
The introduction of Amazon S3 Files marks a significant evolution in cloud storage, seamlessly integrating the robust scalability and cost-efficiency of Amazon Simple Storage Service (Amazon S3) with the interactive, high-performance capabilities of a traditional file system. This new offering from Amazon Web Services (AWS) addresses a long-standing architectural challenge for enterprises and developers, enabling any AWS compute resource to access S3 data with familiar file system semantics. The announcement fundamentally reshapes how organizations can leverage their vast datasets stored in S3, making it directly accessible for a wider array of demanding workloads, including artificial intelligence (AI) model training, machine learning (ML) pipelines, and agentic AI systems.
A Decades-Old Distinction Redefined
For over a decade, cloud architects and engineers have navigated a clear distinction between object storage and file systems. Amazon S3, launched in 2006, revolutionized data storage with its unparalleled scalability, durability, and cost-effectiveness for unstructured data. It treats data as "objects" – immutable units ideal for data lakes, backups, archives, and cloud-native applications. The analogy often used to describe S3 objects compared them to books in a library: to change a single page, one must replace the entire book. This model, while incredibly powerful for certain use cases, posed challenges for applications requiring granular, byte-level modifications or hierarchical directory structures – the hallmarks of a traditional file system. File systems, on the other hand, offer interactive capabilities, allowing users and applications to modify data page by page, manage directories, and execute a range of standard file operations. This fundamental difference often necessitated complex data synchronization mechanisms, separate storage tiers, or bespoke solutions when workloads required both the scale of S3 and the interactivity of a file system. AWS itself expanded its storage portfolio over the years with services like Amazon Elastic File System (EFS) in 2016 and various Amazon FSx offerings (e.g., FSx for Lustre in 2018, FSx for Windows File Server, FSx for NetApp ONTAP, FSx for OpenZFS) to cater to diverse file system needs. However, the ideal of a single, unified data repository offering both object and file semantics at scale remained an aspiration for many.
The Genesis of S3 Files: Addressing Evolving Workloads

The impetus for Amazon S3 Files stems from the evolving landscape of cloud computing, particularly the explosion of data-intensive applications in AI, ML, and big data analytics. These modern workloads frequently require shared, concurrent access to massive datasets, often stored in S3, but demand the POSIX-like file system interface for their tools, libraries, and frameworks. Data scientists, for instance, prefer working with familiar file paths and standard commands (e.g., ls, cp, mv, rm) when preparing datasets or running training jobs. Agentic AI systems, which involve multiple autonomous agents collaborating, often rely on file-based tools and shared file systems for persistent state and inter-agent communication. Until now, bridging this gap involved either copying data to a separate file system, using object storage gateways, or developing custom connectors – all of which added complexity, increased latency, and incurred additional costs through data movement and duplication. Amazon S3 Files directly addresses these pain points by making S3 buckets directly accessible as fully-featured, high-performance file systems. This innovation positions S3 as the first and only cloud object store to natively offer such comprehensive file system access, eliminating the previous trade-off between S3’s inherent advantages and a file system’s interactive capabilities. AWS spokespersons anticipate that this simplification will empower organizations to unlock new value from their S3-resident data lakes.
Key Features and Technical Deep Dive
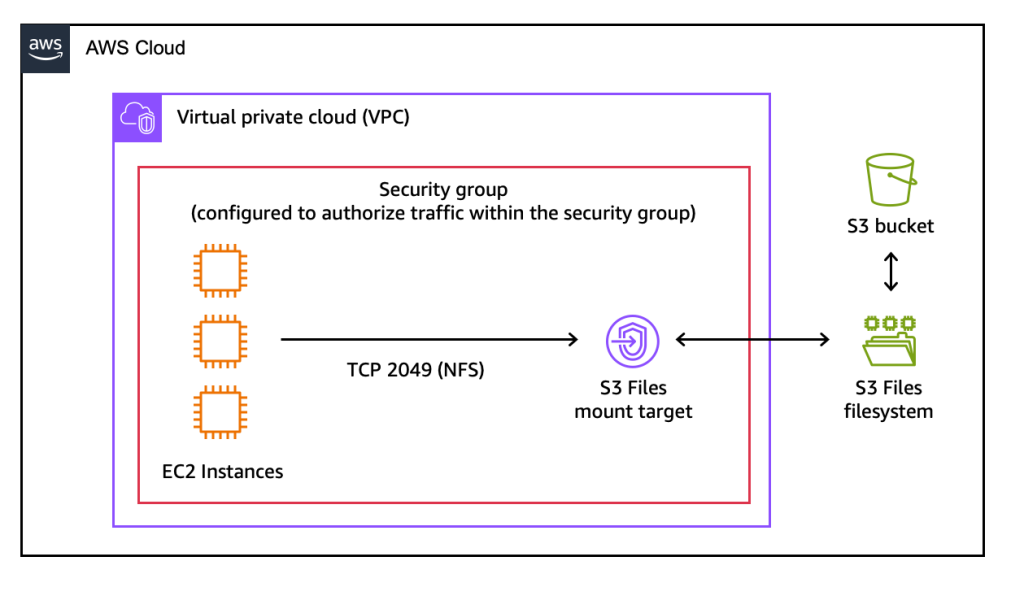
Amazon S3 Files transforms S3 buckets into network file systems, supporting the Network File System (NFS) v4.1+ protocol. This broad compatibility means that any AWS compute instance, container, or function that can mount an NFS share can now directly interact with S3 data as if it were local file storage. This includes Amazon Elastic Compute Cloud (EC2) instances, containers orchestrated by Amazon Elastic Container Service (ECS) or Amazon Elastic Kubernetes Service (EKS), and even serverless functions running on AWS Lambda.
