
Since the initial announcement of Amazon Nova customization capabilities within Amazon SageMaker AI at the AWS NY Summit 2025, enterprises have increasingly sought robust, production-grade solutions for deploying their fine-tuned foundational models. This demand for greater control and flexibility in managing custom model inference – specifically regarding instance types, auto-scaling policies, context length, and concurrency settings – has been a critical driver for advancements in AWS’s machine learning offerings. Today marks a significant milestone with the general availability of custom Nova model support in Amazon SageMaker Inference, providing a managed, configurable, and cost-efficient service designed to deploy and scale full-rank customized Nova models seamlessly.
This new capability completes an end-to-end customization journey for organizations leveraging Amazon Nova. Customers can now train Nova Micro, Nova Lite, and Nova 2 Lite models, known for their advanced reasoning capabilities, using familiar tools such as Amazon SageMaker Training Jobs or the high-performance Amazon HyperPod. Following successful training, these specialized models can be effortlessly deployed with the robust, managed inference infrastructure provided by Amazon SageMaker AI. This integration streamlines the entire machine learning lifecycle, from data preparation and model training to deployment and continuous optimization, directly addressing the complexities of bringing advanced AI to production.
The Evolving Landscape of Enterprise AI and the Need for Customization
The rapid evolution of large language models (LLMs) has transformed the technological landscape, offering unprecedented capabilities in natural language understanding and generation. However, for enterprises, off-the-shelf foundational models often fall short of meeting specific business needs, particularly when dealing with proprietary data, industry-specific jargon, or highly specialized tasks. This gap has fueled a growing imperative for model customization, allowing businesses to fine-tune pre-trained models on their unique datasets, thereby enhancing accuracy, relevance, and performance for their distinct use cases.
Amazon Nova represents AWS’s family of foundational models, designed to provide powerful reasoning capabilities. While general-purpose LLMs are valuable, the real competitive advantage for businesses often lies in tailoring these models to their specific operational contexts. Customization techniques, including continued pre-training, supervised fine-tuning (SFT), and reinforcement fine-tuning (RFT), allow models to learn from domain-specific data, adapt to particular tasks, and align with desired behavioral outputs. Continued pre-training extends a model’s knowledge base with new data, SFT refines its responses based on labeled examples, and RFT uses human feedback or reward signals to optimize behavior, making the model more useful and reliable for specific applications.

Deploying these customized LLMs in production environments presents its own set of challenges, primarily related to cost, scalability, latency, and operational overhead. Managing the underlying infrastructure, optimizing GPU utilization, and dynamically scaling resources to meet fluctuating demand can be complex and expensive. Amazon SageMaker, a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy machine learning models quickly, aims to abstract away these complexities, allowing organizations to focus on innovation rather than infrastructure management.
A Chronology of Innovation: Nova’s Journey on SageMaker
The path to today’s general availability has been marked by several strategic announcements, demonstrating AWS’s methodical approach to empowering enterprise AI adoption:
- AWS NY Summit 2025: Initial Customization for Nova: The journey began with the introduction of Amazon Nova customization in Amazon SageMaker AI. This initial phase primarily focused on enabling customers to fine-tune Nova models, recognizing the critical need for domain-specific adaptations. This laid the groundwork for enterprises to begin specializing Nova’s powerful capabilities with their proprietary data.
- AWS re:Invent 2025: Serverless Customization for Broader Access: Building on the initial offering, AWS re:Invent 2025 saw the launch of new serverless customization options within Amazon SageMaker AI. This innovation simplified the fine-tuning process for popular AI models, including Nova, making it accessible with just a few clicks. Serverless customization streamlined model selection, technique application, evaluation, and deployment, significantly lowering the barrier to entry for businesses looking to leverage specialized AI.
- Today’s Announcement: General Availability of Custom Nova Model Inference: The current announcement completes the end-to-end lifecycle. By making custom Nova models generally available on Amazon SageMaker Inference, AWS now offers a comprehensive platform where models can be trained, fine-tuned, and then deployed at scale with granular control over infrastructure and performance parameters. This ensures that the efforts invested in customization can be fully realized in production environments.
