
The rapid ascent of Artificial Intelligence, particularly Large Language Models (LLMs), has fundamentally reshaped the landscape of data management. In the nascent stages of this AI revolution, a prevalent architectural pattern emerged: connecting an LLM directly to a vector store. This design, often seen in proof-of-concept chatbots and early generative AI products, fostered a perception that vector databases alone could constitute the entire data layer for modern AI applications. However, as AI systems transition from experimental prototypes to robust, production-grade tools handling real users, sensitive data, and financial transactions, the limitations of a vector-only approach become starkly evident. A comprehensive, resilient AI infrastructure demands two complementary data engines operating in concert: a vector database optimized for semantic retrieval and a relational database providing the bedrock for structured, transactional operations. This dual-database strategy is not merely an optimization; it is a foundational requirement for building secure, accurate, and scalable AI applications.
The Rise of Vector Databases and the AI Data Layer Paradigm Shift
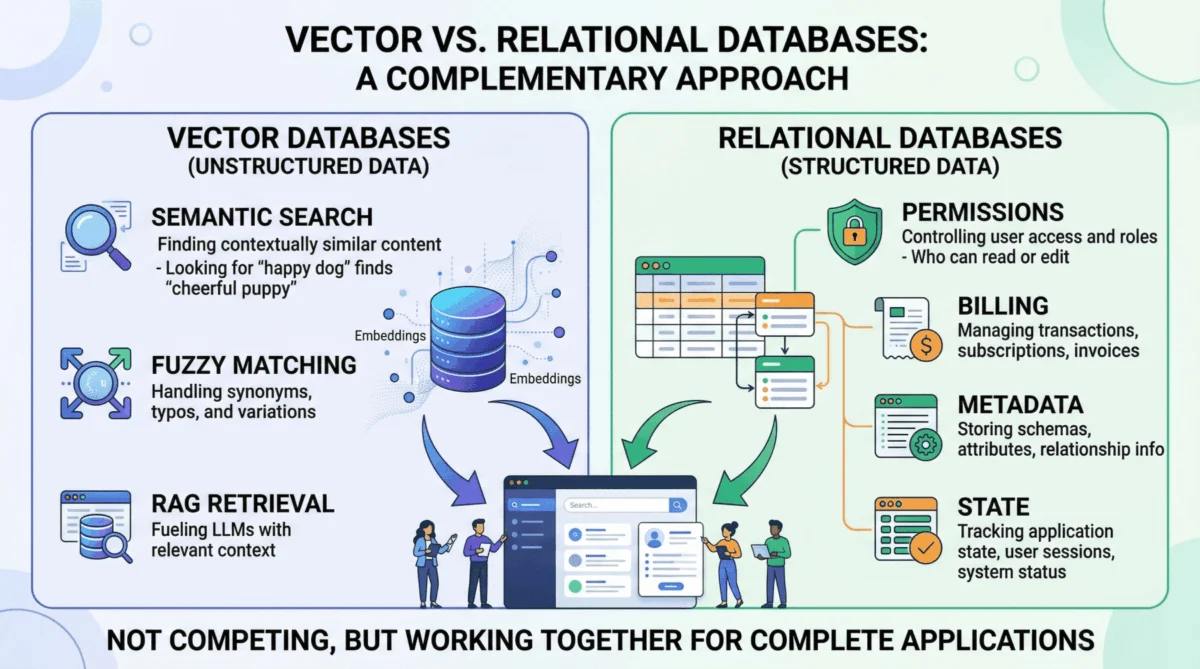
The explosion of interest in generative AI, particularly since late 2022, has propelled vector databases into the spotlight. These specialized databases, exemplified by solutions like Pinecone, Milvus, and Weaviate, are engineered to store and query high-dimensional vector embeddings. These embeddings are numerical representations of data – be it text, images, audio, or other complex types – that capture semantic meaning. The closer two vectors are in this high-dimensional space, the more semantically similar their underlying data is. This capability is crucial for Retrieval Augmented Generation (RAG), a paradigm that significantly enhances LLM performance by providing them with specific, relevant, and proprietary context, thereby mitigating hallucinations and improving factual accuracy.
