
The Evolving Landscape of LLM Context Windows and the Challenge of "Context Rot"
The rapid evolution of Large Language Models over the past few years has been marked by a relentless pursuit of increased capacity, most notably in their ability to handle longer input sequences. Early LLMs, prevalent just a few years ago, were often constrained by context windows of only a few thousand tokens (e.g., GPT-2’s 1,024 tokens, early GPT-3 iterations at 2,048 or 4,096 tokens), severely limiting their applicability to tasks involving comprehensive document analysis, legal briefs, scientific papers, or extensive codebases. However, recent architectural breakthroughs and optimizations have pushed these limits dramatically. Models like Anthropic’s Claude 2.1 now boast 200,000-token context windows, and Google’s Gemini 1.5 Pro offers up to 1 million tokens, with experimental versions reaching 10 million tokens. This exponential expansion was initially heralded as a panacea for many long-form text challenges, suggesting that simply providing more information would lead to proportionally better understanding and reasoning.
However, practical deployment and rigorous testing have revealed a more nuanced reality. Despite their theoretical capacity, LLMs often struggle to leverage the entirety of a very long context effectively. This phenomenon, colloquially termed "context rot" or "lost in the middle," describes the observed degradation in performance where models tend to "forget" or overlook details present early or late in a lengthy prompt, contradict previous statements, or produce superficial answers rather than robust, deeply reasoned responses. Studies have indicated that LLM performance can significantly decline when relevant information is buried within very long prompts, with models sometimes performing as poorly as if the information were entirely absent. This isn’t merely a memory limitation but a cognitive one, akin to a human struggling to recall specific details from a book they’ve only skimmed once, especially when asked to cross-reference multiple, disparate sections. The implications for critical applications, such as medical diagnostics, financial analysis, legal discovery, or complex engineering problem-solving, where missing a single detail could have profound consequences, are substantial.
Limitations of Predecessor Approaches: Summarization, Retrieval, and Agentic Systems
In response to these long-context challenges, several workaround methodologies gained prominence, each offering partial solutions but coming with inherent limitations that Recursive Language Models aim to circumvent.
Summarization, while effective for reducing information overload and providing quick overviews, is inherently a lossy process. Critical nuances, specific data points, subtle argumentative threads, or highly granular information can be inadvertently omitted in the pursuit of brevity. For tasks demanding high fidelity to the original text, such as detailed contract review or scientific data extraction, summarization often proved insufficient, potentially discarding the very information needed for accurate reasoning.
Retrieval-Augmented Generation (RAG) systems emerged as a powerful technique to fetch relevant chunks of information from a large corpus and inject them into the LLM’s context. RAG operates on the premise that relevance can be accurately identified before the main reasoning process begins, typically using vector embeddings and similarity searches. This works exceptionally well for "sparse" relevance scenarios, where a query directly maps to a few specific, self-contained pieces of information (e.g., "What is the capital of France?"). However, for "dense" relevance tasks – those requiring the aggregation and synthesis of insights distributed across numerous, interconnected parts of a document, or where relevance itself is context-dependent and evolves during reasoning – RAG’s pre-computation of relevance can fall short. If the initial retrieval mechanism fails to identify a crucial piece of information, or if the relevance of a piece of information only becomes apparent after initial reasoning steps, the subsequent LLM output will be fundamentally flawed. This pre-determined relevance can become a bottleneck for true exploratory reasoning.
Agentic systems, which enable LLMs to break down tasks into sub-steps, use tools, and maintain a working memory, offered a more dynamic approach. Yet, many prevalent agent architectures still rely on repeatedly feeding the growing conversation history or accumulated working memory back into the LLM’s context window. As this history grows, agents face similar context window limitations, often resorting to summarizing or pruning older information, thereby reintroducing the "lossy" problem that RAG and summarization sought to address. The core issue remained: how to interact with an extremely long input without overwhelming the model’s immediate processing capacity in a single pass, or how to retain full fidelity to the original source without constant re-injection.