At its core, S3 Files presents S3 objects as files and S3 prefixes as directories, enabling standard file operations such as creating, reading, updating, and deleting files. Crucially, changes made through the file system are automatically reflected in the underlying S3 bucket, and vice-versa, with fine-grained control over synchronization. This bi-directional synchronization ensures data consistency across both access patterns.
To achieve high performance, S3 Files intelligently leverages a high-performance storage layer, which, under the hood, utilizes Amazon Elastic File System (EFS) technology. This design allows S3 Files to deliver impressive sub-millisecond latencies (approximately 1ms) for actively accessed data. When applications request data, associated file metadata and contents that benefit from low-latency access are automatically placed onto this high-performance storage. For files that do not require such interactive speeds, or for large sequential reads, S3 Files intelligently serves data directly from Amazon S3, maximizing throughput and optimizing for cost. This tiered approach ensures that users get the best of both worlds: high performance for active working sets and cost-efficiency for less frequently accessed or large archival data. Furthermore, for byte-range reads, only the requested bytes are transferred, minimizing data movement and associated egress costs.

Advanced features like intelligent pre-fetching anticipate data access needs, further enhancing performance. Users also retain fine-grained control over what data is stored on the high-performance layer, with options to load full file data or metadata only, allowing for tailored optimization based on specific application access patterns. The system supports concurrent access from multiple compute resources, coupled with NFS close-to-open consistency, making it eminently suitable for collaborative, data-mutating workloads.
Operational Simplicity and Developer Empowerment
The operational model for Amazon S3 Files is designed for simplicity. Users can create an S3 file system directly from the AWS Management Console, the AWS Command Line Interface (CLI), or through infrastructure as code (IaC) tools. The process involves specifying an S3 bucket to be exposed as a file system, after which AWS automatically provisions the necessary mount targets – network endpoints within the user’s Virtual Private Cloud (VPC) that allow EC2 instances and other compute resources to connect. Mounting the S3 file system on an EC2 instance, for example, is as straightforward as executing a standard mount command, after which the S3 data becomes accessible via familiar file system commands.
This ease of integration means developers can continue to use their existing file-based tools, scripts, and libraries without modification, but now with the backend leveraging the massive scale and durability of S3. For instance, a data scientist running a Python script that expects to read data from /data/input.csv can now have /data be a mounted S3 file system, transparently accessing input.csv stored in an S3 bucket. Updates made to files within the mounted file system are automatically managed and exported back to the S3 bucket, appearing as new objects or new versions of existing objects within minutes. Conversely, changes made directly to objects in the S3 bucket are reflected in the file system, typically within seconds to a minute, ensuring near real-time consistency. This automatic synchronization greatly reduces the complexity of managing data across different storage paradigms, freeing up developers and operations teams to focus on application logic rather than data orchestration.
Strategic Positioning within the AWS Storage Ecosystem
AWS’s storage portfolio is comprehensive, leading some customers to seek clarification on the optimal service for specific needs. Amazon S3 Files carves out a distinct and critical niche within this ecosystem, complementing existing services rather than replacing them.
