
Amazon Web Services (AWS) has announced the general availability of managed daemon support for Amazon Elastic Container Service (Amazon ECS) Managed Instances, a significant enhancement designed to empower platform engineers with independent control over essential operational software agents. This new capability builds upon the Amazon ECS Managed Instances experience first introduced in September 2025, addressing a critical pain point in large-scale container deployments by decoupling the lifecycle management of agents such as monitoring, logging, and tracing tools from application development cycles. The innovation promises to improve reliability, ensure consistent agent deployment across instances, and enable comprehensive host-level monitoring without requiring coordination with application development teams.
Background and Context: The Evolution of Container Management Challenges
The journey of modern application development has seen a rapid acceleration towards containerization and microservices architectures. Technologies like Docker and orchestration platforms such as Kubernetes and Amazon ECS have become foundational to how organizations build, deploy, and scale their applications. This paradigm shift, while offering unprecedented agility and scalability, has simultaneously introduced new layers of operational complexity, particularly for platform engineering teams tasked with maintaining the underlying infrastructure and ensuring the robust health of applications.
Prior to this announcement, managing operational agents in a containerized environment, especially at scale, presented a formidable challenge. In traditional setups, monitoring agents, logging collectors, and tracing tools were often tightly coupled with application deployments. This meant that any update to an operational agent—whether for security patches, feature enhancements, or performance optimizations—necessitated a coordinated effort with application development teams. The typical workflow involved modifying application task definitions, rebuilding container images, and then redeploying entire applications. For organizations managing hundreds or even thousands of microservices, this process translated into a significant operational burden, consuming valuable engineering time, increasing the risk of deployment errors, and potentially introducing application downtime. The inherent interdependencies also slowed down the pace of innovation, as infrastructure improvements were often gated by application release cycles.
The introduction of Amazon ECS Managed Instances in September 2025 marked a step forward by simplifying the management of ECS clusters, particularly concerning instance provisioning and lifecycle. However, the operational agent dilemma persisted. Platform teams still sought a more granular, independent control mechanism for these critical infrastructure components that underpin application observability and security. The industry trend towards "platform engineering" underscores this need, as organizations increasingly establish dedicated teams whose mandate is to provide self-service, robust, and reliable infrastructure platforms for application developers. These teams require tools that allow them to manage the operational fabric without directly interfering with application logic or deployment schedules.
Addressing the Core Pain Point: Decoupled Daemon Lifecycle Management
The newly introduced managed daemon support directly tackles this challenge by establishing a dedicated construct within Amazon ECS for operational tooling. This fundamental separation of concerns is a game-changer for platform engineers. They can now independently deploy and update essential agents—such as the Amazon CloudWatch Agent, security scanners, or custom logging forwarders—to their infrastructure. This capability enforces the consistent use of required tools across all container instances without imposing the burden of redeploying application services on development teams.
The mechanism ensures that daemons are guaranteed to start before any application tasks are launched on an instance. Conversely, during instance draining or updates, daemons are the last to be shut down. This "start before stop" approach guarantees continuous data collection for logging, tracing, and monitoring, eliminating critical gaps in observability that could otherwise arise during infrastructure changes. Such guarantees are paramount for maintaining the integrity of operational data, which is vital for troubleshooting, performance analysis, and security auditing.
Ensuring Reliability and Consistency Across Scale
Reliability and consistency are cornerstones of large-scale cloud operations, and managed daemons are engineered to bolster both. By abstracting the deployment and lifecycle management of these agents, ECS ensures that every instance within a specified capacity provider consistently runs the required daemons. This removes the manual effort and potential for human error associated with ensuring agent presence, especially in dynamic environments where instances are frequently scaled up or down.
Platform engineers gain granular control over where daemons are deployed. They can choose to deploy managed daemons across multiple capacity providers or target specific ones, offering flexibility to roll out agents incrementally or to specific environments (e.g., staging vs. production, or different compliance zones). This flexibility supports sophisticated deployment strategies and allows for A/B testing of agent configurations or phased rollouts without impacting the entire fleet.
Streamlined Resource Allocation and Configuration
Resource management for daemons also becomes significantly more efficient and centralized. Platform teams can define CPU and memory parameters for daemon tasks entirely separately from application configurations. This eliminates the need to rebuild Amazon Machine Images (AMIs) with pre-baked agents or to update application task definitions simply to adjust an agent’s resource footprint. This independent resource allocation leads to optimized resource utilization across the cluster. Since each instance runs exactly one daemon copy that is shared across multiple application tasks residing on that instance, there’s no wasteful duplication of agent processes, contributing to lower operational costs and better performance.
