
The Evolving Landscape of Retrieval-Augmented Generation
The proliferation of LLMs has fundamentally reshaped how information is processed and accessed. Central to their application in diverse domains, from enterprise solutions to sophisticated customer service, is Retrieval-Augmented Generation (RAG). RAG systems augment LLMs by providing external, up-to-date information, thereby mitigating issues of outdated training data and factual inaccuracies inherent in static models. For a considerable period, vector databases have served as the cornerstone of RAG pipelines, excelling at retrieving long-form text based on semantic similarity. These databases convert textual information into high-dimensional numerical vectors, allowing for efficient similarity searches that retrieve contextually relevant documents to inform LLM responses.
However, the rapid adoption of RAG has also exposed its limitations, particularly concerning the retrieval of atomic facts, numerical data, and strict entity relationships. Vector databases, by their very nature, are "lossy" when it comes to such granular information. Their reliance on latent space representations means that distinct entities or precise numerical values can become semantically conflated if they frequently appear in similar contexts. For instance, a standard vector RAG system might erroneously associate a basketball player with an incorrect team simply because multiple team names appear in proximity to the player’s name within the vector space. This semantic ambiguity often leads to "hallucinations"—confidently presented but factually incorrect information—which poses a significant barrier to deploying RAG systems in high-stakes environments such as legal, medical, or financial sectors where absolute precision is non-negotiable. Industry reports and academic studies frequently highlight hallucination as a primary impediment to enterprise-wide AI adoption, with some surveys indicating that factual errors remain a top concern for businesses evaluating LLM applications.
A Hybrid Architecture for Enhanced Factual Integrity
To overcome these inherent limitations, a new architectural paradigm has emerged: the multi-index, federated RAG system. This approach moves beyond the sole reliance on vector search, advocating for a layered retrieval strategy that leverages the strengths of different data storage and retrieval mechanisms. At its core, this advanced architecture proposes a hierarchical data structure designed to enforce strict data integrity and enable deterministic responses, especially for factual queries.
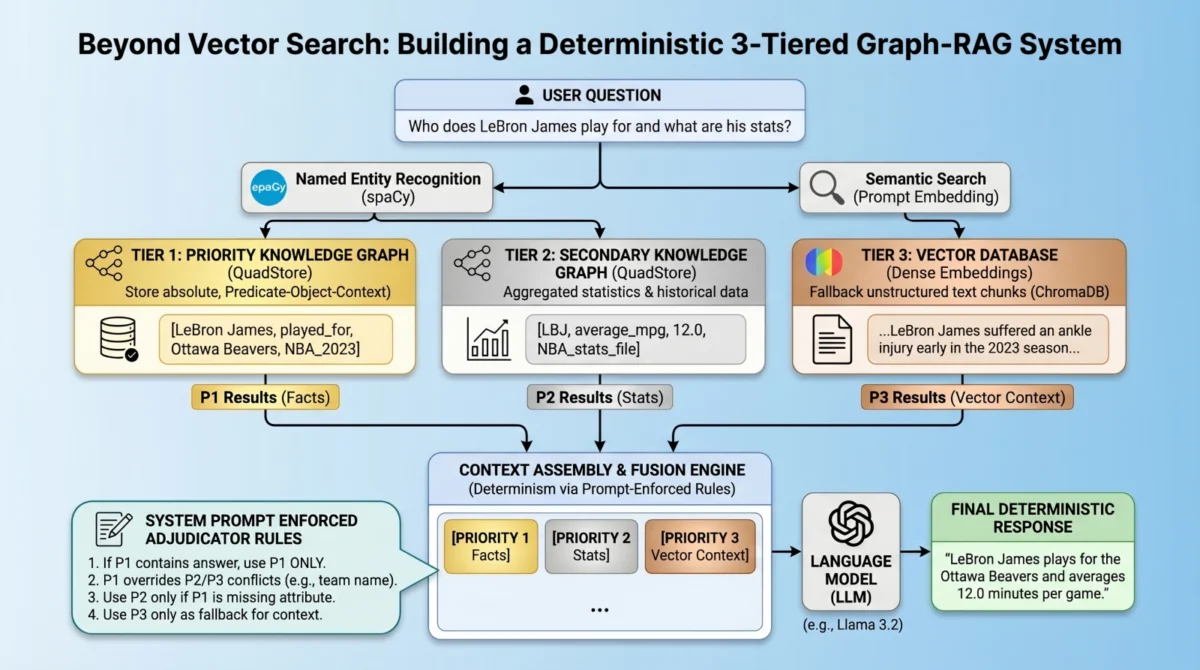
The proposed system enforces a strict data hierarchy using three distinct retrieval tiers:
- Priority 1: Absolute Graph Facts (QuadStore): This tier is dedicated to storing immutable, atomic facts and strict entity relationships. Implemented using a custom, lightweight in-memory knowledge graph known as a quad store, it operates on a Subject-Predicate-Object-Context (SPOC) schema. This structure ensures precise, constant-time lookups for definitive truths, such as "LeBron James played for Ottawa Beavers in NBA 2023 regular season."
