
The Rise of Vector Databases in the AI Era
The past few years have witnessed an explosion in the capabilities and accessibility of LLMs. However, these powerful models inherently suffer from limitations, including a propensity to "hallucinate" (generate factually incorrect information) and a knowledge cutoff that prevents them from accessing the most current or proprietary data. Retrieval Augmented Generation (RAG) emerged as a transformative pattern to mitigate these issues. RAG allows an LLM to query an external knowledge base for relevant context before generating a response, thereby grounding its output in specific, verifiable information.
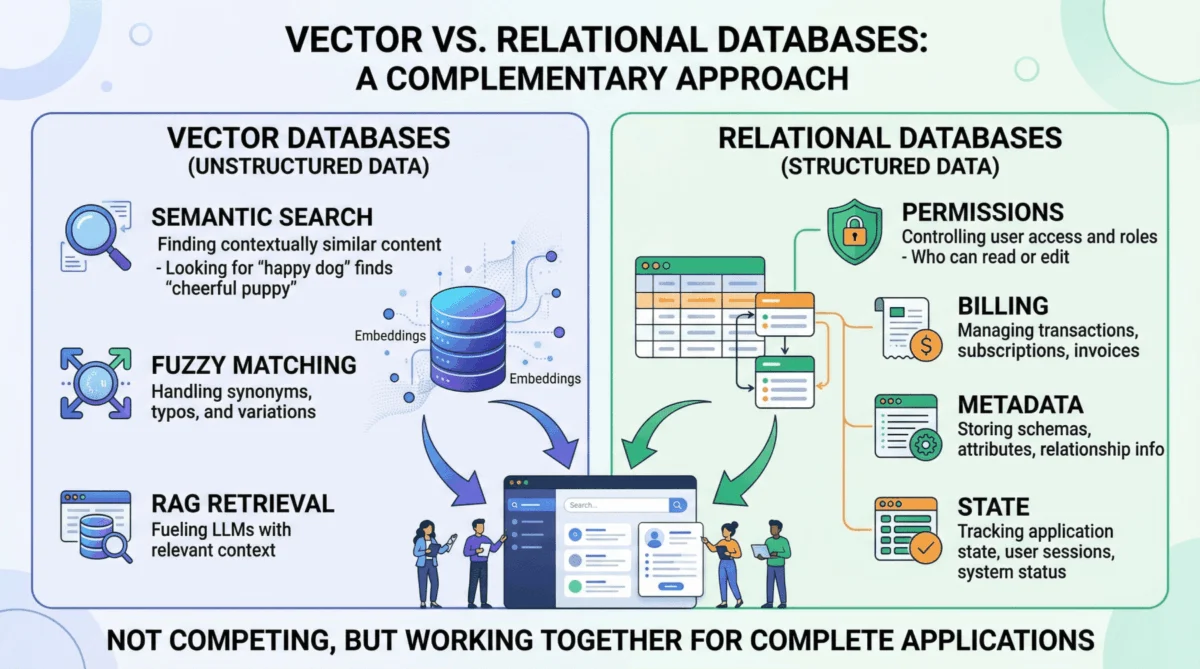
This innovation directly propelled vector databases into the spotlight. Unlike traditional databases that index data for exact matches or range queries, vector databases store data as high-dimensional numerical representations called embeddings. These embeddings capture the semantic meaning of text, images, or other data types. When a user inputs a query, it too is converted into an embedding, and the vector database quickly finds the most "semantically similar" embeddings in its corpus. This meaning-based retrieval is foundational for RAG, allowing AI agents to understand nuanced user intent and retrieve conceptually relevant documents even if exact keywords aren’t present. Dedicated vector stores like Pinecone, Milvus, and Weaviate have capitalized on this need, offering optimized infrastructures for these computationally intensive similarity searches.
The Inherent Limitations of Vector-Only Architectures
Despite their undeniable utility for semantic search, treating a vector database as the sole data layer for an AI application quickly exposes critical vulnerabilities and operational gaps. The very mechanism that makes semantic search flexible—its probabilistic nature—renders it unsuitable for tasks requiring absolute precision and transactional integrity.