This phased rollout underscores AWS’s commitment to delivering a robust, integrated, and user-friendly platform for the entire machine learning workflow, particularly for advanced foundational models like Nova.
Key Capabilities and Technical Advantages
Amazon SageMaker Inference for custom Nova models offers a suite of features designed to optimize performance, cost, and operational efficiency for production workloads:

-
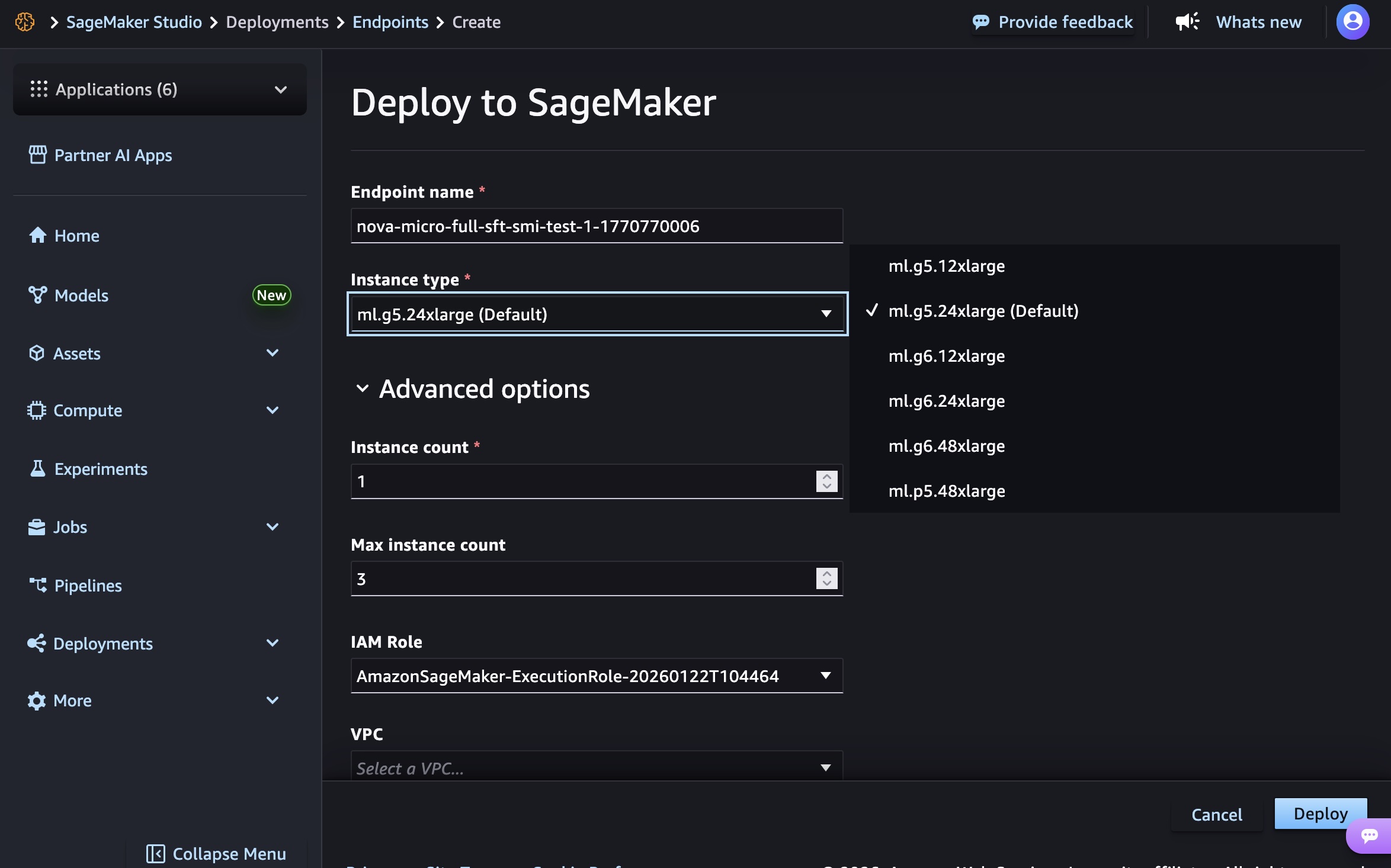
Cost Efficiency through Optimized GPU Utilization: A major advantage is the ability to reduce inference costs significantly. The service now supports Amazon Elastic Compute Cloud (Amazon EC2) G5 and G6 instances, which are often more cost-effective for inference workloads compared to P5 instances. While P5 instances (powered by NVIDIA H100 GPUs) excel in training large models due to their massive computational power, G5 instances (featuring NVIDIA A10G GPUs) and G6 instances (featuring NVIDIA H100 GPUs, often configured for inference workloads) offer an optimal balance of performance and cost efficiency for serving inference requests. This allows customers to select the right compute for the right task, minimizing expenditure without compromising on performance. For Nova Micro models, customers can choose from
g5.12xlarge,g5.24xlarge,g5.48xlarge,g6.12xlarge,g6.24xlarge,g6.48xlarge, andp5.48xlarge. Nova Lite models are supported ong5.48xlarge,g6.48xlarge, andp5.48xlarge, while Nova 2 Lite exclusively usesp5.48xlargefor its advanced capabilities. -
Flexible Deployment and Auto-Scaling: Production workloads for AI models can be highly variable, with peak demand periods interspersed with lower usage. SageMaker Inference addresses this with robust auto-scaling policies based on 5-minute usage patterns. This dynamic scaling ensures that resources are automatically adjusted up or down to match real-time demand, preventing over-provisioning (and thus reducing idle costs) during low-traffic periods and ensuring responsiveness during high-traffic spikes. This flexibility is crucial for maintaining service level agreements (SLAs) and managing operational budgets effectively.