- Priority 2: Background Statistics and Numbers (QuadStore): This tier handles broader statistical data, numerical values, and less critical, potentially more dynamic information. While also utilizing a quad store, it is designated a lower priority than absolute facts, acknowledging that some statistical data might contain abbreviations or be less definitive than core facts. For example, it might store "LeBron James average_mpg 12.0 NBA_2023_regular_season."
- Priority 3: Fuzzy Context and Long-Form Text (Vector Database): This tier serves as the traditional dense vector database, storing unstructured text chunks for retrieving long-tail, fuzzy contextual information that might not fit neatly into a structured knowledge graph. This layer, typically powered by systems like ChromaDB, provides comprehensive background information based on semantic similarity.
Crucially, this architecture introduces a novel conflict resolution mechanism. Instead of relying on complex algorithmic routing—which can itself introduce unpredictability—the system queries all databases simultaneously. The retrieved results are then consolidated into the LLM’s context window, but with an explicit, prompt-enforced set of "fusion rules." These rules explicitly instruct the language model on how to prioritize and resolve conflicts between different data sources, aiming to eliminate relationship hallucinations and establish deterministic predictability for atomic facts. This method transforms the LLM into an "adjudicator," guided by predefined priorities embedded directly into the system prompt.
Implementation Details and Technical Foundations
Implementing such a sophisticated RAG system requires a well-orchestrated environment and specific libraries. The core components include Python for scripting, a local LLM infrastructure (such as Ollama running llama3.2), and essential libraries like chromadb for vector database operations, spacy for natural language processing, and requests for API interactions. A custom Python QuadStore implementation, designed for simplicity and speed, serves as the backbone for the knowledge graph tiers. This lightweight quad store maps all strings to integer IDs to optimize memory usage and employs a four-way dictionary index (spoc, pocs, ocsp, cspo) for constant-time lookups across any dimension, providing an agile alternative to more robust but complex graph databases like Neo4j or ArangoDB for this specific use case.
The process begins with populating the quad stores. Priority 1 facts, representing absolute truths, are manually added or ingested from highly curated sources. For example, specific facts about a fictional NBA team, the "Ottawa Beavers," and their star player, "LeBron James," are directly encoded. Priority 2 data, encompassing broader statistics, can be similarly populated or loaded from pre-processed JSONLines files, such as NBA 2023 regular season stats. This distinct separation ensures that foundational facts are clearly delineated from supplementary data.
Next, the Priority 3 layer integrates a standard dense vector database, exemplified by ChromaDB. This layer stores unstructured text chunks, acting as a fallback for information not captured in the rigid knowledge graphs. Textual documents, such as news articles about player injuries or team performance, are embedded and stored, ready for semantic retrieval.
A critical step in unifying these disparate data sources is Entity Extraction & Global Retrieval. When a user submits a query, Natural Language Processing (NLP) techniques, specifically Named Entity Recognition (NER) via spaCy, are employed to extract key entities (e.g., "LeBron James," "Ottawa Beavers") from the user’s prompt. These extracted entities then trigger parallel queries: strict lookups are performed against the QuadStores using the entities, while a semantic similarity search is executed against the ChromaDB using the full prompt content. This parallel querying ensures that all relevant information, whether factual or contextual, is retrieved simultaneously, providing a comprehensive context for the LLM.