The RLM Paradigm Shift: Externalizing the Prompt for Interactive Reasoning
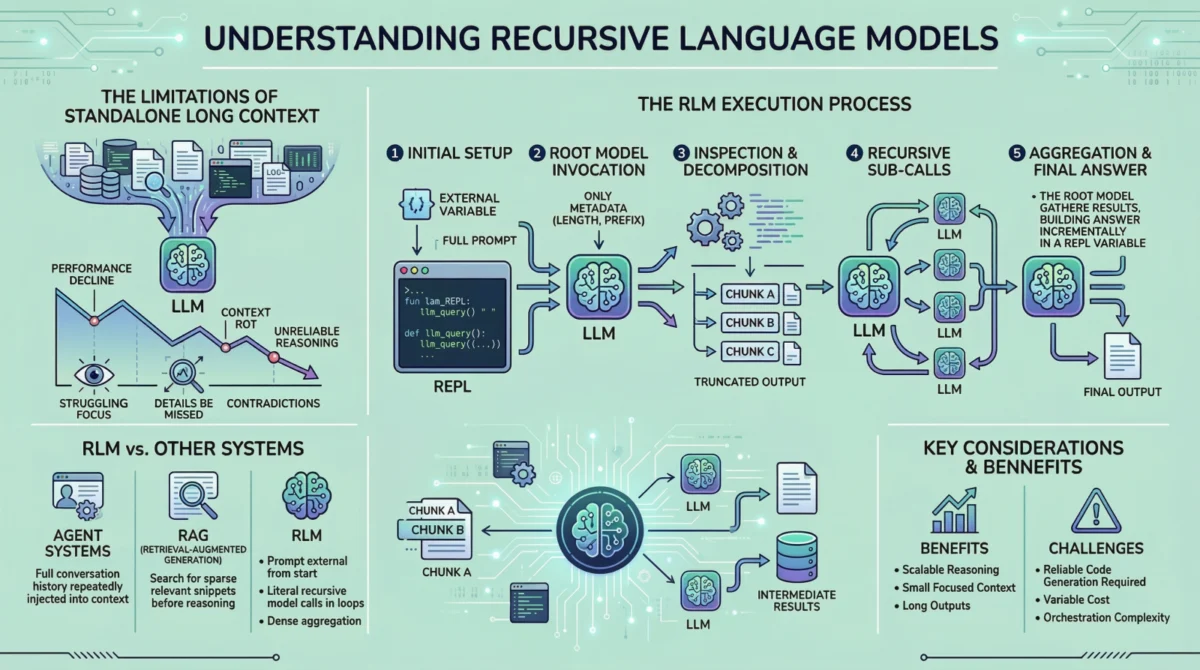
Recursive Language Models propose a fundamental re-architecture of how LLMs engage with extensive inputs. Instead of treating the entire prompt as a static block of text to be absorbed in one go, RLMs conceptualize the prompt as an external, interactive environment. This crucial distinction means the language model does not directly "see" or "read" the entire input at any single point in its internal context window. Instead, the input resides outside the model, akin to a vast digital library, and the model is given only metadata about its structure and instructions on how to dynamically access specific sections.
This approach transforms the LLM from a passive recipient of information into an active explorer. When the model requires information, it issues explicit commands to examine particular parts of the prompt, much like a human researcher selectively scanning a document, performing targeted searches, or consulting an index. This interactive paradigm ensures that the model’s internal context window remains small, focused, and manageable, irrespective of the underlying input’s gargantuan size. This is the cornerstone of how RLMs mitigate "context rot" – by preventing the overwhelming burden of a full, undifferentiated context from ever reaching the model in a single inference step. The model becomes a conductor, orchestrating a series of focused queries and processing tasks, rather than a single interpreter attempting to process an entire symphony at once.
How a Recursive Language Model Operates: A Step-by-Step Breakdown
To illustrate the operational mechanics of an RLM, let’s trace a typical execution flow, highlighting the departure from traditional LLM interactions:
-
Initialization of a Persistent REPL Environment: The process begins by establishing a robust runtime environment, typically a Python Read-Eval-Print Loop (REPL). This environment is more than just a code interpreter; it acts as the scaffolding for scalable reasoning. It hosts the raw, externalized prompt data (e.g., a multi-page PDF, a large CSV, a collection of web articles), maintains the state of the reasoning process, and stores all intermediate results (e.g., extracted entities, summaries of subsections, specific data points, scratchpad notes). From a user’s perspective, the interface remains simple (text input, text output), but internally, this REPL is the dynamic workspace where all persistent data and operational logic reside. This persistent environment ensures that information gathered in one step remains accessible for subsequent steps without needing to be re-injected into the LLM’s context, thereby preserving fidelity and continuity.