-
Granular Control Over Inference Parameters: Optimizing the latency-cost-accuracy tradeoff is paramount for successful AI deployments. SageMaker Inference provides advanced configurations that allow users to fine-tune critical inference parameters:
- Context Length: This determines the maximum input size the model can process. Optimizing this parameter can balance the model’s ability to understand complex queries with the computational resources required.
- Concurrency: Managing the number of simultaneous requests an instance can handle directly impacts throughput and latency. Users can set maximum concurrency to ensure optimal performance without overloading instances.
- Batch Size: Grouping multiple inference requests into a single batch can significantly improve GPU utilization and throughput. Configurable batch sizes allow users to find the sweet spot for their specific workload patterns.
- Generation Parameters: Parameters like
temperature,top_p,top_k, andreasoning_effortprovide control over the model’s output style and determinism.Temperatureinfluences the randomness of responses,top_pandtop_kcontrol the diversity of generated tokens, andreasoning_effort(with options like "low" or "high" for Nova models) allows users to balance response speed with the depth of analysis.
-
Support for Advanced Fine-tuning Techniques: The feature enables the deployment of customized Nova models that have undergone continued pre-training, supervised fine-tuning, or reinforcement fine-tuning. This broad support ensures that enterprises can leverage the most appropriate customization technique for their specific use cases, whether it’s adapting to new data, refining output styles, or aligning with complex behavioral objectives.
