
The landscape of machine learning is undergoing a significant transformation as Large Language Models (LLMs) extend their utility beyond conversational interfaces to revolutionize fundamental data preprocessing tasks. A recent demonstration highlights the increasing capability of pre-trained LLMs to efficiently extract structured features from raw, unstructured text, subsequently integrating these derived insights with existing numeric data to empower sophisticated supervised classifiers. This methodology marks a critical advancement in feature engineering, promising to unlock deeper analytical potential from vast reservoirs of textual information that were previously challenging to leverage effectively in traditional tabular machine learning models.
The Evolution of Feature Engineering from Text
For decades, data scientists have grappled with the challenge of converting the rich, nuanced information embedded in unstructured text into a format amenable to machine learning algorithms. Early approaches to text feature engineering primarily relied on statistical methods such as Bag-of-Words (BoW) and Term Frequency-Inverse Document Frequency (TF-IDF), which quantify word occurrences but largely ignore semantic context. The advent of deep learning brought about more sophisticated techniques like Word2Vec, GloVe, and FastText, enabling the creation of word embeddings that capture some semantic relationships. However, these methods often required significant manual effort, domain expertise, and complex pipelines to extract specific, high-level attributes like sentiment, urgency, or specific entities from text. The process remained largely labor-intensive, often leading to a bottleneck in projects where textual data was abundant but hard to operationalize.
The recent explosion in the capabilities of Large Language Models, particularly those based on the Transformer architecture, represents a paradigm shift. Models from families like Llama, accessible through high-performance inference providers such as Groq, have demonstrated an unprecedented ability to understand, interpret, and generate human-like text. Crucially, this understanding extends to identifying and extracting specific pieces of information, even when expressed in varied and complex linguistic forms. This inherent semantic comprehension positions LLMs as powerful, automated tools for feature engineering, capable of transforming amorphous text into precise, structured data points.
A New Paradigm: LLMs as Intelligent Data Extractors
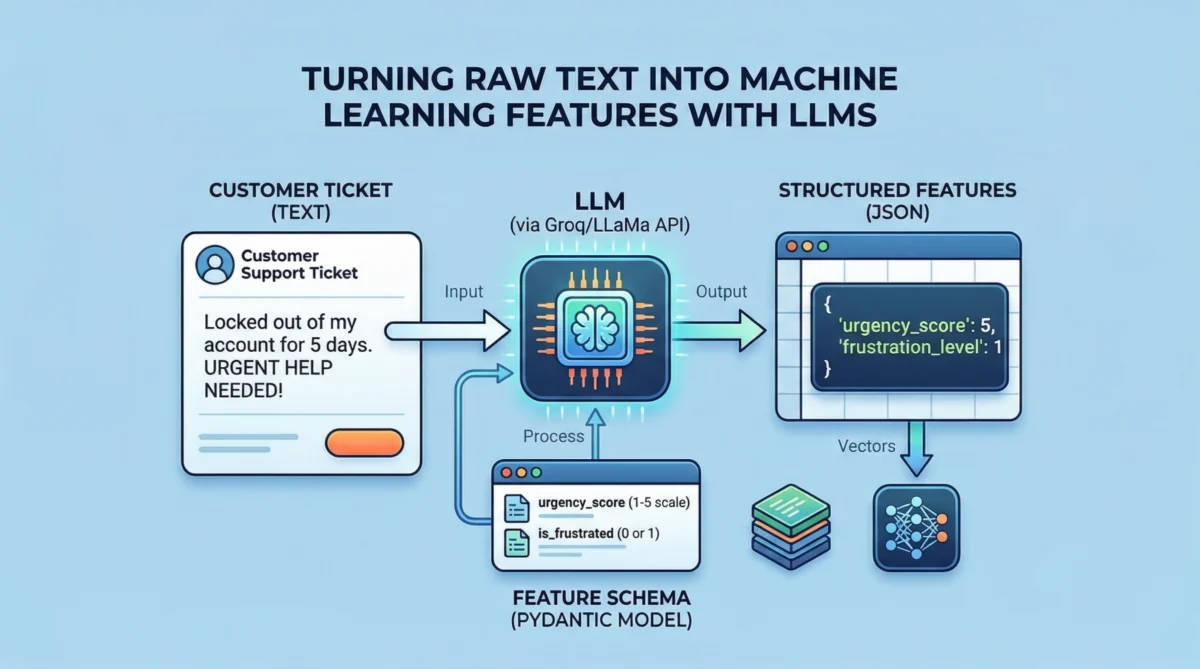
The core innovation lies in leveraging LLMs not for generating conversational responses, but as highly intelligent extraction agents. By providing a clear schema defining the desired output, LLMs can parse natural language inputs and return information in a structured, machine-readable format, typically JSON. This process significantly streamlines the creation of features that might otherwise require complex rule-based systems or extensive manual annotation.
Consider the typical flow: a dataset contains customer support tickets, comprising both free-form text descriptions and structured numeric data, such as account_age_days and prior_tickets. The objective is to build a classifier that can accurately categorize these tickets. While the numeric features are immediately usable, the text field, despite containing critical diagnostic information, remains unstructured. This is where the LLM intervenes. Instead of traditional NLP methods, an LLM is prompted to analyze the text and extract specific attributes relevant to the classification task. For instance, in customer support, attributes like urgency_score (on a scale of 1-5) and is_frustrated (binary: 0 or 1) can be highly indicative of the ticket’s nature and required response.