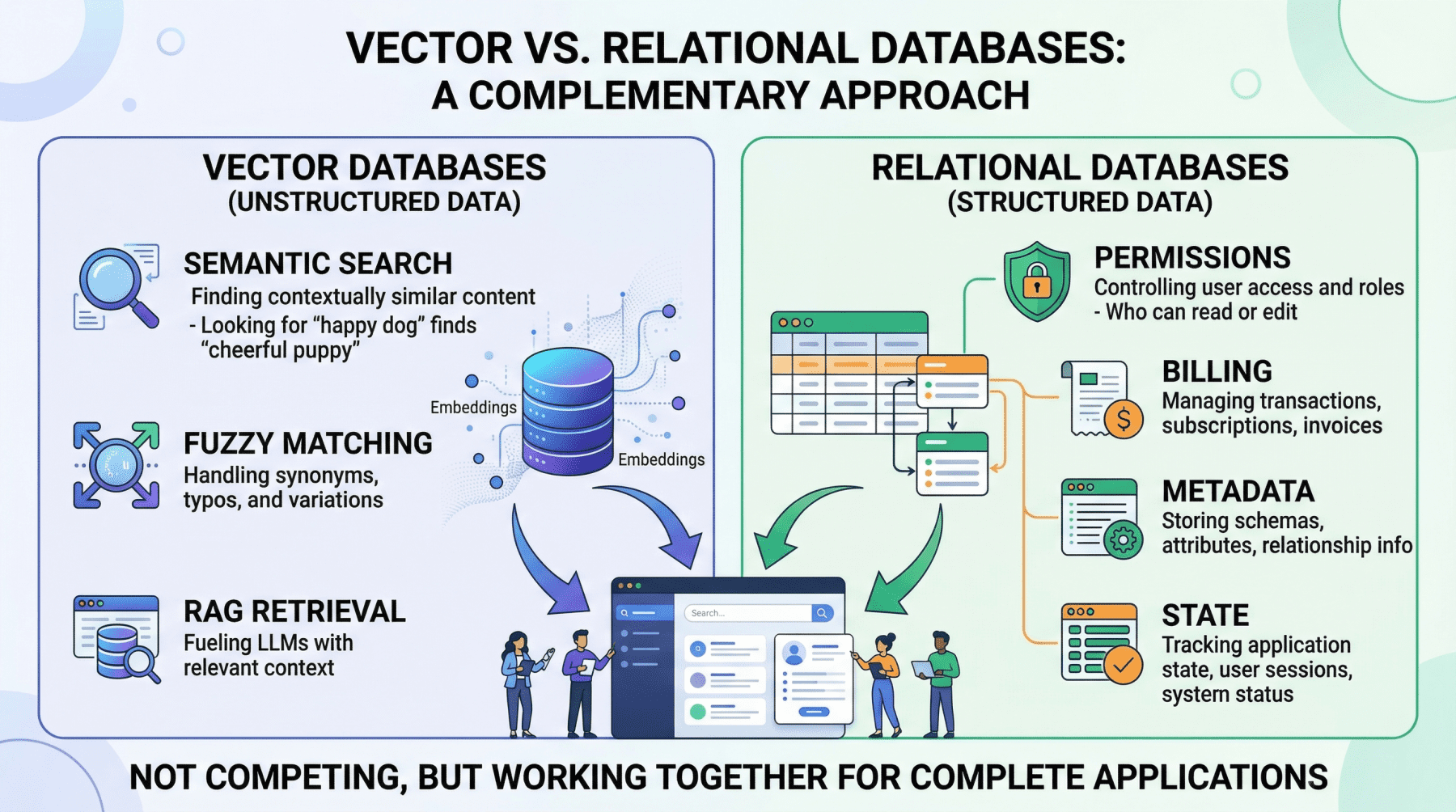
Consider an AI application tasked with managing customer support tickets. If a developer attempts to retrieve "all support tickets created by user ID user_4242 between January 1st and January 31st," a vector similarity search would be an inappropriate tool. It would return results based on conceptual similarity to the query, but it could not guarantee that every relevant ticket was included, nor that only tickets meeting the precise criteria were returned. Such a query demands deterministic, exact filtering, a strength of relational databases.