Streamlined Deployment Pathways
AWS provides multiple avenues for deploying custom Nova models, catering to different user preferences and operational scales:
-
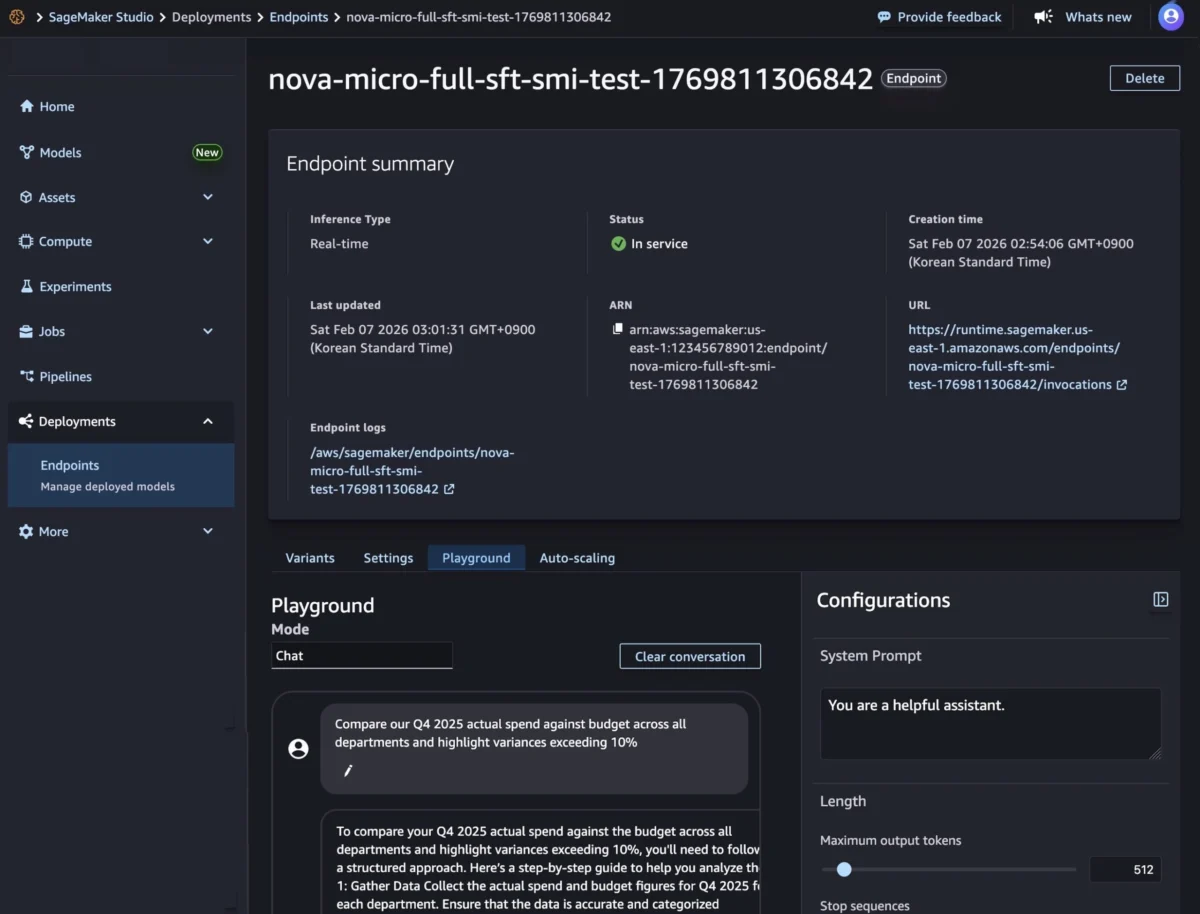
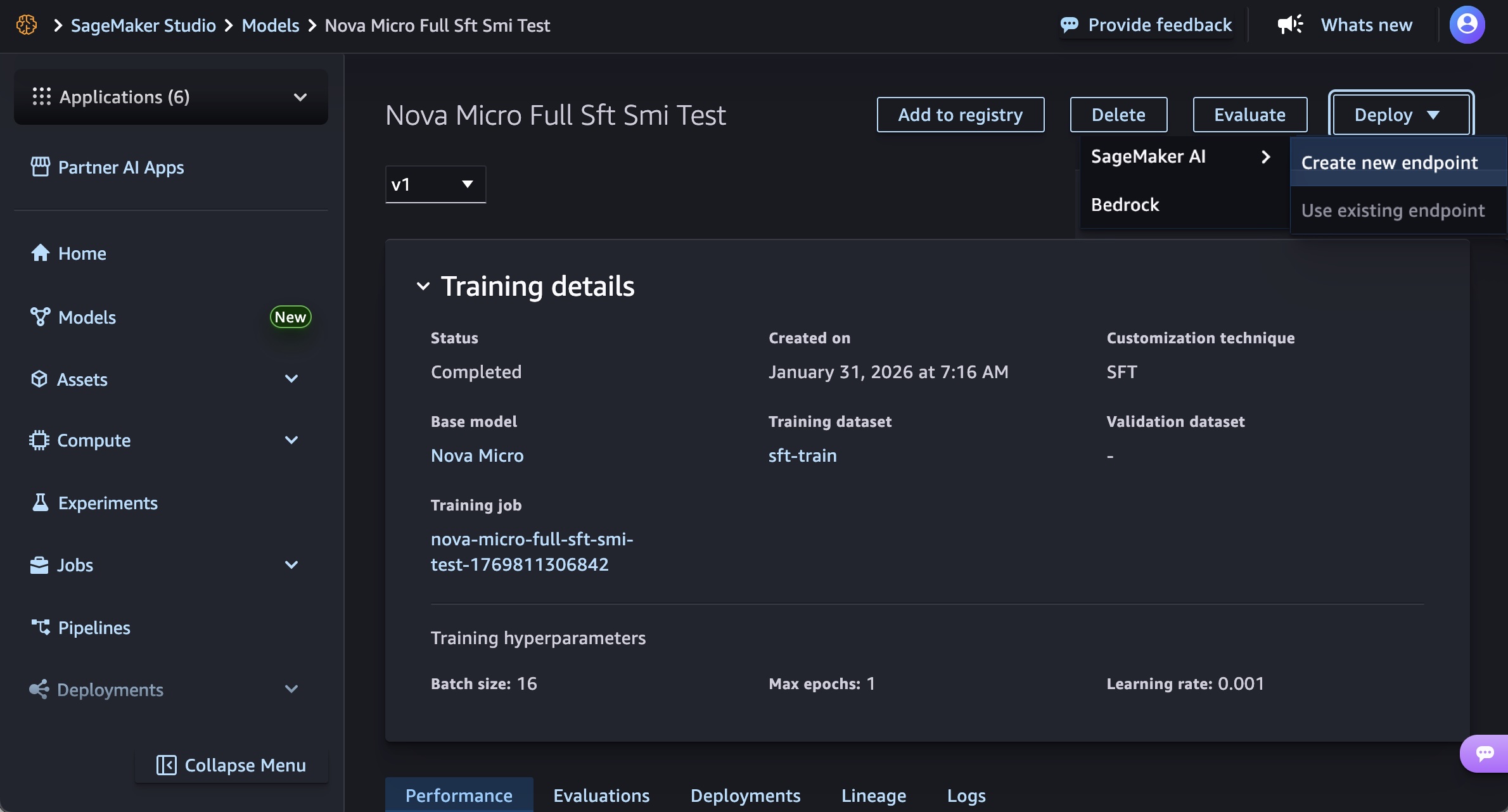
SageMaker Studio for a Low-Code Experience: For users who prefer a graphical interface, SageMaker Studio offers a highly intuitive experience. Following training, a customized Nova model artifact can be selected from the "Models" menu. With a few clicks, users can initiate deployment by choosing "Deploy," then "SageMaker AI," and "Create new endpoint." This process allows for configuring essential parameters such as endpoint name, instance type, and advanced options like instance count, max instance count, permissions, and networking settings, before clicking "Deploy." The Studio streamlines the provisioning of infrastructure, model artifact download, and inference container initialization. Once the endpoint status shows "InService," real-time inference can be performed directly through the "Playground" tab in Chat mode, allowing for immediate testing and interaction.
-
SageMaker AI SDK for Programmatic Control: Developers and MLOps teams often require programmatic control for automation, integration into CI/CD pipelines, and advanced configurations. The SageMaker AI SDK facilitates this by allowing users to create a SageMaker AI model object referencing their Nova model artifacts and an endpoint configuration that defines the deployment infrastructure.