For instance, an organization might standardize on a specific CloudWatch Agent configuration requiring 1 vCPU and 0.5 GB of memory. With managed daemons, this configuration is applied once at the daemon task definition level. Any application task subsequently deployed to instances managed by that capacity provider will automatically inherit the presence of this agent, consuming its services without needing to declare it in its own task definition or allocate resources for it. This separation significantly reduces boilerplate and cognitive load for application developers.
A Technical Deep Dive: How Managed Daemons Operate

Underpinning this new capability are several technical innovations. The managed daemon experience introduces a new "daemon task definition" construct, distinct from standard application task definitions. This daemon task definition comes with its own parameters and validation scheme, allowing for specialized configurations tailored to operational agents.
A crucial technical detail is the introduction of a new daemon_bridge network mode. This mode facilitates communication between daemons and application tasks while maintaining isolation from application networking configurations. This ensures that changes to application network settings do not inadvertently impact the operational agents, and vice versa, enhancing stability and reducing the surface area for configuration conflicts.
Furthermore, managed daemons support advanced host-level access capabilities, which are often essential for robust operational tooling. Platform engineers can configure daemon tasks as privileged containers, grant additional Linux capabilities, and mount paths directly from the underlying host filesystem. These capabilities are particularly valuable for sophisticated monitoring and security agents that require deep visibility into host-level metrics, processes, system calls, and network interfaces. For example, a host-based intrusion detection system (HIDS) daemon might need to mount the host’s /proc or /sys filesystems to gather critical security intelligence, or a custom network monitoring tool might require specific Linux capabilities to inspect network traffic. Managed daemons provide a secure and controlled way to grant this necessary access.
When a daemon is deployed, ECS intelligently manages its placement. It launches exactly one daemon process per container instance before placing any application tasks. This strategic ordering guarantees that the operational tooling is fully functional and ready to collect data from the moment an application starts receiving traffic, providing an immediate and comprehensive view of its health and performance.
The system also incorporates robust deployment mechanisms, including rolling deployments with automatic rollbacks. This means that platform teams can update their agents with confidence. When an update is initiated, ECS provisions new instances with the updated daemon, starts the daemon, then seamlessly migrates application tasks to these new instances before terminating the old ones. This "start before stop" approach, coupled with configurable drain percentages, ensures continuous daemon coverage throughout the update process. If an issue is detected, automatic rollbacks can revert to the previous stable version, minimizing operational disruption and maintaining service continuity.
Industry Context: The Imperative for Observability in Modern Architectures
The release of managed daemon support aligns perfectly with broader industry trends in cloud computing and DevOps. According to various industry reports, container adoption continues to surge, with Gartner predicting that by 2027, more than 85% of global organizations will be running containerized applications in production, up from less than 35% in 2021. As organizations scale their container deployments, the complexity of managing the underlying infrastructure and ensuring robust observability becomes paramount.
Studies have consistently shown that operational overhead, often stemming from manual infrastructure management and incident response, consumes a significant portion of IT budgets. By automating and centralizing daemon management, AWS is enabling organizations to reclaim valuable engineering time, shifting focus from maintenance to innovation. This directly translates into potential cost savings and increased productivity. Furthermore, robust and consistent observability is no longer a luxury but a necessity for microservices architectures, where distributed systems make troubleshooting inherently challenging. Gaps in logging, monitoring, or tracing data can severely hamper incident response capabilities, leading to extended downtime and increased financial impact. Managed daemons provide a reliable foundation for comprehensive observability, reducing Mean Time To Resolution (MTTR) for incidents.
Statements from the Ecosystem
"This innovation directly addresses a critical pain point that our customers have expressed for years," stated an AWS spokesperson, emphasizing the strategic importance of the new feature. "Platform engineers are the unsung heroes of modern cloud operations, and they need tools that empower them to build robust, scalable infrastructure without being bottlenecked by application teams. Managed daemon support provides that independence, leading to more reliable systems, faster deployments, and ultimately, a better experience for both developers and end-users."
An industry analyst commented, "AWS continues to evolve ECS to meet the sophisticated demands of enterprise customers. This move to decouple daemon management is a smart one, recognizing the growing importance of platform engineering roles. It significantly enhances ECS’s appeal for organizations seeking a highly managed container orchestration experience, particularly those who want to standardize their operational tooling across their fleet without the overhead often associated with more complex solutions."
A hypothetical platform engineer from a large-scale e-commerce company might add, "Before this, updating our monitoring agents across hundreds of services was a multi-day coordination nightmare. Now, our platform team can manage and update these critical tools independently, ensuring consistency and security across our entire infrastructure with minimal fuss. It frees up our application developers to focus purely on building features, which is a huge win for productivity and agility."