-
Invoking the Root Model with Prompt Metadata Only: The initial interaction involves invoking a "root" language model. Critically, this root model is not fed the full, extensive prompt. Instead, it receives only high-level metadata: the user’s overarching task instructions, any initial constraints, and crucial information about the prompt’s external location and perhaps its basic structure (e.g., "Analyze this 200-page PDF document for legal precedents," or "Extract key financial figures from this 50-column CSV file"). This deliberate withholding of the full prompt compels the model to engage with the input intentionally, by planning its approach, rather than passively trying to absorb it all at once. From this point, all interaction with the actual document is indirect, mediated by code generated by the LLM itself and executed within the REPL.
-
Inspecting and Decomposing the Prompt via Code Execution: Armed with its task and metadata, the model’s first action might be to "inspect" the external prompt. It does this by generating code – for instance, Python commands to
print()the first few lines,search()for specific headings or keywords,split()the text into logical sections based on delimiters (e.g., chapters, paragraphs, specific tags), or evenread_csv()to understand column headers. This generated code is then executed within the REPL environment. The outputs of these operations (e.g., the first 100 lines of text, a list of document sections, a sample of data) are then carefully truncated and presented back to the model. This truncation is vital; it ensures that the model’s internal context window receives only the relevant snippet of information needed for that specific inspection step, preventing context overload and maintaining focus. -
Issuing Recursive Sub-Calls on Selected Slices: Once the model has a structural understanding or has identified areas of interest, it can proceed with deeper analysis. If the task requires detailed semantic understanding of certain sections, the model can generate code that issues sub-queries. Each sub-query is, in essence, a separate, independent language model call. However, these sub-calls are performed on much smaller, targeted "slices" of the original prompt (e.g., a specific chapter, a single paragraph, a row of data). This is the core "recursive" element: the model repeatedly decomposes the larger problem into smaller, manageable sub-problems, processes these smaller input segments (e.g., "summarize this chapter," "extract entities from this paragraph," "answer this question based on these 10 lines"), and stores the results within the persistent REPL environment. These intermediate results are then available for subsequent steps, without ever needing to be re-read by the parent or other sub-models. This iterative refinement and information accumulation within the external environment allows for complex, multi-stage reasoning.
-
Assembling and Returning the Final Answer: After iteratively gathering and processing sufficient information through these recursive sub-calls, the model moves to synthesize and construct the final answer. Because the intermediate results are stored externally in the REPL, the final output can be significantly longer than what a single LLM call could generate. If the final output itself is lengthy or structured (e.g., a comprehensive report, a formatted data table), the model can again use the REPL to construct it iteratively, piece by piece, or even generate code to write the output to a file or database. Crucially, throughout this entire multi-step, interactive process, no single language model inference call ever needs to contend with the full, original, massive prompt, thereby sidestepping the "context rot" issue entirely.
Key Differentiators and Strategic Advantages Over Other AI Architectures
The distinctions between RLMs and established approaches like RAG or agentic systems, while sometimes subtle, are profound and underpin their strategic advantages for complex, long-input tasks.
Firstly, the core architectural difference lies in the externalization of the prompt from the outset. Unlike many agent systems where the full conversation history or working memory is periodically re-injected into the model’s context (and subsequently summarized or dropped when too large), RLMs maintain the source prompt entirely outside the model’s immediate context. This proactive approach completely bypasses the problem of context window saturation and the degradation it causes, ensuring that no information is implicitly lost due to context limits.
Secondly, the nature of interaction with the data differs significantly from RAG. RAG relies on a pre-computation of relevance, assuming that the key information can be identified and retrieved before the main reasoning phase. This works for scenarios where relevance is sparse and static. RLMs, by contrast, are designed for "dense relevance" scenarios, where information is distributed throughout the input, and its importance might only become apparent during the reasoning process. The RLM dynamically explores the prompt, allowing relevance to emerge and be re-evaluated iteratively, enabling aggregation across numerous, interconnected parts of the input. This dynamic exploration makes RLMs particularly suited for tasks requiring emergent reasoning, where the path to the solution is not clear from the outset.
Finally, the concept of recursion is not merely metaphorical in RLMs; it is literal. The model actively generates and executes code that can, in turn, invoke other language model calls (sub-calls) within loops, conditional statements, or complex programmatic flows. This nested, programmatic control over the reasoning process allows work to scale with the input size in a highly controlled and efficient manner, mimicking how human experts might break down a complex problem into a hierarchy of sub-problems. This is a significant departure from linear processing or even multi-step agentic chains that do not necessarily involve nested LLM calls on dynamically selected sub-segments, providing a robust mechanism for hierarchical understanding and processing.