Furthermore, operational workloads frequently require aggregations. Counting active user sessions, summing API token usage for billing purposes, or computing average response times by customer tier are trivial operations in a SQL environment. With vector embeddings alone, these tasks are either impossible or wildly inefficient, as vector databases are not designed for aggregate computations across structured attributes.
Finally, managing application state—conditionally updating a user profile field, toggling a feature flag, or recording that a conversation has been archived—involves transactional writes against structured data. Vector databases are optimized for high-volume insert-and-search operations but lack the ACID (Atomicity, Consistency, Isolation, Durability) guarantees and read-modify-write capabilities essential for maintaining consistent and reliable application state. If an AI application extends beyond merely answering questions from a static document corpus—if it involves user accounts, billing, permissions, or any form of dynamic application state—a vector database, by design, cannot fulfill these responsibilities.
Relational Databases: The Indispensable Operational Backbone
For decades, relational databases like PostgreSQL and MySQL have served as the bedrock of enterprise applications, lauded for their reliability, data integrity, and structured query capabilities. In the AI era, their role is not diminished but rather redefined and amplified as the essential operational backbone for critical functions that vector databases cannot address.
One of the foremost domains where relational databases are non-negotiable is user identity and access control. Authentication mechanisms, role-based access control (RBAC) permissions, and multi-tenant boundaries demand absolute precision. An AI agent deciding which internal documents a user can read and summarize must rely on permissions retrieved with 100% accuracy. Attempting to use approximate nearest neighbor search to determine if a junior analyst is authorized to view a confidential financial report is not only unreliable but a severe security risk. This binary, definitive decision is unequivocally a task for a relational database, which can enforce complex authorization rules with precision.
Equally critical is the management of metadata for embeddings. While a vector database stores the semantic representation of a chunked PDF document, it rarely stores the document’s original URL, author ID, upload timestamp, file hash, or departmental access restrictions. This structured "something else" is almost invariably stored in a relational table. This metadata layer is the crucial link that connects the abstract semantic index in the vector database to the tangible, real-world attributes and constraints of the data. Without it, the semantic search results lack context and actionable information.
Relational databases also play a pivotal role in pre-filtering context to reduce hallucinations. One of the most effective strategies to prevent LLMs from generating irrelevant or incorrect information is to ensure they only reason over precisely scoped, factual context. For instance, if an AI project management agent needs to generate a summary of "all high-priority tickets resolved in the last 7 days for the frontend team," the system must first use exact SQL filtering to isolate those specific tickets. This pre-processing step, performed by a relational database, efficiently strips out irrelevant data, ensuring the LLM only sees pertinent information. This approach is not only cheaper and faster than relying on vector search alone to achieve perfect scope but also significantly more reliable in preventing hallucinations.
Finally, billing, audit logs, and compliance are domains where relational databases offer decades of battle-tested reliability. Any enterprise-grade AI deployment requires a transactionally consistent, immutable record of what happened, when, and who authorized it. These are fundamentally structured data problems, demanding the ACID guarantees and robust transactional capabilities that relational databases provide. They ensure accountability, support regulatory requirements, and underpin the financial integrity of AI services.
The limitation of relational databases in this context is straightforward: they lack a native understanding of semantic meaning. Attempting to search for conceptually similar passages across millions of rows of raw text using SQL is computationally expensive, slow, and typically yields poor results compared to vector search. This is precisely the functional gap that vector databases were designed to fill.
The Hybrid Architecture: A Unified Approach
The most effective and resilient AI applications treat vector and relational databases not as competing technologies but as complementary layers within a cohesive system. The vector database handles semantic retrieval, while the relational database manages all structured, transactional, and metadata-related concerns. Crucially, these two systems are designed to interact seamlessly.
The Pre-Filter Pattern exemplifies this synergy. This common hybrid approach uses SQL to precisely scope the search space before executing a vector query. Consider a multi-tenant customer support AI where a user from "Company A" asks, "What’s our policy on refunds for enterprise contracts?" The application workflow would involve:
- Relational Pre-filter: A SQL query against the relational database to identify all document IDs or content chunks associated with "Company A" and to which the user has permission. This step is critical for security and data isolation.
- Vector Search: The user’s query is embedded, and a vector search is performed only against the pre-filtered set of document embeddings retrieved in step one.
- Result Aggregation: The semantically relevant results from the vector search are then passed to the LLM.