Practical Implementation: A Simplified Operational Workflow
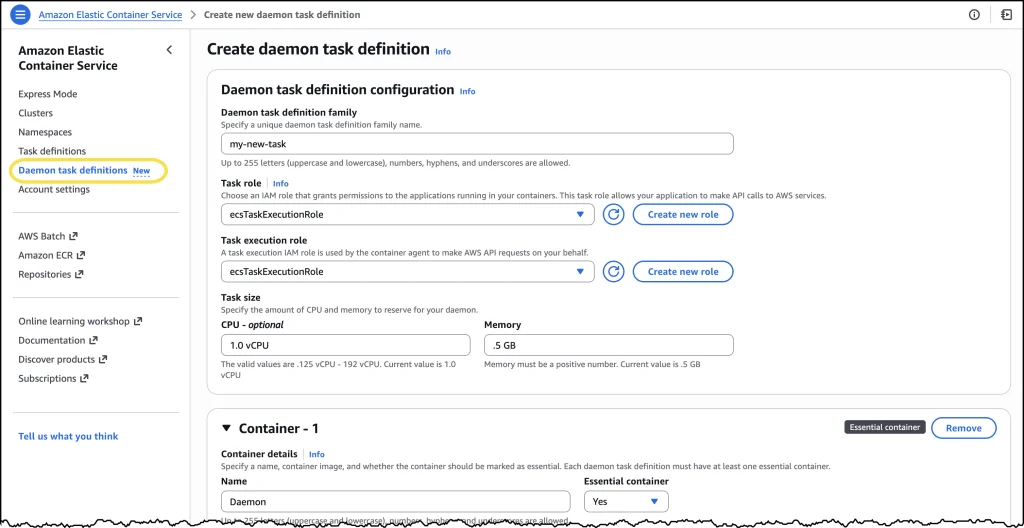
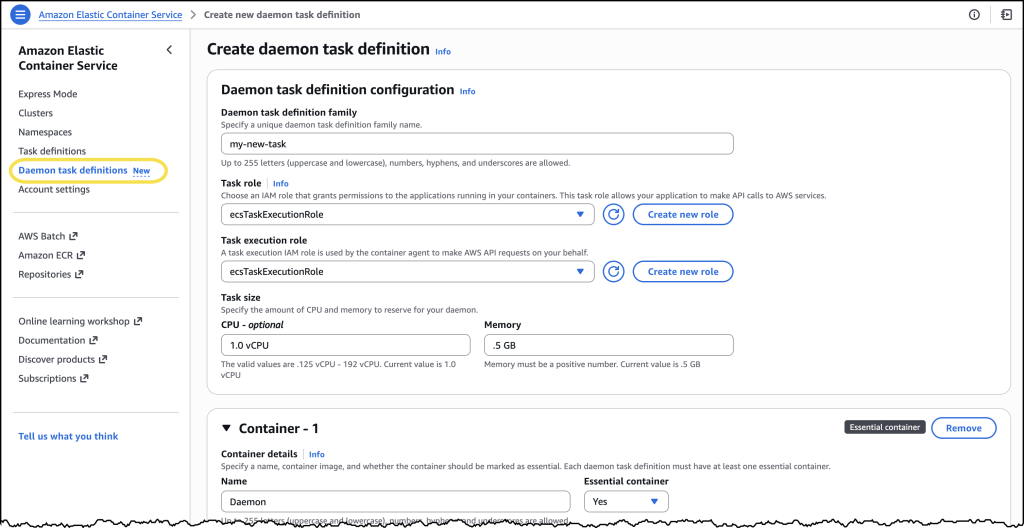
The implementation process for managed daemons has been designed for simplicity and ease of use. Platform engineers can access a new "Daemon task definitions" option within the Amazon Elastic Container Service console. Here, they can define their managed daemons, specifying details such as the container image URI (e.g., public.ecr.aws/cloudwatch-agent/cloudwatch-agent:latest), resource allocations (vCPU and memory), and a task execution role.
