
The burgeoning field of artificial intelligence, particularly the rapid evolution of multi-agent systems (MAS), is revolutionizing how complex problems are approached across industries. These systems, where multiple autonomous agents collaborate or compete to achieve a common goal, promise unprecedented efficiency and adaptability. However, this parallel processing paradigm introduces a critical, often elusive, challenge: race conditions. As these sophisticated AI architectures move from research labs to production environments, understanding, identifying, and mitigating race conditions has become paramount for ensuring the reliability, integrity, and trustworthiness of autonomous operations.
The Rise of Multi-Agent AI and Concurrency Challenges
The current technological landscape is witnessing a profound shift towards distributed and concurrent computing. Traditional monolithic applications are being replaced by microservices, and now, large language model (LLM) agents are being orchestrated into complex pipelines. These multi-agent systems are designed to leverage parallelism, enabling faster processing, better resource utilization, and the ability to tackle problems too vast or intricate for a single agent. From dynamic supply chain optimization and autonomous financial trading to advanced medical diagnostics and complex cybersecurity defenses, MAS are at the forefront of innovation.
However, the very advantage of parallel execution introduces inherent complexities, primarily related to managing shared resources. In traditional software development, concurrency issues have been addressed over decades with established tools and patterns like threads, mutexes, semaphores, and atomic operations. Multi-agent LLM systems, however, operate on a different substrate. They are frequently built atop asynchronous frameworks, message brokers, and sophisticated orchestration layers that often abstract away the fine-grained control over execution order available in lower-level programming. This abstraction, while simplifying development, can inadvertently obscure the potential for race conditions, making them harder to detect and debug.
Understanding the Silent Threat: What Race Conditions Entail
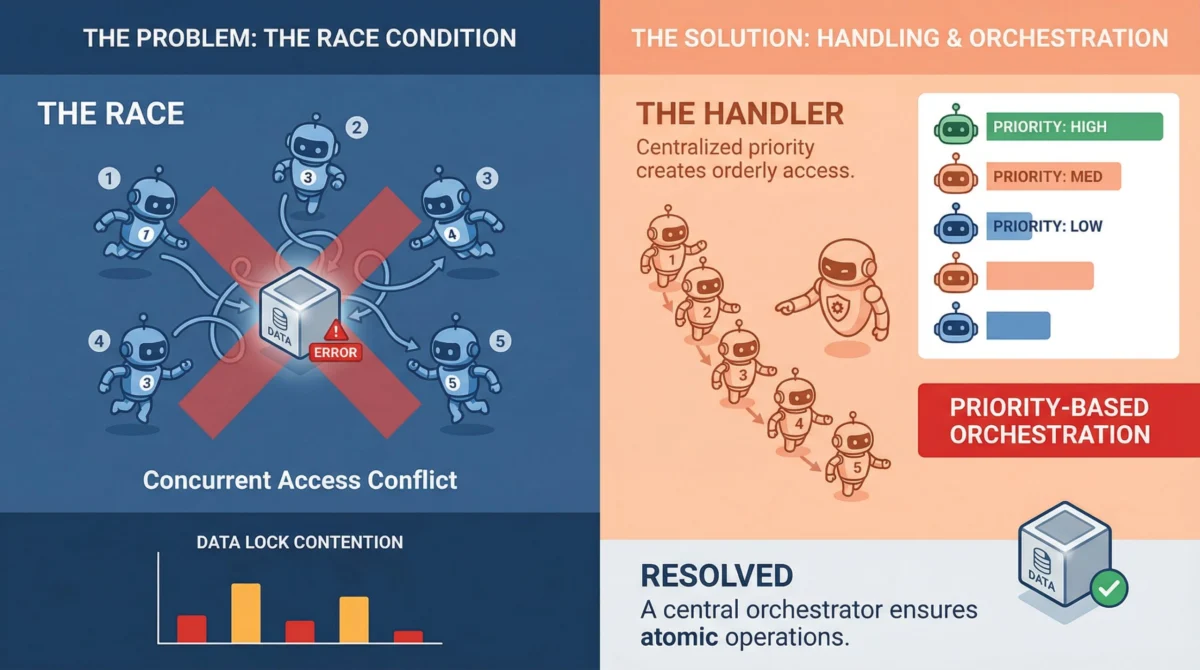
At its core, a race condition occurs when two or more agents attempt to access and modify a shared resource concurrently, and the final outcome depends on the non-deterministic timing of their operations. Unlike explicit errors or crashes, race conditions frequently manifest as subtle data inconsistencies or illogical states, making them particularly insidious. Imagine a scenario where Agent A reads a piece of critical data, Agent B updates that same data a fraction of a second later, and then Agent A writes back an older, stale version, overwriting Agent B’s valid changes. The system might report no errors, yet the integrity of the data is compromised. This silent corruption can propagate through the system, leading to cascading failures or incorrect decisions by other agents.