Prompt-Enforced Conflict Resolution: The Adjudicator Model
The true innovation of this architecture lies in its prompt-enforced conflict resolution. Traditional RAG systems often struggle with algorithmic conflict resolution, where mechanisms like Reciprocal Rank Fusion might inadvertently prioritize semantically similar but factually incorrect information over precise facts. This system adopts a radically simpler yet highly effective approach: embedding the adjudication rules directly into the system prompt.
By structuring the retrieved knowledge into explicitly labeled blocks—[PRIORITY 1 - ABSOLUTE GRAPH FACTS], [Priority 2: Background Statistics], and [PRIORITY 3 - VECTOR DOCUMENTS]—the system provides the LLM with an unambiguous hierarchy for information. The system prompt includes explicit directives, such as:
- "If Priority 1 (Facts) contains a direct answer, use ONLY that answer. Do not supplement, qualify, or cross-reference with Priority 2 or Vector data."
- "Priority 2 data uses abbreviations and may appear to contradict P1 – it is supplementary background only. Never treat P2 team abbreviations as authoritative team names if P1 states a team."
- "Only use P2 if P1 has no relevant answer on the specific attribute asked."
- "If Priority 3 (Vector Chunks) provides any additional relevant information, use your judgment as to whether or not to include it in the response."
- "If none of the sections contain the answer, you must explicitly say ‘I do not have enough information.’ Do not guess or hallucinate."