In a typical RAG workflow, a user query is converted into a vector embedding. This query embedding is then used to perform a similarity search within the vector database, retrieving the most semantically relevant data chunks from a vast corpus. This meaning-based retrieval is a transformative leap beyond traditional keyword searches, allowing AI agents to understand user intent even with varied phrasing, synonyms, or implicit context. For instance, a legal AI agent queried about "tenant rights regarding mold" could retrieve documents referencing "habitability standards" or "landlord maintenance obligations" without those exact keywords appearing. This flexibility makes vector databases indispensable for navigating the inherently messy and unstructured data of the real world.
However, the very probabilistic nature that grants vector databases their semantic flexibility also introduces imprecision, which is unsuitable for operations demanding absolute accuracy and transactional integrity. Industry reports from firms like Gartner and Forrester highlight the rapid adoption of vector databases, projecting market growth rates exceeding 30% annually for specialized AI infrastructure. Yet, these same reports often caution against treating them as a monolithic data solution, emphasizing the need for integration with established data management systems.
The Unwavering Core: Relational Databases and Operational Integrity
While vector databases excel at conceptual understanding, they are fundamentally ill-equipped to handle the structured, deterministic, and transactional workloads that underpin most production applications. This is where the enduring power of relational databases, such as PostgreSQL, MySQL, and Oracle, becomes indispensable. Relational databases, with their ACID (Atomicity, Consistency, Isolation, Durability) guarantees, SQL-based querying, and rigid schema enforcement, manage the "hard facts" and operational state of an AI system.
Critical Domains Managed by Relational Databases:
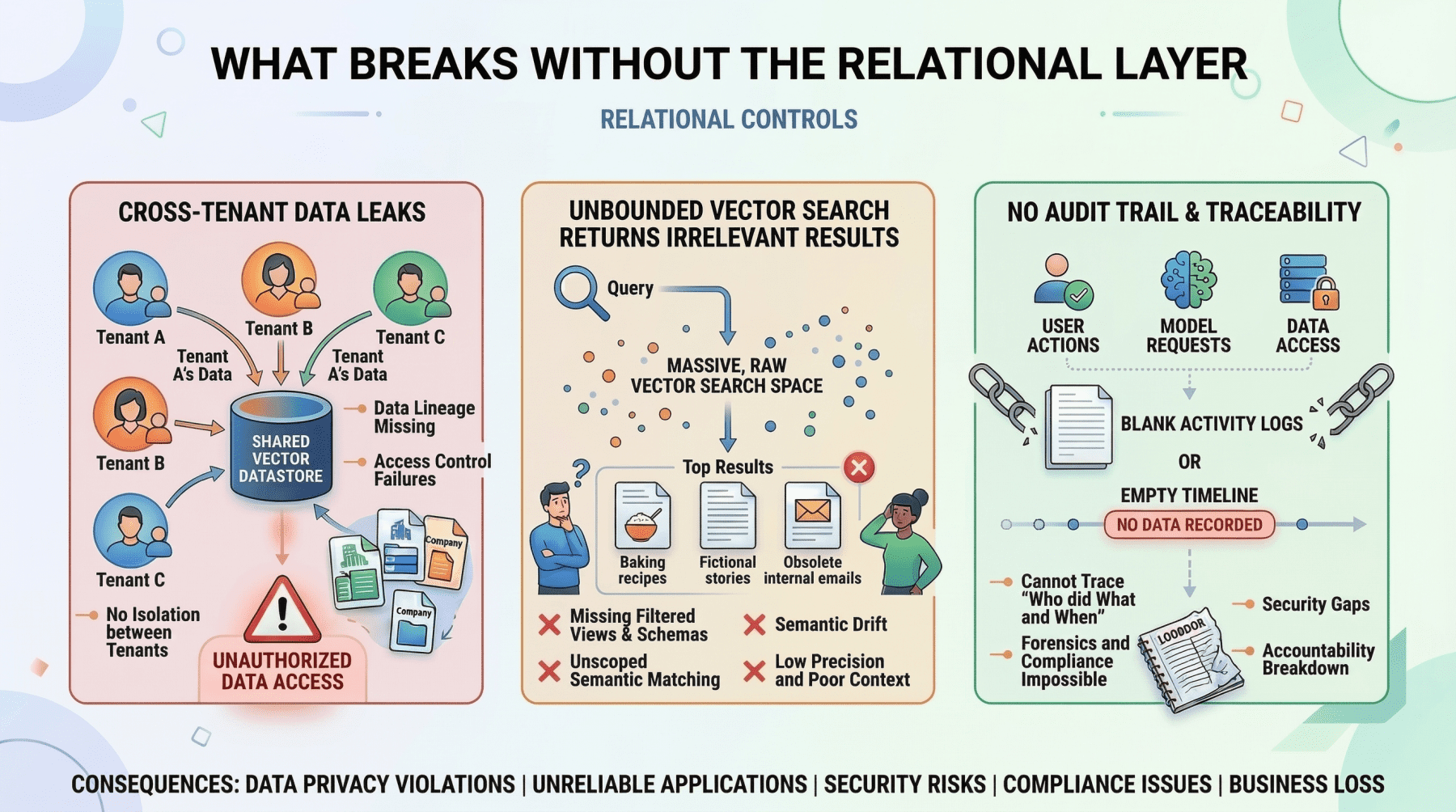
- User Identity and Access Control: The absolute precision required for authentication, role-based access control (RBAC), and multi-tenant data isolation cannot be left to probabilistic similarity searches. Determining if a user has permission to view a confidential document is a binary decision (yes/no), not an approximate one. Relational databases provide the definitive answers, ensuring data security and compliance. A misstep here could lead to severe data breaches or regulatory penalties.