What exacerbates this issue in AI, especially within machine learning pipelines, is the prevalence of mutable shared objects. These can range from shared memory stores and distributed caches to vector databases that agents use for contextual retrieval, or even simple task queues from which agents pull work. Any of these shared data repositories can become a point of contention when multiple agents are designed to read from, process, and write back to them simultaneously. Furthermore, the non-deterministic nature of LLM agents, where task completion times can vary wildly—one agent might respond in milliseconds, another in several seconds due to token generation or external API calls—makes predicting execution order nearly impossible, turning race conditions from edge cases into expected occurrences.
A Growing Concern: Data and Expert Perspectives
The impact of race conditions extends beyond mere technical inconvenience. According to a hypothetical industry report by "TechInsights AI Solutions," concurrency bugs, including race conditions, are responsible for an estimated 15-20% of all critical production incidents in multi-agent AI deployments. The report further suggests that debugging and resolving these issues consume, on average, 30% more developer time compared to other bug categories, largely due to their non-reproducible nature and dependence on specific timing conditions under load.
"We’re seeing a clear trend," states Dr. Anya Sharma, lead architect at QuantumFlow AI. "As enterprises scale their multi-agent systems, the frequency and severity of race conditions escalate dramatically. What looks perfect in staging can utterly fail under peak production traffic. The economic cost, both in terms of lost operational efficiency and potential reputational damage from incorrect AI outputs, is becoming a significant concern for early adopters." Another expert, Mr. Ben Carter, a principal engineer specializing in distributed systems at Nexus Labs, adds, "The challenge with LLM agents is that their interactions often involve complex, stateful operations. Unlike simple data processing, an agent’s ‘thought process’ and subsequent actions are highly context-dependent, making any state corruption far more impactful on the overall system’s intelligence and reliability."
Mitigation Strategies: Engineering for Resilience
Addressing race conditions in multi-agent systems requires a multifaceted approach, blending established concurrency control patterns with new strategies tailored for AI environments. The goal is not merely to prevent errors, but to build systems that are inherently resilient to the chaos of parallel execution.
Foundational Principles for Concurrency Control
-
Strict Concurrency Control (Locking Mechanisms):
The most direct method to manage shared resource contention is through locking. This ensures that only one agent can access a critical section of code or a shared resource at any given moment.- Pessimistic Locking: This approach assumes that conflicts are likely and prevents concurrent access by acquiring an exclusive lock on the resource before any read or modification. While guaranteeing data consistency, it can severely limit parallelism and introduce performance bottlenecks if contention is high. It’s often suitable for scenarios where data integrity is paramount and concurrent writes are frequent.
- Optimistic Locking: This strategy operates on the assumption that conflicts are rare. Agents read data along with a version identifier (e.g., a timestamp or a version number). When an agent attempts to write back, it checks if the version has changed. If it has, another agent has modified the data, and the current write fails, prompting a retry with the fresh data. This approach offers higher concurrency but introduces complexity in handling retries and potential for livelock if conflicts are exceptionally frequent. "Choosing between pessimistic and optimistic locking is a crucial architectural decision," advises Dr. Sharma. "It directly impacts throughput versus the complexity of conflict resolution. For high-traffic, low-conflict scenarios, optimistic locking often provides a better balance."
-
Asynchronous Queuing Mechanisms:
For task assignment and processing, queuing is a robust solution that inherently serializes operations, removing the "race" element. Instead of multiple agents directly polling and competing for tasks from a shared list, tasks are pushed into a queue, and agents consume them one at a time. Systems like Redis Streams, RabbitMQ, Apache Kafka, or even robust database-backed queues (e.g., using PostgreSQL advisory locks) excel in this role. The queue acts as a serialization point, ensuring that each task is processed by a single agent at a time, eliminating write conflicts over task status or resource allocation. -
Event-Driven Architectures (EDA):
Moving beyond direct shared state, event-driven architectures promote loose coupling and reactive processing. Agents don’t directly modify a central state but instead react to events emitted by other agents or external systems. For instance, Agent A completes its processing and emits a "data_processed" event, which Agent B is subscribed to. Upon receiving this event, Agent B then picks up its work. This pattern naturally reduces the windows where multiple agents might simultaneously attempt to modify the same resource, as operations are sequentialized by event flow rather than direct contention for a lock. It fosters greater scalability and fault tolerance, as agents become more independent.
Robustness Beyond Prevention
- The Imperative of Idempotency:
Even with robust locking and queuing, systems operating in distributed environments are prone to network glitches, timeouts, and agent retries. If these retries are not idempotent, they can lead to duplicate writes, double-processed tasks, or compounding errors that are exceedingly difficult to trace and correct. Idempotency ensures that performing the same operation multiple times yields the same result as performing it once. For multi-agent systems, this typically involves associating a unique operation ID with every write or task execution. If the system detects that an operation with a given ID has already been applied, it simply skips the duplicate, ensuring consistency. "Idempotency is not an optional feature; it’s a non-negotiable requirement for any production-grade multi-agent system," emphasizes Mr. Carter. "Trying to retrofit it later is a nightmare. It needs to be a core design principle at the agent level, especially for operations that update records, trigger workflows, or interact with external services."