- S3 Files vs. S3 Direct Access: S3 Files is ideal when workloads require interactive, shared access to data residing in S3 through a file system interface. This is particularly true for applications that mutate data collaboratively, such as agentic AI agents, ML training pipelines that process and modify datasets, or production applications built on file-based tools. It offers shared access across compute clusters without data duplication, sub-millisecond latency for active data, and automatic synchronization with the S3 bucket.
- S3 Files vs. Amazon EFS: While S3 Files leverages EFS technology under the hood for its high-performance tier, EFS itself remains the go-to choice for cloud-native applications requiring a fully managed, scalable, and highly available NFS file system for primary storage. EFS is often used for general-purpose file storage, containerized applications, and serverless workloads where the primary data source is expected to be a file system from the outset, rather than an S3 bucket.
- S3 Files vs. Amazon FSx Family: The Amazon FSx family of services (FSx for Lustre, FSx for Windows File Server, FSx for NetApp ONTAP, FSx for OpenZFS) continues to be the preferred solution for specific enterprise and high-performance computing (HPC) workloads. FSx is designed for migrating applications from on-premises Network Attached Storage (NAS) environments that require specific file system capabilities, protocols, or performance characteristics (e.g., Lustre for petabyte-scale HPC workloads, Windows File Server for Windows-native applications, ONTAP for data management features). S3 Files does not aim to replace these specialized offerings but rather to extend the versatility of S3 for interactive, file-based access where S3 is the primary data lake.
Essentially, S3 Files empowers organizations that have already standardized on S3 as their central data lake to unlock new use cases without having to migrate or duplicate data into a separate file system. It positions S3 as an even more foundational data layer, capable of serving an unprecedented range of access patterns.
Market Impact and Industry Implications
The launch of Amazon S3 Files is poised to have a significant impact on cloud architecture design and data management strategies. Industry analysts are likely to view this as a strategic move by AWS to further solidify S3’s position as the ubiquitous data platform in the cloud. By dissolving the traditional barriers between object and file storage, AWS simplifies cloud architectures, reducing the need for complex data pipelines, custom integration layers, and manual data movement between disparate storage services. This simplification translates directly into reduced operational overhead, lower costs associated with data ingress/egress and duplication, and faster time-to-market for new applications.
For the burgeoning fields of AI and ML, S3 Files represents a considerable boon. Data scientists and ML engineers can now seamlessly access and manipulate vast S3-based datasets using their preferred file-based tools, accelerating experimentation, training, and deployment cycles. The capability to share data across multiple compute resources without duplication is particularly valuable in collaborative ML environments. Furthermore, the rise of agentic AI systems, which often interact with environments and tools through file system interfaces, will find S3 Files to be a critical enabling technology, allowing these intelligent agents to operate directly on a scalable and durable S3 backend.
This innovation also strengthens AWS’s competitive stance in the cloud storage market. While other cloud providers offer various object storage and file system solutions, the ability to seamlessly bridge the two with high performance and native integration at S3’s scale is a distinct advantage. It underlines AWS’s commitment to responding to customer feedback and evolving workload requirements, ensuring that their foundational services remain at the forefront of cloud innovation.
Availability and Pricing Structure
Amazon S3 Files is generally available today across all commercial AWS Regions, offering broad accessibility to customers worldwide.
The pricing model for S3 Files is designed to reflect its hybrid nature, with costs incurred for several components:
- Data Stored: Customers pay for the portion of data actively stored within their S3 file system’s high-performance tier, which is analogous to EFS pricing.
- Operations: Costs apply to small file read and all write operations performed on the file system.
- S3 Requests: Charges are incurred for S3 requests generated during the data synchronization process between the S3 file system and the underlying S3 bucket.
Detailed pricing information, including specific rates for data storage, operations, and S3 requests, is available on the Amazon S3 pricing page. This transparent model allows organizations to estimate costs based on their specific usage patterns, ensuring cost-effectiveness for varying workloads.
Conclusion
The introduction of Amazon S3 Files represents a pivotal advancement in cloud storage, addressing a long-standing dichotomy between object and file systems. By enabling direct, high-performance, and interactive file system access to Amazon S3 data, AWS has eliminated a significant architectural trade-off, empowering organizations to simplify their cloud environments, reduce data silos, and accelerate innovation. Whether for production applications, advanced AI/ML workloads, or the emerging wave of agentic AI systems, S3 Files ensures that Amazon S3 can truly serve as the central, universal hub for all an organization’s data, accessible from any AWS compute instance, container, or function without compromise. This capability not only streamlines data management but also unlocks new possibilities for how data is leveraged across the entire cloud ecosystem, marking a new chapter in scalable and versatile cloud storage.