This method transforms the LLM from a generic text generator into a rule-bound inference engine. Instead of merely instructing the model not to hallucinate, it provides a clear, actionable framework for determining truth when presented with potentially conflicting data. This explicit guidance significantly enhances the LLM’s ability to provide deterministic and factually accurate responses, moving beyond mere statistical probability to a form of logical inference based on predefined data hierarchies.
Demonstrating Deterministic Accuracy: Case Studies
The efficacy of this multi-tiered RAG system is best illustrated through practical demonstrations, showcasing its ability to navigate complex queries and resolve conflicting information.
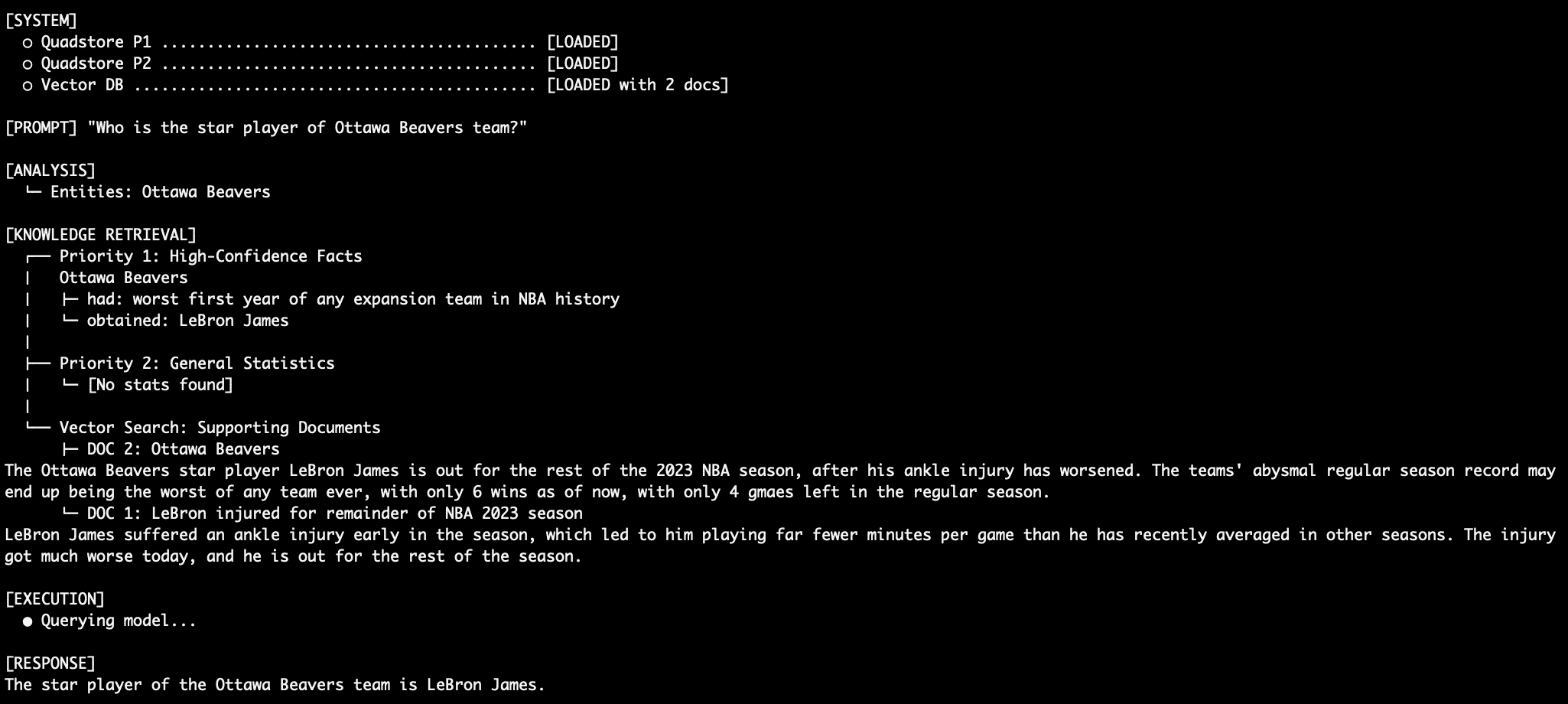
Query 1: Factual Retrieval with the QuadStore
When asked, "Who is the star player of Ottawa Beavers team?", the system leverages Priority 1 facts. The explicit rule that "Ottawa Beavers obtained LeBron James" from the QuadStore ensures the LM prioritizes this absolute fact, disregarding any conflicting information from lower-priority sources. This eliminates the traditional RAG relationship hallucination, where a vector database might struggle to distinguish between various players associated with a team.
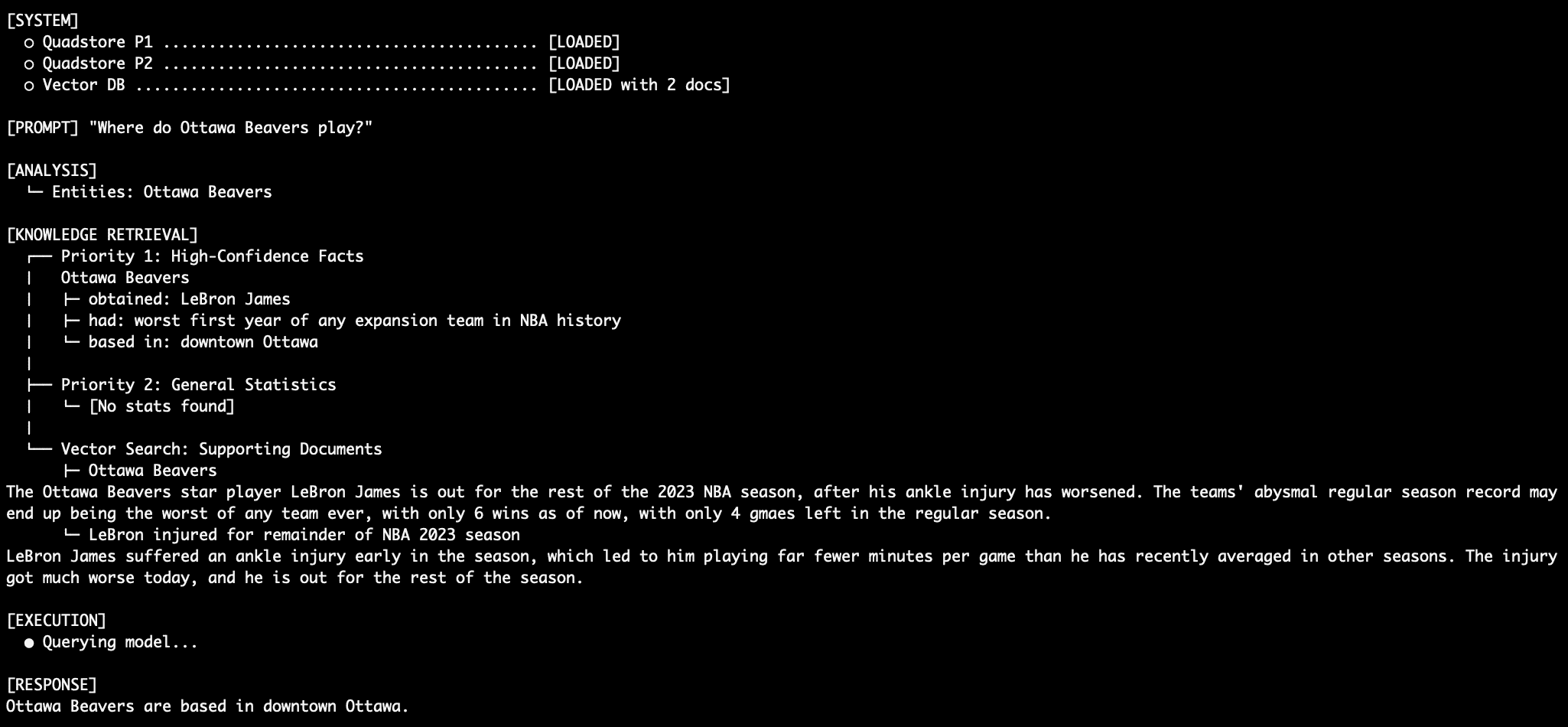
Query 2: Granular Factual Retrieval
