storage systems, fostering a more accessible and interoperable ecosystem. The consistent API ensures that applications built to interact with S3 can often communicate with S3-compatible storage solutions, promoting portability and reducing vendor lock-in concerns.
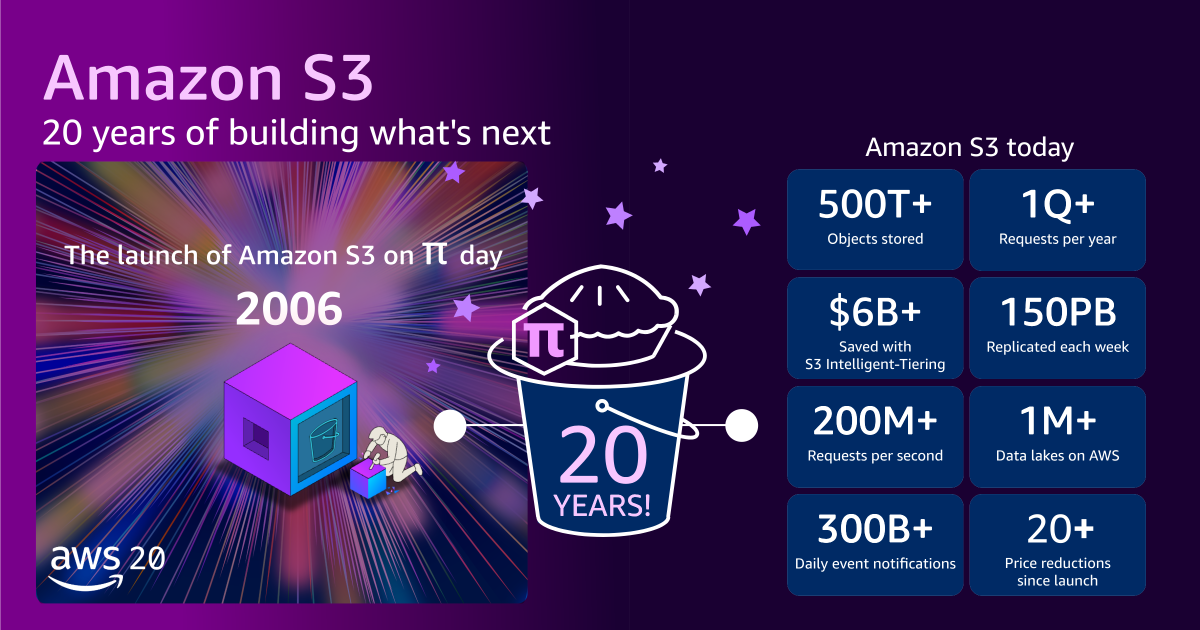
Perhaps the most remarkable testament to S3’s engineering prowess is its unwavering commitment to backward compatibility. Code written for S3 in 2006 continues to function seamlessly today, without modification. This means that data stored two decades ago remains accessible and usable, despite countless internal migrations through multiple generations of disks and storage systems, and complete rewrites of the underlying request-handling code. This dedication to "just works" functionality provides immense stability and confidence for enterprises building long-term data strategies on AWS. It underscores a philosophy that prioritizes developer experience and long-term utility over short-term architectural shifts.
The Engineering Marvel: Behind S3’s Scale and Reliability
Achieving and maintaining S3’s unparalleled scale and reliability is a continuous feat of engineering. Insights from AWS executives, such as Mai-Lan Tomsen Bukovec, often highlight the sophisticated systems at play.
At the heart of S3’s renowned 11 nines of durability is a complex system of microservices dedicated to continuous data inspection. These "auditor" services meticulously examine every byte across the entire fleet, constantly checking for signs of data degradation or corruption. Upon detection, they automatically trigger repair systems, ensuring that data integrity is maintained and objects are not lost. This proactive, self-healing architecture is crucial for operating a lossless storage system at such a massive scale.
S3 engineers also employ cutting-edge techniques like formal methods and automated reasoning in production environments. These mathematical proof systems verify the correctness of critical components, such as the index subsystem, ensuring that consistency is never compromised when new code is introduced. This rigorous approach extends to complex functionalities like cross-Region replication and access policies, providing mathematical guarantees for their behavior and security.
A significant engineering evolution over the past eight years has been the progressive rewriting of performance-critical code in the S3 request path using Rust. Components responsible for blob movement and disk storage have been re-engineered in Rust, with ongoing work across other elements. Beyond raw performance gains, Rust’s robust type system and memory safety guarantees eliminate entire classes of bugs at compile time. This is an invaluable property for a service operating at S3’s scale and with its stringent correctness requirements, significantly enhancing system stability and reducing the likelihood of runtime errors.
Underpinning these technical innovations is a core design philosophy: "Scale is to your advantage." AWS engineers consciously design systems where increased scale inherently improves attributes for all users. In S3, the larger the system grows, the more de-correlated workloads become, which paradoxically enhances overall reliability and performance for every customer. This principle contrasts with traditional systems where scale often introduces complexity and potential points of failure.
Beyond Storage: S3 as the Data and AI Foundation
Looking ahead, the vision for S3 transcends mere object storage. It is rapidly evolving into a universal foundation for all data and artificial intelligence (AI) workloads. The strategic imperative is simple: customers should store any type of data once in S3 and work with it directly, eliminating the need to move data between specialized, often expensive, systems. This approach significantly reduces costs, streamlines complexity, and eradicates the proliferation of multiple copies of the same data across an organization.
Recent years have seen a surge of innovations that cement S3’s role in this broader data ecosystem:
- S3 Object Lambda: This capability allows developers to add their own code to process data as it is retrieved from S3, enabling dynamic transformations, redactions, and content enrichment without modifying the original objects.
- S3 Access Points: Simplifying access management for shared datasets, S3 Access Points allow creation of hundreds or thousands of unique access points with distinct permissions and network controls, enhancing data governance at scale.
- S3 Batch Operations: This feature enables large-scale batch operations on billions of objects, such as copying, tagging, or restoring from Glacier, streamlining data management tasks.
- Integration with AWS Data Lakes and Analytics Services: S3 serves as the foundational storage layer for AWS data lake solutions (e.g., AWS Lake Formation) and integrates seamlessly with analytics services like Amazon Athena, Amazon Redshift Spectrum, and Amazon EMR, allowing direct queries on data stored in S3.
- Machine Learning Integration: S3 is the primary repository for training data and model artifacts for AWS machine learning services like Amazon SageMaker, positioning it as a crucial component in the AI/ML pipeline.
Each of these capabilities operates within the cost structure and scalability of S3, making it economically feasible to handle diverse data types and complex workloads that traditionally demanded expensive databases or highly specialized systems.
From its humble beginnings storing 1 petabyte at 15 cents per gigabyte to managing hundreds of exabytes at 2 cents per gigabyte, and from simple object storage to the indispensable foundation for AI and advanced analytics, Amazon S3’s journey over two decades is a testament to continuous innovation. Through it all, the five foundational principles—security, durability, availability, performance, and elasticity—have remained steadfast, ensuring that the code developers wrote in 2006 still reliably works today. As AWS looks towards the next 20 years, S3 is poised to continue its quiet revolution, shaping the future of cloud computing and data-driven innovation.