The SDK enables granular control over environment variables for model parameters likeCONTEXT_LENGTH,MAX_CONCURRENCY,DEFAULT_TEMPERATURE, andDEFAULT_TOP_Pdirectly within the model creation process. Following model creation, an endpoint configuration is defined, specifying the production variant, instance type (e.g.,ml.g5.12xlarge), and initial instance count. Finally, a SageMaker AI real-time endpoint is created, hosting the model and providing a secure HTTPS endpoint for inference requests. The SDK supports both synchronous endpoints for real-time streaming/non-streaming modes and asynchronous endpoints for batch processing, offering flexibility for various application requirements. An example inference request demonstrating streaming completion format for text generation, including parameters likemax_tokens,temperature,top_p,top_k, andreasoning_effort, showcases the depth of control available.
Industry Impact and Strategic Implications
The general availability of custom Nova model support in Amazon SageMaker Inference carries significant implications for the broader enterprise AI landscape:
-
Democratizing Specialized AI: By simplifying the deployment of customized foundational models, AWS is further democratizing access to advanced AI capabilities. Companies of all sizes, even those without extensive MLOps expertise, can now leverage highly specialized LLMs tailored to their unique business needs. This accelerates the adoption of AI across various industries, from finance and healthcare to manufacturing and legal services, enabling them to build more intelligent applications and services.
-
Driving Cost-Effectiveness and Efficiency: The focus on optimized GPU utilization with G5 and G6 instances, coupled with intelligent auto-scaling, addresses one of the most critical challenges in LLM deployment: cost. By making inference more affordable and efficient, AWS encourages wider experimentation and sustained use of custom AI models, making advanced AI economically viable for a broader range of production workloads. This is crucial for achieving a positive return on investment from AI initiatives.
-
Strengthening AWS’s AI Ecosystem: This announcement solidifies Amazon SageMaker’s position as a leading platform for the entire machine learning lifecycle, from research and development to production deployment. By providing a comprehensive and integrated solution for AWS’s proprietary Nova models, AWS reinforces its competitive edge against other cloud providers and specialized AI platforms. It positions SageMaker as the go-to service for enterprises seeking a robust, scalable, and secure environment for their custom AI endeavors.
-
Empowering Developers and Businesses: The combination of intuitive Studio deployment and powerful SDK options empowers both citizen data scientists and experienced MLOps engineers. This flexibility ensures that organizations can choose the deployment method that best fits their team’s skills and operational requirements, fostering innovation and accelerating time-to-market for AI-powered solutions. The ability to fine-tune and deploy models with reasoning capabilities opens new possibilities for sophisticated applications, such as enhanced financial analysis, personalized healthcare diagnostics, or advanced legal document review.
Availability and Pricing
Amazon SageMaker Inference for custom Nova models is currently available in the US East (N. Virginia) and US West (Oregon) AWS Regions. AWS has indicated a future roadmap for broader regional availability, which customers can monitor through the AWS Capabilities by Region page.
The feature supports Nova Micro, Nova Lite, and Nova 2 Lite models, running on EC2 G5, G6, and P5 instances with auto-scaling support. The pricing model remains consistent with AWS’s commitment to flexibility: customers pay only for the compute instances they use, with per-hour billing and no minimum commitments. This pay-as-you-go approach allows businesses to scale their AI inference capabilities elastically without incurring prohibitive upfront costs. Detailed pricing information is available on the Amazon SageMaker AI Pricing page.
This general availability represents a significant step forward for enterprises seeking to harness the full power of customized foundational models. By providing a managed, flexible, and cost-efficient inference service, AWS continues to lower the barriers to AI adoption, enabling organizations to build, deploy, and scale intelligent applications that drive innovation and competitive advantage. Customers are encouraged to explore these new capabilities within the Amazon SageMaker AI console and provide feedback through AWS re:Post for SageMaker or their usual AWS Support contacts.