- Metadata Management for Embeddings: Every vector embedding stored in a vector database represents a chunk of information. But what is that information? Where did it come from? Who created it? When was it last updated? What are its access restrictions? This crucial contextual information – the document’s original URL, author ID, upload timestamp, file hash, and departmental permissions – is invariably stored and managed within a relational database. This metadata layer is the essential bridge connecting the abstract semantic index to the concrete realities of the data source and its governance. Without it, vector embeddings lack actionable context and proper control.
- Pre-filtering for Contextual Accuracy and Efficiency: One of the most effective strategies to prevent LLM hallucinations and optimize resource usage is to meticulously scope the context provided to the model. Before any vector search, a relational database can be leveraged to precisely filter the dataset based on structured criteria. For instance, an AI project management agent tasked with summarizing "all high-priority tickets resolved in the last 7 days for the frontend team" must first use exact SQL queries to isolate these specific tickets. This pre-filtering strips away irrelevant data, ensuring the LLM only processes pertinent information. This approach is not only more reliable and accurate than relying solely on vector search to infer such precise conditions but also significantly more cost-effective and faster, as it reduces the volume of data processed by the more computationally intensive vector search and LLM inference.
- Billing, Audit Logs, and Compliance: Enterprise-grade AI deployments operate within a framework of legal, regulatory, and financial constraints. Every interaction, every data access, and every transaction must be recorded with absolute transactional consistency. Billing for API usage, maintaining detailed audit trails for regulatory compliance (e.g., GDPR, HIPAA), and tracking system performance metrics are quintessential structured data problems. Relational databases, with decades of battle-tested reliability, are the only suitable tools for these critical functions, ensuring accountability and adherence to corporate governance.
The inherent limitation of relational databases in the AI era is their lack of native semantic understanding. Querying conceptually similar passages across millions of unstructured text entries using only SQL is computationally prohibitive and yields subpar results. This is precisely the void that vector databases are designed to fill.
The Hybrid Architecture: A Symbiotic Relationship
The most sophisticated and resilient AI applications treat vector and relational databases not as competing technologies but as synergistic layers within a unified data architecture. The vector database handles the nuanced world of semantic retrieval, while the relational database anchors the system in operational reality. Crucially, these systems are designed to communicate and interoperate seamlessly.
