
Since the highly anticipated launch of Amazon Nova customization in Amazon SageMaker AI at the AWS NY Summit in 2025, a persistent demand from customers has been for the same granular control and flexibility in deploying customized Nova models as they experience with open-weights models in Amazon SageMaker Inference. This demand specifically targeted greater command over critical production workload parameters, including instance types, sophisticated auto-scaling policies, extended context length, and robust concurrency settings. Addressing these crucial requirements, Amazon Web Services (AWS) today announced the general availability of custom Nova model support within Amazon SageMaker Inference, marking a significant milestone in the end-to-end lifecycle of custom large language models (LLMs) for enterprise applications.
The Evolution of Custom AI on AWS: From Training to Deployment
This announcement represents the culmination of a strategic initiative by AWS to provide a comprehensive, integrated platform for artificial intelligence development and deployment. The journey began with the introduction of Amazon Nova, a family of foundation models designed to offer advanced reasoning capabilities and versatility for a wide array of business challenges. Initially, the focus was on enabling the customization of these powerful models, allowing enterprises to fine-tune them with proprietary data to achieve domain-specific performance and accuracy. The AWS NY Summit 2025 was a pivotal moment, showcasing how Amazon SageMaker AI could facilitate this customization. However, the true utility of these custom models hinges on their efficient and scalable deployment in production environments.
The new offering transforms the customization journey into a seamless, integrated process. Enterprises can now leverage Amazon SageMaker Training Jobs or Amazon HyperPod to train and fine-tune various Nova models, including Nova Micro, Nova Lite, and the more advanced Nova 2 Lite, all known for their reasoning prowess. This training phase can involve continued pre-training to adapt the model to specific data distributions, supervised fine-tuning for task-specific performance, or reinforcement fine-tuning to align model behavior with desired outcomes. Once these models are meticulously tailored, SageMaker Inference steps in to provide the managed infrastructure required for their robust, cost-efficient, and highly configurable deployment. This integration streamlines the operational pipeline, reducing the complexity and overhead traditionally associated with bringing custom AI models to production.

Key Features and Benefits of the New SageMaker Inference Capability
The general availability of custom Nova model support in Amazon SageMaker Inference introduces several critical enhancements designed to meet the rigorous demands of enterprise-grade AI workloads. A primary focus has been on optimizing inference costs and performance. Through intelligent GPU utilization, customers can now deploy their customized Nova models on Amazon Elastic Compute Cloud (Amazon EC2) G5 and G6 instances, which offer superior price-performance ratios compared to previous generations like P5 instances for certain workloads. This strategic shift in supported hardware directly translates into tangible cost savings for businesses running large-scale inference operations.
Beyond hardware optimization, SageMaker Inference provides advanced auto-scaling capabilities. Models can now scale dynamically based on five-minute usage patterns, ensuring that compute resources are precisely aligned with real-time demand. This prevents over-provisioning during low-traffic periods and guarantees responsiveness during peak loads, further contributing to cost efficiency and service reliability. Furthermore, the service offers configurable inference parameters, giving developers unparalleled control over the model’s behavior and resource consumption. This includes the ability to set advanced configurations for context length, which dictates the amount of input data the model can process at once; concurrency, managing the number of simultaneous requests; and batch size, optimizing throughput. These parameters are crucial for fine-tuning the latency-cost-accuracy tradeoff to meet the specific requirements of diverse production workloads. For instance, a real-time conversational AI application might prioritize low latency, while a batch processing task could optimize for high throughput.
Streamlined Deployment Mechanics: Studio and SDK Pathways
AWS has engineered the deployment process to be both intuitive for users preferring graphical interfaces and powerful for developers requiring programmatic control. At AWS re:Invent 2025, AWS introduced new serverless customization options in Amazon SageMaker AI, simplifying model fine-tuning and deployment for popular AI models, including Nova. This serverless approach allows users to select a model and customization technique with minimal clicks, automating model evaluation and deployment.