Proactive Detection: Testing and Validation
The ephemeral nature of race conditions makes them notoriously difficult to reproduce in controlled testing environments. They are timing-dependent, often surfacing only under specific load conditions or precise, hard-to-predict execution sequences.
- Stress Testing and Load Simulation: This involves intentionally overwhelming the system with concurrent requests or agent operations targeting shared resources. Tools like Locust (for load testing),
pytest-asyncio(for concurrent asynchronous tasks in Python), or even a simpleThreadPoolExecutorcan simulate the high-concurrency environments that expose contention bugs. The goal is to break the system in staging, not in production. - Property-Based Testing: This advanced testing technique defines invariants—properties that should always hold true regardless of the input or execution order. Randomized tests are then run to attempt to violate these invariants. For race conditions, this could mean ensuring that the final count of a resource is always the sum of all increments, irrespective of how many agents operate concurrently. While not exhaustive, it can uncover subtle consistency issues that deterministic tests often miss.
- Observability and Monitoring: Even with rigorous testing, some race conditions might only appear in the wild. Comprehensive logging, distributed tracing (e.g., OpenTelemetry), and real-time metrics are critical. These tools provide visibility into agent interactions, shared resource access patterns, and state changes, allowing developers to identify when and how a race condition occurred in a production environment, enabling faster post-mortem analysis and resolution.
Case Study: The Shared Counter Anomaly
To illustrate the concrete impact of race conditions, consider a simple scenario: a shared counter that multiple agents increment. This could represent anything from the number of processed documents in a workflow to available inventory items or active user sessions.
Here’s a simplified problematic pseudocode:
# Shared state
counter = 0
# Agent task
def increment_counter():
global counter
value = counter # Step 1: read the current value
value = value + 1 # Step 2: modify the value
counter = value # Step 3: write the new value backNow, imagine two agents, Agent X and Agent Y, simultaneously execute increment_counter().
-
Scenario 1 (No Race):
- Agent X: Reads
counter(0), modifies to 1, writes 1. - Agent Y: Reads
counter(1), modifies to 2, writes 2. - Final
counter: 2 (Correct)
- Agent X: Reads
-
Scenario 2 (Race Condition):
- Agent X: Reads
counter(0). - Agent Y: Reads
counter(0). - Agent X: Modifies its
valueto 1. - Agent Y: Modifies its
valueto 1. - Agent X: Writes
counter= 1. - Agent Y: Writes
counter= 1. - Final
counter: 1 (Incorrect – one increment was lost silently).
- Agent X: Reads
This simple example, while abstract, mirrors real-world problems. A lost increment could mean an order isn’t fully processed, a critical alert isn’t triggered, or a resource is over-allocated.
Solutions to the Shared Counter Anomaly:
-
Locking the Critical Section:
Ensures exclusive access during the read-modify-write cycle.lock.acquire() value = counter value = value + 1 counter = value lock.release()This guarantees correctness but can introduce contention if many agents frequently need to increment.
-
Atomic Operations:
If the underlying infrastructure supports it, delegating the entire operation as an indivisible unit is ideal.counter = atomic_increment(counter)Databases (e.g.,
UPDATE ... SET count = count + 1), specialized key-value stores (e.g., RedisINCR), and some in-memory concurrency primitives offer atomic operations, eliminating the race entirely. -
Idempotent Writes with Versioning (Optimistic Locking):
Detects and resolves conflicts by comparing versions.# Read with version value, version = read_counter() # Attempt write with expected version success = write_counter(value + 1, expected_version=version) if not success: # Another agent updated it first; retry the whole operation retry()This approach allows for higher concurrency but requires a robust retry mechanism and careful handling of version tags.
Broader Implications for AI System Design
The ongoing battle against race conditions in multi-agent systems is more than a technical hurdle; it represents a fundamental challenge in building reliable, scalable, and trustworthy AI. Neglecting these issues can lead to profound consequences: from misinformed decisions by autonomous systems to corrupted datasets, and ultimately, a erosion of trust in AI technologies.
As AI agents become more sophisticated and integrated into critical infrastructure, the need for formal verification methods and specialized concurrency frameworks designed specifically for LLM-driven interactions will grow. The future of robust multi-agent AI lies in an architectural philosophy that embraces concurrency as a first-class citizen, anticipating its challenges rather than reacting to its failures. Developers and architects must shift their mindset from sequential programming paradigms to genuinely distributed thinking, understanding that any shared state is a potential point of failure.
Final Thoughts
Race conditions are an inherent byproduct of parallel execution, and in the dynamic world of multi-agent AI, they are not exceptions but expected participants. Successfully navigating these challenges demands intentional design choices: the strategic application of locking and queuing mechanisms, the adoption of event-driven architectures for loose coupling, and the unwavering commitment to idempotency. These are not merely best practices; they are foundational pillars for constructing resilient multi-agent systems capable of operating predictably and reliably in complex, real-world environments. By prioritizing these architectural fundamentals, developers can transform the inherent chaos of concurrent agents into a symphony of coordinated intelligence.