Key Hybrid Patterns:
-
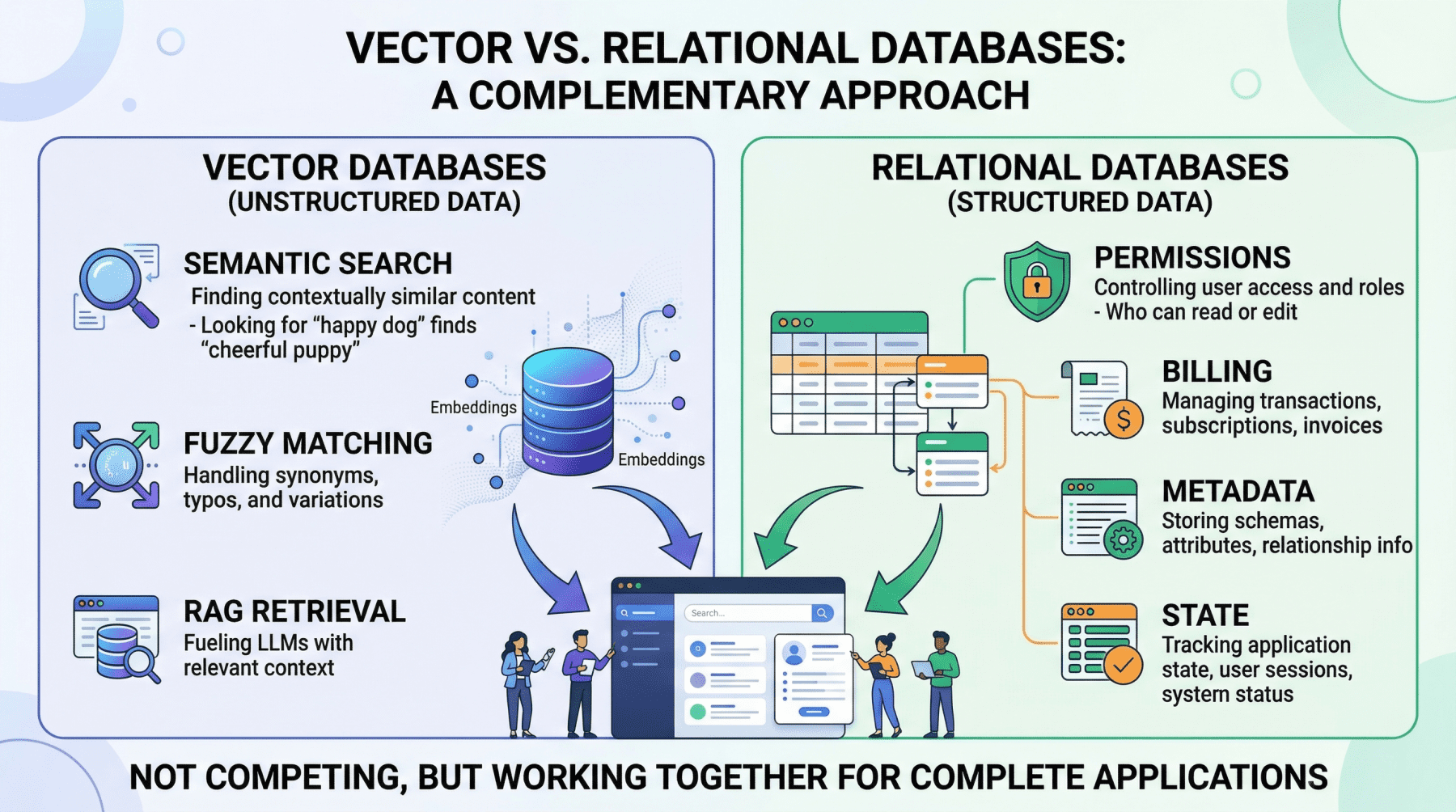
The Pre-Filter Pattern: This is arguably the most common and critical hybrid pattern, especially for security and data governance. Before initiating a vector query, a SQL filter is applied to narrow down the search space.
- Example: In a multi-tenant customer support AI, a user from "Company A" asks, "What’s our policy on refunds for enterprise contracts?"
- The application first queries the relational database to identify all documents belonging to "Company A" that the user is authorized to access.
- Only the vector embeddings corresponding to these pre-filtered, authorized documents are then subjected to a semantic similarity search based on the user’s query.
- Without this initial relational pre-filter, the vector search could inadvertently retrieve semantically similar passages from "Company B’s" policy documents or "Company A" documents that the user lacks permission to view, leading to a severe data leak. This relational-driven security boundary is non-negotiable for enterprise applications.
- Example: In a multi-tenant customer support AI, a user from "Company A" asks, "What’s our policy on refunds for enterprise contracts?"
-
The Post-Retrieval Enrichment Pattern: This pattern involves using the relational database to augment the results obtained from a vector search with structured metadata.
- Example: An internal knowledge base AI agent retrieves the three most semantically relevant document passages via a vector search. The application then uses the document IDs from these passages to query the relational database. This query retrieves associated metadata such as the author’s name, the last-updated timestamp, the document’s confidence rating, or relevant internal classifications.
- This enriched context is then either presented directly to the user or fed to the LLM, enabling it to generate a more nuanced, authoritative, and contextually aware response (e.g., "According to the Q3 security policy, last updated on October 12th by the compliance team…"). This significantly improves the utility and trustworthiness of the AI’s output.