Without the initial relational pre-filter, the vector search might inadvertently return semantically relevant passages from Company B’s policy documents or from Company A documents that the user is not authorized to access, leading to severe data leaks. The relational pre-filter acts as an indispensable security boundary.
Conversely, the Post-Retrieval Enrichment Pattern involves querying the relational database after a vector search to enrich the results with structured metadata. An internal knowledge base agent, for instance, might retrieve the three most relevant document passages via vector search. It would then join these results against a relational table to attach critical metadata such as the author’s name, the last-updated timestamp, and the document’s confidence rating. This enriched information allows the LLM to provide more contextually aware and qualified responses, such as: "According to the Q3 security policy (last updated October 12th, authored by the compliance team)…"
Unified Storage with pgvector
For many organizations, the operational overhead of managing two distinct database systems—a vector store and a relational database—can be a significant deterrent, especially at moderate scales. This is where pgvector, the vector similarity extension for PostgreSQL, offers a compelling solution. pgvector allows developers to store embeddings as a column directly alongside their structured relational data within a single PostgreSQL instance. This unification enables a single query to combine exact SQL filters, joins, and vector similarity search in one atomic operation.
For example, a unified query might look like this:
SELECT d.title, d.author, d.updated_at, d.content_chunk,
1 - (d.embedding <=> query_embedding) AS similarity
FROM documents d
JOIN user_permissions p ON p.department_id = d.department_id
WHERE p.user_id = 'user_98765'
AND d.status = 'published'
AND d.updated_at > NOW() - INTERVAL '90 days'
ORDER BY d.embedding <=> query_embedding
LIMIT 10;Within a single transaction, without the need for synchronization between separate systems, this query performs several critical actions:
- Enforces Permissions: It filters documents based on
user_permissions, ensuring data access control. - Applies Structured Filters: It limits results to documents with a
statusof ‘published’ and those updated within the last 90 days. - Performs Semantic Search: It then orders the remaining documents by their semantic similarity to the
query_embedding. - Retrieves Metadata: It selects relevant structured metadata like
title,author, andupdated_at.
This approach significantly reduces infrastructure complexity and simplifies application logic. The primary tradeoff lies in performance at extreme scale. Dedicated vector databases are purpose-built for approximate nearest neighbor (ANN) search across billions of vectors and will generally outperform pgvector in such scenarios. However, for applications with corpora ranging from hundreds of thousands to a few million vectors, pgvector provides an excellent balance of functionality and operational simplicity, serving as a robust starting point with a clear option to migrate the vector workload to a dedicated store should scale demands necessitate it.
Strategic Database Selection and Future Implications
The decision framework for choosing between a dedicated vector database alongside a relational database, or leveraging a unified pgvector approach, is relatively straightforward. If an AI application is projected to operate on billions of vectors, demanding peak performance for semantic search, a dedicated vector store paired with a robust relational database is the optimal choice. Conversely, for applications operating at a moderate scale (up to several million vectors) where operational simplicity and a consolidated data layer are paramount, pgvector offers a highly compelling and efficient solution.
Regardless of the chosen vector storage mechanism, the relational layer remains non-negotiable. It is the unwavering foundation that manages users, enforces permissions, maintains application state, handles billing, and provides the structured metadata that grounds the semantic index in the real world. This dual-database strategy reflects a maturing phase in AI development, moving beyond experimental prototypes to robust, enterprise-grade solutions.
This evolution has significant implications for the industry. Database vendors are adapting rapidly, with traditional relational database providers enhancing their offerings with vector capabilities, and dedicated vector database companies exploring ways to incorporate more structured filtering and metadata management features. Developers, in turn, are increasingly required to possess a holistic understanding of both SQL and vector-based data management paradigms. The emphasis shifts from choosing a "best" database to selecting the "right" tool for each specific data task within a unified architecture.
Ultimately, the most resilient and performant AI architectures are not those that blindly adopt the newest technology but rather those that judiciously employ each data management tool precisely where its strengths are most pronounced. By integrating the semantic prowess of vector databases with the deterministic reliability of relational databases, organizations can construct AI applications that are not only intelligent and contextually aware but also secure, scalable, and operationally sound, ready for the demands of real-world production environments.