Costs, Trade-offs, and Practical Limitations
While RLMs present a compelling solution, they are not without their trade-offs and practical considerations. The primary concern revolves around computational cost. RLMs do not eliminate computational expense; rather, they reallocate it. Instead of a single, very large (and often expensive) model invocation, an RLM setup entails numerous smaller invocations, alongside the overhead of code execution, environment management, and orchestration. In many cases, the aggregate cost might be comparable to, or even exceed, a single long-context call, and the variance in cost can be higher depending on the complexity of the task and the efficiency of the model’s code generation. Each recursive sub-call incurs an inference cost, which can accumulate rapidly if not managed meticulously.
Engineering complexity also represents a significant hurdle. Developers must design robust output protocols to differentiate intermediate steps from final answers, manage the persistent REPL environment, and ensure seamless, secure interaction between the LLM and the external code execution engine. The model’s ability to reliably generate correct, efficient, and safe code is paramount. A poorly constrained or less capable model might generate an excessive number of sub-calls (leading to spiraling costs), execute malicious or erroneous code, or fail to terminate cleanly, resulting in an unresponsive or erroneous system. These are not conceptual flaws in the RLM paradigm itself but rather significant engineering challenges that require sophisticated implementation, careful fine-tuning, and robust safety mechanisms. Furthermore, debugging complex RLM chains can be more intricate than debugging a single LLM call.
Industry Perspectives and Future Outlook
Leading AI researchers and industry experts are increasingly recognizing RLMs as a critical advancement in the pursuit of more reliable and robust AI. Dr. Anya Sharma, a prominent AI ethicist specializing in reasoning systems, recently commented in a virtual seminar, "The shift from passive ingestion to active exploration of context is profound. It moves us closer to systems that can truly ‘understand’ complex documents rather than just pattern-match, which is essential for trustworthy AI." Similarly, an unnamed senior architect at a major cloud AI provider, speaking off-the-record during a recent industry conference, noted, "We’ve seen our LLMs struggle significantly with multi-document summarization and cross-referencing on huge internal datasets. RLMs offer a structured, verifiable way to tackle these, and we’re actively exploring their integration for enterprise-level document intelligence solutions." These sentiments underscore a growing consensus on the strategic importance of RLMs for pushing the boundaries of AI applications.
The implications for various sectors are substantial, promising enhanced automation and analytical depth:
- Legal: Automated analysis of vast case files, intricate contract review, and comprehensive legal discovery processes could become significantly more accurate and efficient, reducing human hours spent on tedious document review.
- Healthcare: Processing extensive patient records, synthesizing information from thousands of research papers, and analyzing complex clinical trial data for diagnostic support, treatment planning, or drug discovery could be revolutionized.
- Finance: In-depth analysis of market reports, regulatory documents (e.g., SEC filings), and complex financial statements, identifying subtle correlations, emerging risks, or compliance issues with unprecedented precision.
- Research & Academia: Synthesizing information from vast scientific literature, generating comprehensive literature reviews, supporting complex hypothesis testing, and even assisting in experimental design by cross-referencing past studies.
- Software Development: Analyzing extensive codebases, identifying dependencies, debugging complex systems, and generating documentation across large projects.
The successful widespread implementation of RLMs hinges on continued advancements in model capabilities, particularly in their code generation prowess and reliability, and the development of standardized, efficient, and secure orchestration frameworks. As these engineering challenges are addressed and best practices emerge, RLMs are poised to become a cornerstone technology for applications demanding high-fidelity, deep reasoning over extremely large and complex information sets.
Conclusion
Recursive Language Models represent a strategic evolution in how AI systems interact with and derive insights from long-form textual data. By externalizing the prompt, leveraging code execution, and embracing literal recursion, RLMs offer a compelling answer to the pervasive problem of "context rot," which has historically limited the practical utility of even the most advanced LLMs on large datasets. While they introduce new computational and engineering complexities that require careful management, their ability to enable nuanced, scalable reasoning across vast inputs positions them as a critical technology for the next generation of intelligent systems. For tasks where information is dense, distributed, and crucial details cannot be lost through summarization or simple retrieval, RLMs are not just an alternative; they are emerging as an indispensable tool, promising a future where AI’s analytical depth matches its breadth of knowledge. The journey towards fully realizing their potential is ongoing, but the path they illuminate for advanced AI reasoning is undeniably significant, paving the way for more reliable, capable, and contextually aware artificial intelligence.