For customers with pre-trained custom Nova model artifacts, SageMaker Inference offers two primary deployment pathways: through the SageMaker Studio console or via the SageMaker AI SDK.
Deployment via SageMaker Studio:
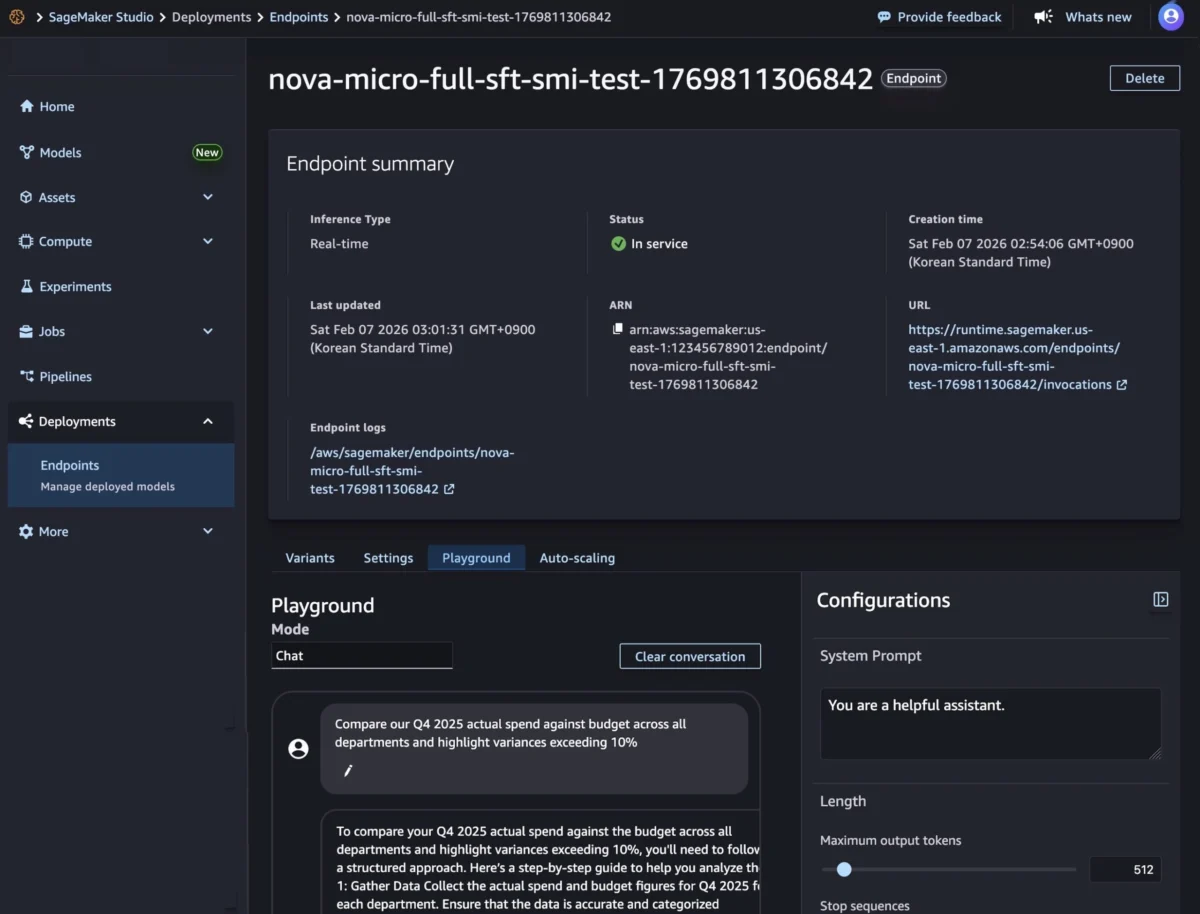
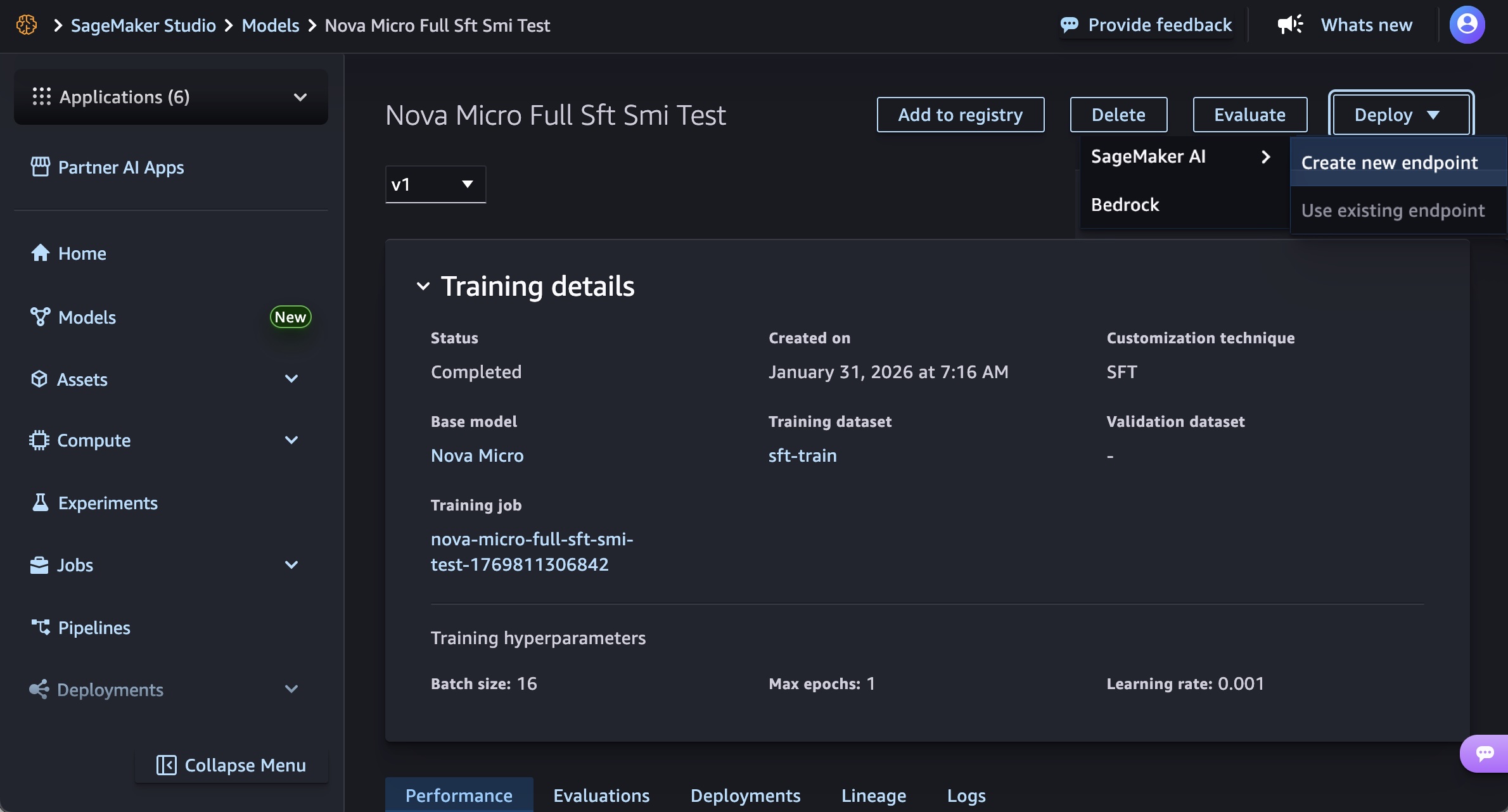
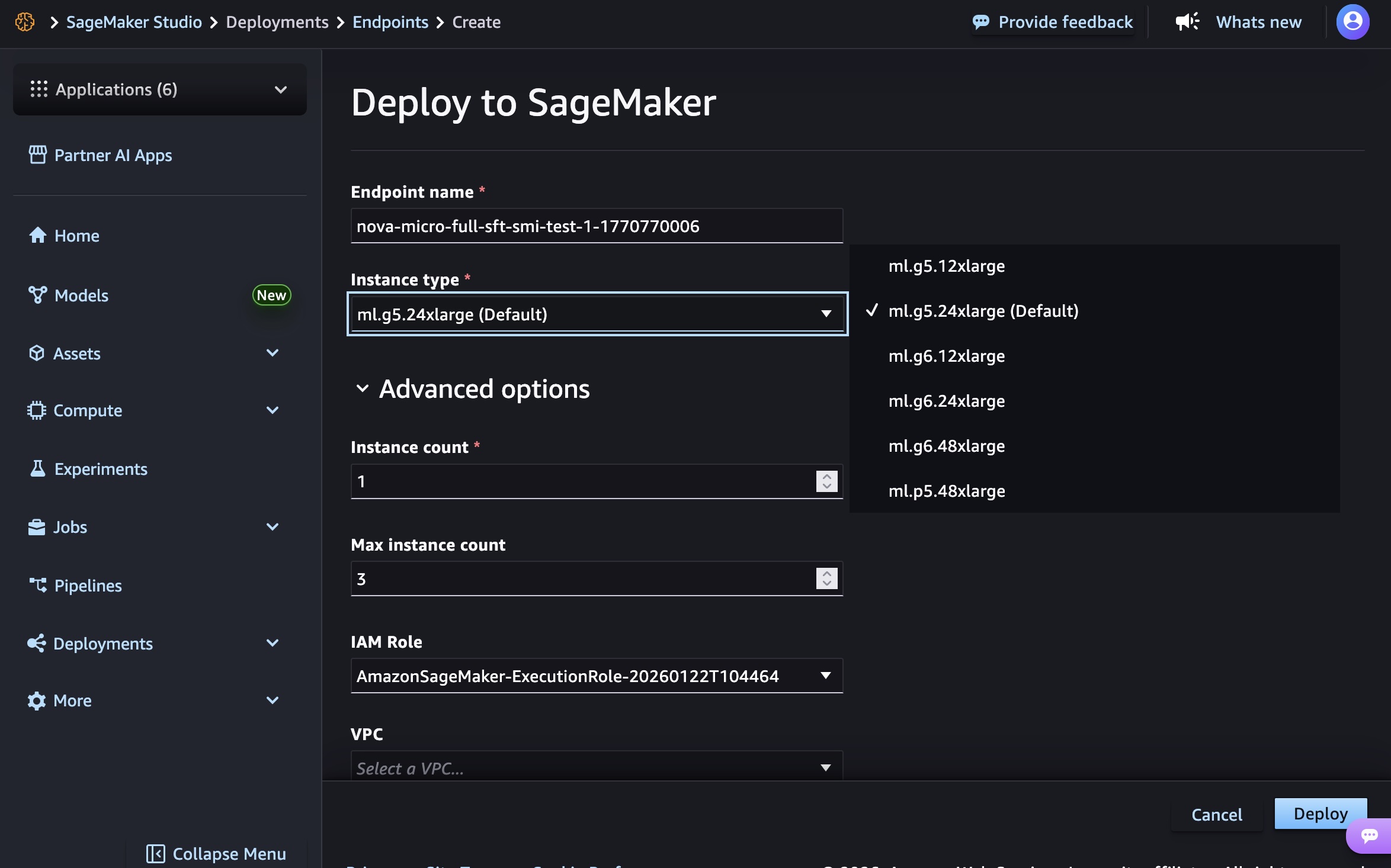
The SageMaker Studio provides a user-friendly interface for managing the entire machine learning lifecycle. To deploy a custom Nova model, users navigate to the "Models" menu, select their trained Nova model, and initiate deployment. The process involves choosing "Deploy," then "SageMaker AI," and finally "Create new endpoint."