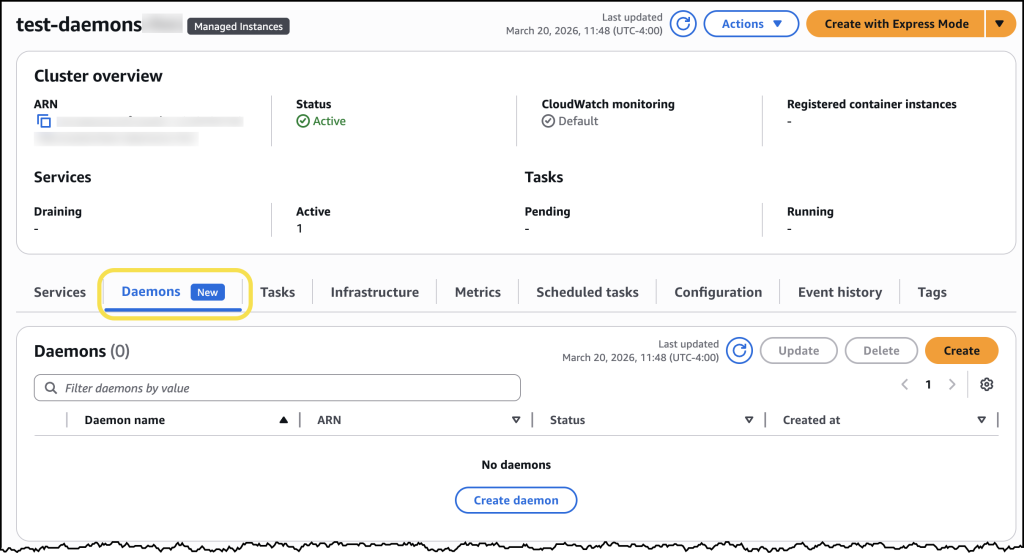
Once a daemon task definition is created, it can be deployed to an ECS cluster. A new "Daemons" tab within the cluster details page allows engineers to select their daemon task definition and assign it to specific ECS Managed Instances capacity providers. From that point, ECS automatically handles the deployment, ensuring the daemon task launches first on every provisioned instance within the selected capacity provider. This automatic orchestration extends to updates as well, with ECS managing the rolling deployment, ensuring continuous coverage and adherence to configured drain percentages.
For example, deploying an Nginx web service as a test workload to an ECS cluster configured with a managed CloudWatch Agent daemon would demonstrate the seamless integration. The console would visibly show the CloudWatch Agent daemon running alongside the application, deployed automatically without any manual intervention in the application’s task definition. This hands-off approach to operational agent management drastically reduces the administrative burden and potential for configuration drift.
Broader Strategic Implications for Cloud Operations
The introduction of managed daemon support for Amazon ECS Managed Instances carries several broader strategic implications for cloud operations and platform engineering:
- Enhanced Operational Efficiency: By automating and centralizing the management of operational agents, organizations can significantly reduce manual toil. This frees up platform engineers to focus on higher-value tasks, such as building internal developer platforms, optimizing cloud costs, or improving system resilience.
- Improved Security and Compliance Posture: Consistent deployment of security agents (e.g., vulnerability scanners, host-based firewalls) becomes simpler and more reliable. This ensures that every instance adheres to security policies from inception, strengthening the overall security posture and simplifying compliance audits.
- Cost Optimization: Better resource utilization, stemming from running exactly one daemon copy per instance and independent resource allocation, can lead to measurable cost savings by reducing unnecessary over-provisioning.
- Accelerated Innovation: Decoupling daemon lifecycles from application lifecycles means that infrastructure teams can roll out updates and improvements without disrupting application development or deployment schedules. This accelerates the pace of innovation across the organization.
- Elevated Developer Experience: Application developers can focus purely on writing application code, confident that the necessary observability and security agents are being managed reliably by the platform team. This reduces cognitive load and allows developers to be more productive.
- Strengthening the ECS Ecosystem: This feature further enhances Amazon ECS’s competitiveness as a fully managed container orchestration service, offering a compelling alternative for organizations that prioritize operational simplicity and deep AWS integration over the complexities of self-managing a Kubernetes environment.
Availability and Economic Model
Managed daemon support for Amazon ECS Managed Instances is available today across all AWS Regions where Amazon ECS is offered. To begin leveraging this capability, customers can navigate to the Amazon ECS console or consult the updated Amazon ECS documentation. The new managed daemons Application Programming Interface (APIs) are also available for programmatic control and integration into existing CI/CD pipelines.
Crucially, there is no additional cost specifically associated with using managed daemons. Customers will only incur charges for the standard compute resources (CPU and memory) consumed by their daemon tasks, aligning with AWS’s pay-as-you-go model. This transparent pricing structure further encourages adoption by ensuring that the benefits of enhanced operational efficiency and reliability are not offset by prohibitive additional fees. The feature represents AWS’s continued commitment to providing robust, scalable, and operationally efficient solutions for containerized workloads in the cloud.