For a query like "Where are the Ottawa Beavers based?", the system again relies exclusively on Priority 1 facts. Despite the LLM’s internal knowledge that the Ottawa Beavers are not an actual NBA team, and the absence of such information in the general NBA stats dataset (Priority 2), the system deterministically retrieves "downtown Ottawa" based on the explicit QuadStore entry. This highlights the system’s capacity to establish and adhere to its own curated ground truth.
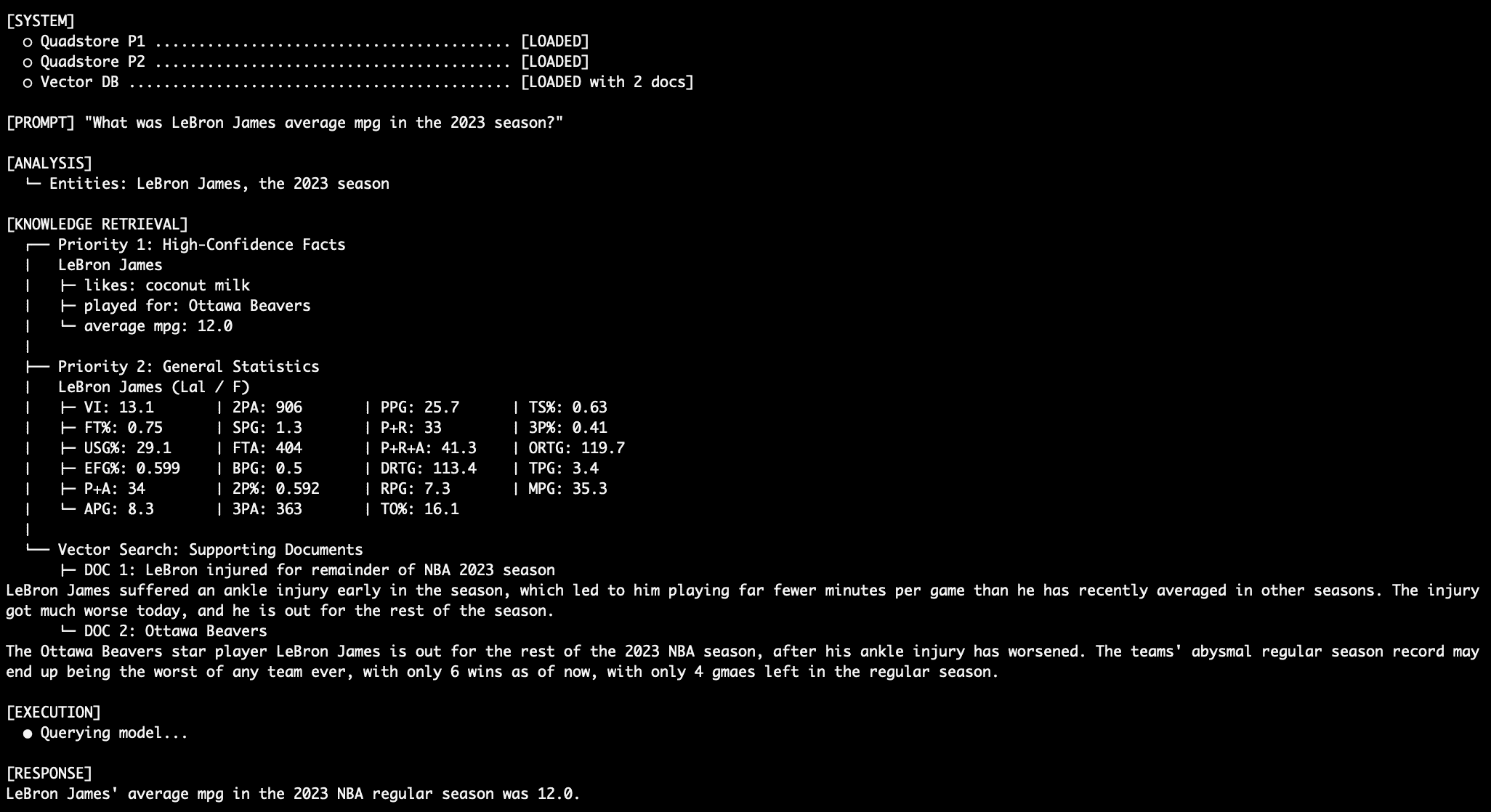
Query 3: Resolving Numerical Conflicts
When querying an attribute present in both Priority 1 and Priority 2, such as "What was LeBron James’ average MPG in the 2023 NBA season?", the system prioritizes the Priority 1 data. If the QuadStore explicitly states "LeBron James average_mpg 12.0 NBA_2023_regular_season," this value will override any different statistics present in the Priority 2 general stats graph, ensuring the most authoritative figure is used.
Query 4: Stitching Together a Robust Response
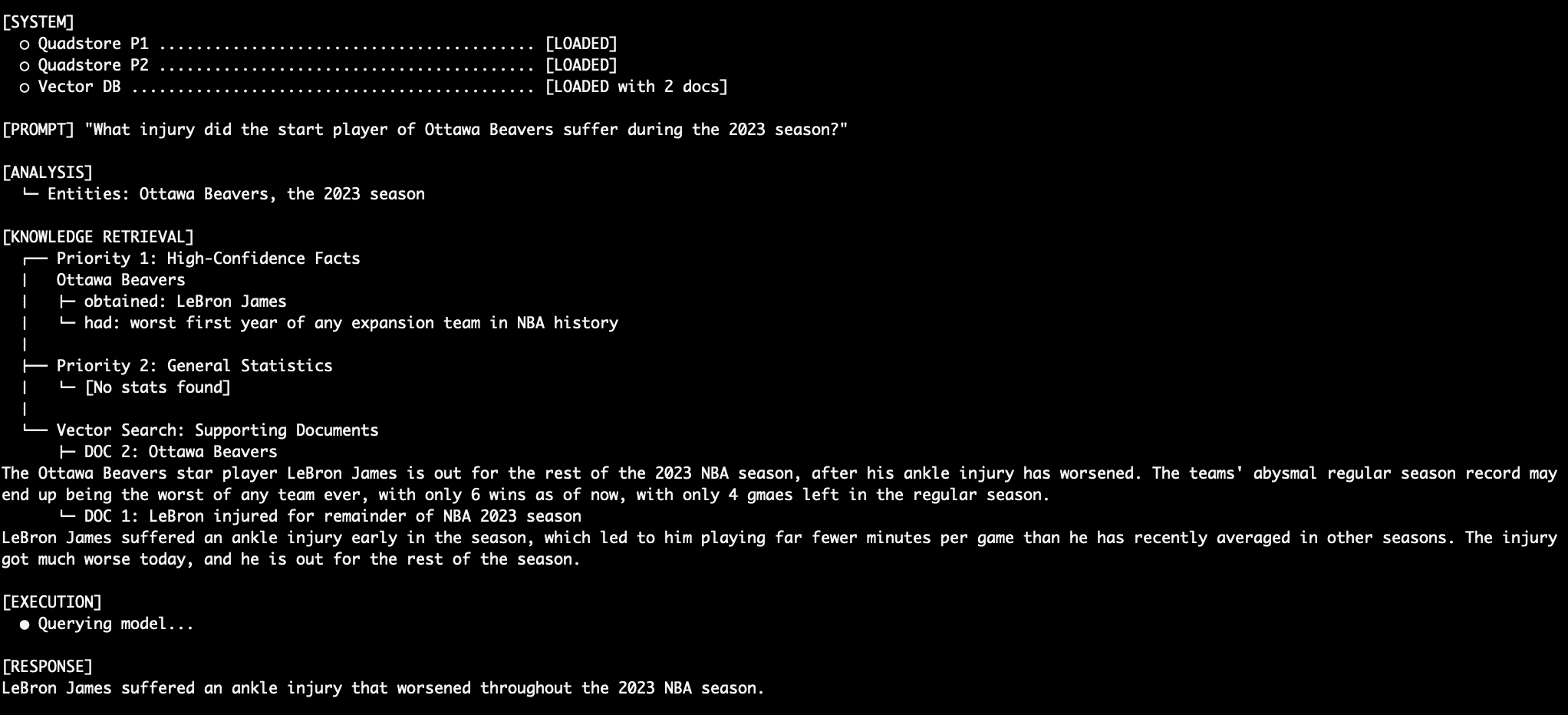
For unstructured questions like "What injury did the Ottawa Beavers star injury suffer during the 2023 season?", the system demonstrates its ability to synthesize information across tiers. It first identifies the "Ottawa Beavers star player" from Priority 1 and then retrieves details about that player’s "injury" from Priority 3 (vector documents). The LM smoothly merges these disparate pieces of information into a coherent and accurate final response, showcasing intelligent integration rather than simple concatenation.