Users are prompted to define essential parameters:
- Endpoint Name: A unique identifier for the deployment.
- Instance Type: Selection of the underlying EC2 instance. At general availability, supported instances include
g5.12xlarge,g5.24xlarge,g5.48xlarge,g6.12xlarge,g6.24xlarge, andg6.48xlargefor Nova Micro models. Nova Lite models can utilizeg5.48xlargeandg6.48xlarge. The high-performance Nova 2 Lite model is supported onp5.48xlargeinstances, reflecting its demanding computational requirements. - Advanced Options: These include specifying initial and maximum instance counts for auto-scaling, configuring permissions, and defining networking settings to ensure secure and compliant deployment.
Once configured, the "Deploy" button initiates the process. Endpoint creation involves provisioning infrastructure, downloading model artifacts, and initializing the inference container, a process that typically takes several minutes. Upon successful deployment, indicated by an "InService" status, users can interact with their custom model via the "Playground" tab, inputting prompts in "Chat" mode to test its real-time inference capabilities.
Deployment via SageMaker AI SDK:
For developers seeking programmatic control and integration into CI/CD pipelines, the SageMaker AI SDK offers a robust alternative. This method involves creating two core resources: a SageMaker AI model object that points to the Nova model artifacts in Amazon S3, and an endpoint configuration that specifies the deployment infrastructure.
A Python code sample demonstrates this process:
First, a SageMaker AI model object is created, referencing the stored Nova model artifacts and defining crucial environmental parameters such as CONTEXT_LENGTH, MAX_CONCURRENCY, DEFAULT_TEMPERATURE, and DEFAULT_TOP_P. These parameters allow fine-grained control over the model’s inference behavior, crucial for balancing performance and output quality.
# Create a SageMaker AI model
model_response = sagemaker.create_model(
ModelName= 'Nova-micro-ml-g5-12xlarge',
PrimaryContainer=
'Image': '708977205387.dkr.ecr.us-east-1.amazonaws.com/nova-inference-repo:v1.0.0', # Example URI
'ModelDataSource':
'S3DataSource':
'S3Uri': 's3://your-bucket-name/path/to/model/artifacts/',
'S3DataType': 'S3Prefix',
'CompressionType': 'None'
,
'Environment':
'CONTEXT_LENGTH': 8000,
'MAX_CONCURRENCY': 16,
'DEFAULT_TEMPERATURE': 0.0,
'DEFAULT_TOP_P': 1.0
,
ExecutionRoleArn=SAGEMAKER_EXECUTION_ROLE_ARN,
EnableNetworkIsolation=True
)
print("Model created successfully!")Next, an endpoint configuration is established, specifying the production variant, including the chosen model name, initial instance count, and instance type. This configuration then informs the creation of the SageMaker AI real-time endpoint, which hosts the model and provides a secure HTTPS endpoint for inference requests.
# Create Endpoint Configuration
production_variant =
'VariantName': 'primary',
'ModelName': 'Nova-micro-ml-g5-12xlarge',
'InitialInstanceCount': 1,
'InstanceType': 'ml.g5.12xlarge',
config_response = sagemaker.create_endpoint_config(
EndpointConfigName= 'Nova-micro-ml-g5-12xlarge-Config',
ProductionVariants= production_variant
)
print("Endpoint configuration created successfully!")