The implementation involves defining these desired features using a data modeling library like Pydantic, which allows for the creation of Python classes that double as schema definitions. These schemas, when converted to JSON, provide explicit instructions to the LLM regarding the expected output structure and data types. For example, TicketFeatures might define urgency_score as an integer with a description "Urgency of the ticket on a scale of 1 to 5" and is_frustrated as a binary integer.
The Technical Workflow: From Prompt to Tabular Data
The practical application of this technique involves a few key steps:
-
API Client Setup: Modern LLM APIs, including Groq’s fast inference endpoints for Llama models, often adopt interface styles compatible with widely used libraries like
openai. This standardization allows data scientists to interact with various LLM providers using a single, familiar client, simplifying integration. Secure handling of API keys, typically through environment variables or secret management tools (like Google Colab’s "Secrets"), is paramount. -
Dataset Preparation: While real-world datasets are preferred, synthetic datasets, like the customer support ticket example with categories such as "access," "inquiry," "software," "billing," and "hardware," serve as excellent illustrative tools. These datasets combine textual descriptions with pre-existing numeric features and a target label, simulating the mixed-modality data common in enterprise environments. The synthetic nature, while efficient for demonstration, naturally leads to a less robust classifier performance due to limited scale and inherent randomness, a crucial point often missed in rapid prototyping.
-
Schema-Guided Extraction: The defined Pydantic schema is then serialized into a JSON string and embedded within a system prompt. This prompt instructs the LLM to act as an "extraction assistant" and to output only valid JSON conforming to the provided schema. When a customer ticket’s text is passed to the LLM as the user prompt, the model processes it and returns a JSON object containing the extracted
urgency_scoreandis_frustratedvalues. This structured output is critical for seamless integration. -
Feature Integration: The JSON objects returned by the LLM for each text entry are then converted into a DataFrame. This new DataFrame, containing the LLM-engineered features, is subsequently concatenated with the original DataFrame (which holds the numeric features and the target label), creating a comprehensive, fully tabular dataset ready for machine learning. This hybrid dataset now combines the explicit numeric context with the nuanced, semantically rich features extracted from the text, offering a more complete picture for predictive modeling.
Operational Considerations for Enterprise Deployment
While the per-row LLM call effectively demonstrates the principle, scaling this approach for large datasets in a production environment requires careful consideration of cost, latency, and reliability. Key strategies include:
- Batching Requests: Instead of one API call per text entry, multiple entries can often be processed in a single batch request, significantly reducing overhead and improving throughput.
- Caching Results: For static or slowly changing text data, caching the LLM’s extraction results based on a stable identifier or a hash of the text prevents redundant API calls, saving costs and speeding up subsequent runs.
- Retries with Exponential Backoff: API services can experience transient errors or rate limiting. Implementing robust retry mechanisms with exponential backoff ensures resilience and prevents job failures due to temporary network or service issues.
- Monitoring and Governance: Continuous monitoring of LLM output quality and adherence to schemas is essential. Furthermore, establishing clear data governance policies for text data processed by external LLMs is crucial, especially when dealing with sensitive information.
Impact and Implications for Data Science and Industry
The ability to programmatically and efficiently derive structured features from unstructured text using LLMs carries profound implications across various industries:
- Enhanced Predictive Accuracy: By integrating rich, context-aware features like urgency, sentiment, or specific entities, machine learning models can achieve higher accuracy in classification and regression tasks. For instance, a customer support ticket classifier can better prioritize urgent issues, leading to improved response times and customer satisfaction.
- Operational Efficiency: Automating the feature engineering process drastically reduces the manual effort and time traditionally spent on data preparation, allowing data scientists to focus on model development, analysis, and deployment. This acceleration of the ML pipeline translates directly into faster time-to-insight and quicker deployment of AI solutions.
- Democratization of Text Analytics: This methodology lowers the barrier for entry into advanced text analytics. Data scientists without deep NLP expertise can now leverage state-of-the-art LLMs to extract valuable information from text, making text-rich data more accessible to a broader range of ML practitioners.
- New Business Insights: Previously untapped or underutilized textual data—from customer reviews and social media posts to internal documents and research papers—can now be systematically converted into structured features. This unlocks new avenues for business intelligence, market trend analysis, risk assessment, and personalized customer experiences.
- Scalability: LLM-driven feature extraction can scale to process vast volumes of text data that would be unmanageable with manual or rule-based systems. This is particularly relevant in the age of big data, where enterprises generate petabytes of text daily.
Challenges and the Road Ahead
Despite its immense promise, LLM-driven feature engineering is not without its challenges. The cost associated with API calls, especially for very large datasets, necessitates careful optimization. Latency, while improving with specialized hardware like Groq’s, can still be a factor for real-time applications. Furthermore, the "black box" nature of LLMs means that understanding why a particular feature was extracted with a certain value can be opaque, posing challenges for interpretability and debugging. Addressing potential biases inherent in LLMs and ensuring the ethical deployment of these systems remains a critical area of focus.
Looking forward, we can anticipate further advancements in this field. Future developments may include more sophisticated schema definitions that allow for nested structures or conditional extractions, enabling even richer feature sets. The integration of multi-modal LLMs could allow for feature extraction from combinations of text, images, and other data types. As LLMs continue to evolve in accuracy, efficiency, and accessibility, their role as intelligent agents for data transformation will only expand, cementing their position as indispensable tools in the modern machine learning toolkit. The journey from raw text to actionable tabular data is no longer a laborious trek but a streamlined, intelligent process, ushering in an era of more sophisticated and insightful machine learning applications.