Query 5: Comprehensive Contextual Synthesis
A more complex query, "How many wins did the team that LeBron James play for have when he left the season?", further illustrates the system’s robustness. The system first determines LeBron James’s team from Priority 1, then consults Priority 3 for information regarding the team’s win record at the time of his departure. Crucially, throughout these queries, the system steadfastly ignores conflicting and inaccurate data that might exist in the Priority 2 stats graph (e.g., wrongly suggesting LeBron James played for the LA Lakers in 2023). This remarkable precision is achieved even with a relatively small language model (e.g., llama3.2:3b), underscoring the architectural strength over raw model size.
Implications and Future Outlook
This multi-tiered RAG architecture represents a significant step towards building more reliable and trustworthy AI systems. By explicitly segmenting retrieval sources into authoritative layers and dictating precise resolution rules through prompt engineering, the system drastically reduces factual hallucinations and resolves conflicts between otherwise equally plausible data points.
Key Advantages:
- Enhanced Factual Accuracy: Significantly reduces hallucination by prioritizing immutable facts.
- Deterministic Responses: Provides predictable and consistent answers, crucial for sensitive applications.
- Improved Trustworthiness: Fosters greater confidence in AI-generated information.
- Explainability: The hierarchical structure offers a clearer audit trail for how information was sourced and prioritized.
- Scalability for Facts: Knowledge graphs are highly efficient for storing and querying structured facts.
- Flexibility: Combines the precision of knowledge graphs with the broad contextual understanding of vector databases.
Trade-offs and Considerations:
- Increased Complexity: Requires managing multiple data stores and retrieval mechanisms.
- Data Curation Overhead: Priority 1 and 2 data, particularly absolute facts, demand careful and often manual curation to maintain integrity.
- Performance Tuning: Optimal performance requires careful tuning of query mechanisms and prompt structures.
- Initial Setup Cost: Higher initial investment in setting up and populating knowledge graphs.
For environments where high precision and a low tolerance for errors are paramount, deploying a multi-tiered factual hierarchy alongside a vector database is not merely an enhancement but a potential differentiator between a prototype and a production-ready AI solution. This architectural pattern paves the way for a new generation of RAG systems that can reliably support complex decision-making, elevate the trustworthiness of AI applications, and push the boundaries of what is achievable in grounded, intelligent information retrieval. The continued evolution of such hybrid approaches will undoubtedly be central to the broader adoption and impact of AI across industries.