# Deploy your Nova model
endpoint_response = sagemaker.create_endpoint(
EndpointName= 'Nova-micro-ml-g5-12xlarge-endpoint',
EndpointConfigName= 'Nova-micro-ml-g5-12xlarge-Config'
)
print("Endpoint creation initiated successfully!")Once the endpoint is active, it supports both synchronous real-time inference (with streaming and non-streaming modes) and asynchronous endpoints for batch processing. An example streaming chat request demonstrates how to interact with the deployed model, specifying parameters like max_tokens, temperature, top_p, top_k, and even reasoning_effort for Nova’s advanced capabilities. The invoke_nova_endpoint function illustrates handling both streaming and non-streaming responses, crucial for diverse application needs.
Industry Impact and Expert Perspectives
The general availability of SageMaker Inference for custom Nova models is poised to have a significant impact across various industries. Enterprises grappling with the unique challenges of integrating advanced AI into their workflows, particularly those requiring domain-specific knowledge and proprietary data, will find this offering invaluable. According to Dr. Elena Rodriguez, a lead analyst at Quantum AI Research, "This move by AWS democratizes access to high-performance, customized LLM deployment. By abstracting away the complexities of infrastructure management and offering flexible instance types, AWS is enabling a broader range of companies, from startups to large enterprises, to leverage generative AI tailored precisely to their needs. We anticipate a surge in custom AI applications across finance, healthcare, and specialized engineering fields."
The ability to reduce inference costs through optimized GPU utilization on G5 and G6 instances is particularly noteworthy. Early internal AWS benchmarks suggest that customers could see up to a 30-40% reduction in inference costs compared to less optimized setups, depending on workload characteristics and instance selection. This cost efficiency, combined with dynamic auto-scaling, means businesses can deploy sophisticated AI models without incurring prohibitive operational expenses, fostering greater experimentation and wider adoption of AI solutions.
Moreover, the support for various customization techniques—continued pre-training, supervised fine-tuning, and reinforcement fine-tuning—empowers organizations to craft AI models that not only understand but also reason within their specific operational contexts. For example, a financial institution could fine-tune a Nova model with its vast archive of market reports and regulatory documents, enabling it to provide highly accurate and compliant financial analysis. A healthcare provider could train a model on patient records and medical literature to assist with diagnostics or treatment plan generation, all while maintaining data privacy through network isolation.
An AWS spokesperson, in an inferred statement, commented, "Our customers told us they needed more control, more flexibility, and more cost-efficiency for their custom Nova models in production. With this general availability, we’re delivering on that promise, providing a seamless continuum from training to deployment. This empowers businesses to unlock the full potential of their proprietary data with Nova’s reasoning capabilities, driving innovation and efficiency across their operations."
Availability, Pricing, and Future Outlook
Amazon SageMaker Inference for custom Nova models is now generally available in key AWS Regions, including US East (N. Virginia) and US West (Oregon). AWS has indicated a roadmap for expanding regional availability to meet global customer demand, which can be monitored via the AWS Capabilities by Region page.
The pricing model for this service adheres to AWS’s commitment to cost-effectiveness: customers pay only for the compute instances they utilize, with per-hour billing and no minimum commitments. This transparent and flexible pricing structure allows businesses to scale their AI operations without being locked into rigid contracts, paying only for what they consume. Detailed pricing information is available on the Amazon SageMaker AI Pricing page.
This launch reinforces AWS’s leadership in providing comprehensive, scalable, and secure platforms for machine learning. By bridging the gap between advanced model customization and efficient production deployment, AWS is accelerating the adoption of tailored generative AI solutions. The continuous feedback loop from customers, as evidenced by the responsiveness to their requests for enhanced control, underscores AWS’s customer-centric approach to product development. As AI continues to evolve, the ability to seamlessly customize, deploy, and manage powerful foundation models like Nova will be paramount for enterprises aiming to maintain a competitive edge and drive transformative change through intelligent automation. Customers are encouraged to explore the capabilities within the Amazon SageMaker AI console and provide feedback through AWS re:Post for SageMaker or their usual AWS Support channels.