Unified Storage with pgvector: Bridging the Operational Gap
For many organizations, particularly those at moderate scale or seeking to minimize operational complexity, managing two distinct database systems (one relational, one vector) can introduce overhead. This is where pgvector, an open-source extension for PostgreSQL, presents a compelling solution. pgvector allows developers to store vector embeddings directly as a column within a PostgreSQL table, alongside traditional structured relational data.
This unified approach enables a single database to handle both relational queries and vector similarity searches. A single SQL query can seamlessly combine exact filtering, complex joins, and vector similarity search in one atomic operation.
Example pgvector Query:
SELECT d.title, d.author, d.updated_at, d.content_chunk,
1 - (d.embedding <=> query_embedding) AS similarity
FROM documents d
JOIN user_permissions p ON p.department_id = d.department_id
WHERE p.user_id = 'user_98765'
AND d.status = 'published'
AND d.updated_at > NOW() - INTERVAL '90 days'
ORDER BY d.embedding <=> query_embedding
LIMIT 10;This single query, executed within one transaction and without any synchronization between disparate systems, accomplishes several critical tasks:
- Security Filtering: It restricts results based on
user_idanddepartment_idvia a join withuser_permissions. - Status Filtering: It includes only documents with
status = 'published'. - Temporal Filtering: It limits results to documents updated within the last 90 days.
- Semantic Search: It orders the filtered results by semantic similarity to the
query_embedding, returning the top 10 most relevant chunks.
The primary trade-off with pgvector is performance at extreme scale. Dedicated vector databases are purpose-built and highly optimized for approximate nearest neighbor (ANN) search across billions of vectors, often leveraging distributed architectures and specialized indexing techniques that can outperform pgvector in such scenarios. However, for applications with data corpora ranging from hundreds of thousands to a few million vectors, pgvector significantly reduces infrastructure complexity, operational burden, and data synchronization challenges. It offers an excellent starting point for many teams, with a clear migration path to a dedicated vector store should the application’s scale demand it in the future.
Strategic Choices and Future Outlook
The decision framework for implementing the data layer in AI applications is becoming increasingly clear:
- For high-volume, highly concurrent, or extremely large-scale vector workloads (billions of vectors): A dedicated vector database (e.g., Pinecone, Milvus, Weaviate) is the optimal choice, integrated with a robust relational database for all structured and transactional data.
- For moderate-scale vector workloads (millions of vectors) where operational simplicity is paramount:
pgvectorwithin PostgreSQL offers a compelling unified solution, leveraging the familiarity and reliability of a single system for both relational and semantic data.
In both scenarios, the relational layer remains a non-negotiable foundation. It serves as the system’s operational backbone, managing user identities, access permissions, essential metadata, billing, and overall application state. The only variable is whether the vector storage component resides internally within this relational foundation or as a co-located, specialized external service.
Industry analysts and leading data architects increasingly concur that a hybrid data strategy is not just best practice but an absolute necessity for robust AI development. A recent report by O’Reilly Media underscored this, noting that "enterprises moving beyond initial AI experiments are converging on architectures that blend the strengths of semantic search with the transactional integrity of traditional databases." This evolution reflects a maturing understanding of AI system requirements, moving past the initial hype to a more pragmatic and resilient approach.
Conclusion
Vector databases are undeniably a transformative technology, enabling AI systems to understand and interact with information based on meaning rather than mere keywords. This capability is fundamental to the efficacy of generative AI, particularly within the RAG paradigm. However, their role is complementary, not solitary.
The relational database, with its decades of proven reliability, transactional consistency, and precise data management capabilities, forms the essential operational backbone of any production-grade AI application. It enforces security, manages user and application state, provides the critical structured metadata that contextualizes semantic indexes, and ensures compliance and accountability.
To build truly resilient, secure, and scalable AI applications, developers must move beyond the misconception of a vector-only data layer. The most effective architectures are those that strategically leverage each database type where it is strongest. By establishing a solid relational foundation for structured data and integrating vector storage precisely where semantic retrieval is technically necessary—either through a dedicated service or a unified solution like pgvector—organizations can construct AI systems that are both intelligently semantic and operationally robust, ready to handle the complexities of the real world. This balanced approach is the hallmark of sophisticated, enterprise-ready AI.