
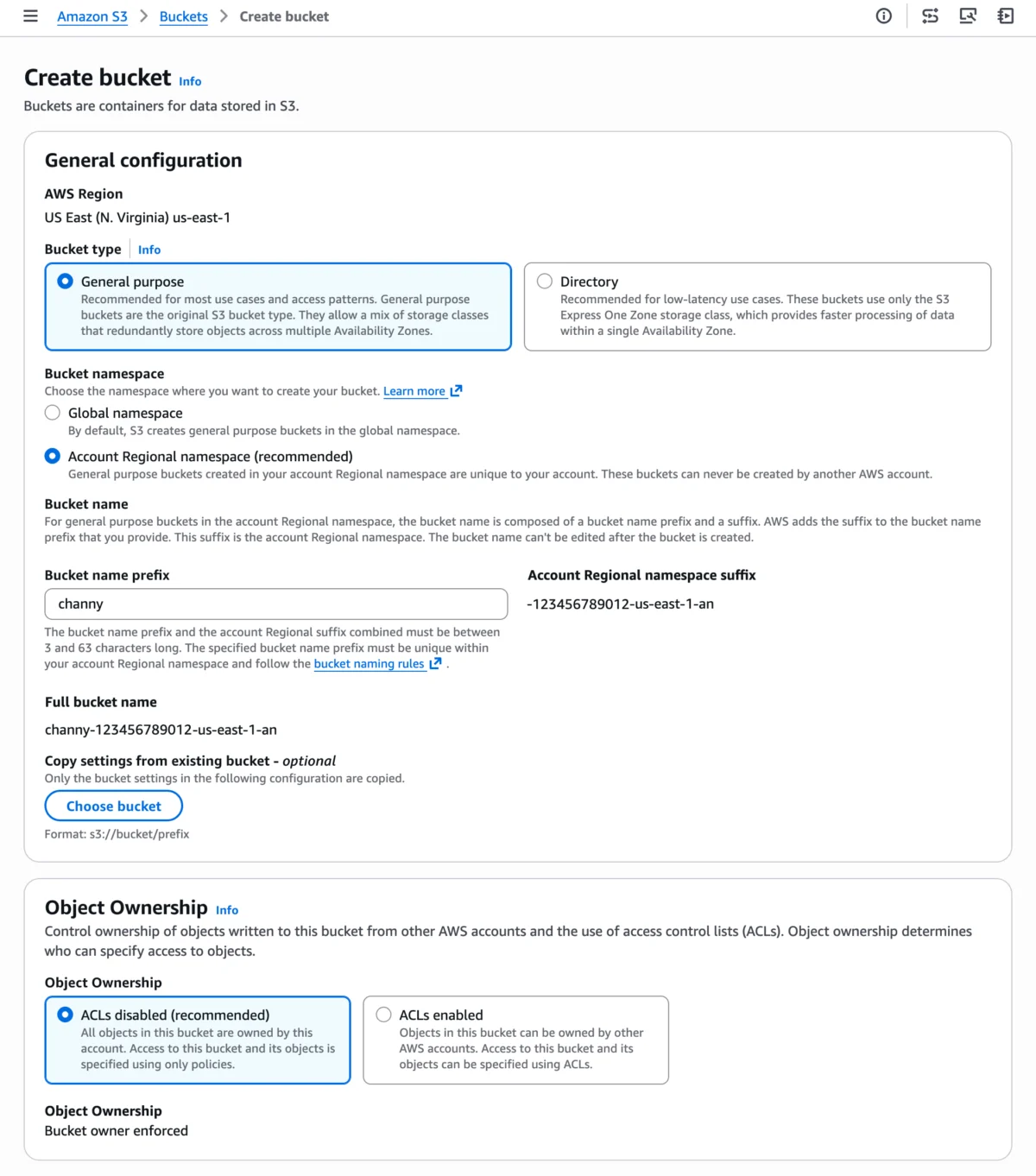
Amazon Simple Storage Service (Amazon S3) has recently unveiled a significant new feature, enabling the creation of general purpose buckets within a customer’s own account regional namespace. This advancement promises to fundamentally simplify bucket creation and management, ensuring consistent naming predictability as data storage needs escalate in both size and scope across global deployments, marking a pivotal moment in cloud storage governance.
The new capability directly addresses long-standing challenges associated with S3’s traditional global namespace, where every bucket name had to be uniquely identifiable across all AWS accounts and regions worldwide. This often led to naming conflicts, "bucket squatting," and significant operational overhead for organizations attempting to standardize their cloud storage architecture. With the introduction of account regional namespaces, users can now create general purpose bucket names that are unique only within their specific AWS account and chosen region, effectively eliminating global naming collisions for these newly provisioned buckets.
The core mechanism involves appending a unique, system-generated suffix to the user-defined bucket name prefix. For instance, a user might specify mybucket as their prefix, and the system would automatically add a suffix like -123456789012-us-east-1-an (where 123456789012 represents the AWS account ID, us-east-1 denotes the specific AWS Region, and -an signifies "account namespace"). This ensures that mybucket created in one account’s us-east-1 region will not conflict with mybucket in another account’s us-east-1 region, or even the same account’s us-west-2 region, provided the account regional namespace feature is utilized. Attempts by other accounts to create buckets using a specific account’s regional suffix will be automatically rejected, reinforcing security and resource isolation. This feature is immediately available across 37 AWS Regions, including critical AWS China and AWS GovCloud (US) Regions, underscoring its broad applicability for global enterprises and regulated industries. Crucially, AWS has confirmed that there is no additional cost associated with leveraging this new naming convention, further enhancing its appeal for organizations looking to optimize their cloud spend while improving operational efficiency.
Background and Context: The Evolution of S3 and Naming Challenges
Since its inception in 2006, Amazon S3 has been a cornerstone of cloud computing, offering highly scalable, durable, and cost-effective object storage. It rapidly became the de facto standard for everything from static website hosting and data lakes to backup and disaster recovery. A fundamental characteristic of S3 from its early days was the requirement for globally unique bucket names. This design choice, while simplifying routing and access control in a nascent cloud environment, presented growing complexities as AWS expanded globally and enterprise adoption surged.
The "global namespace problem" manifested in several critical ways:

- Naming Collisions: As millions of users and organizations onboarded to AWS, finding simple, intuitive, and available bucket names became increasingly difficult. This often forced users to resort to obscure or lengthy names, complicating management and human readability, and leading to frustration in development and operations teams.
- Bucket Squatting: The global uniqueness created a scenario where desirable, easily memorable bucket names could be registered by malicious actors or even innocent users, thereby preventing legitimate organizations from using their preferred, often brand-aligned, naming conventions. This could lead to brand confusion or operational hurdles.
- Enterprise Standardization Hurdles: Large enterprises with complex multi-account strategies and numerous development teams struggled immensely to enforce consistent naming across their sprawling AWS environments. A central IT or governance team might mandate a specific prefix for all S3 resources, but the underlying global uniqueness constraint still meant that teams in different regions or accounts might accidentally pick the same "available" name, only to find it taken by another team, leading to rework, delays, and governance challenges.
- Infrastructure as Code (IaC) Complexity: For organizations heavily relying on automation tools like AWS CloudFormation, Terraform, or Pulumi, dynamically generating globally unique bucket names often required complex scripting, reliance on random string generation, or elaborate external services to manage name availability. This added unnecessary complexity to IaC templates, hindering readability, auditability, and overall maintainability.
AWS has previously introduced various S3 bucket types to cater to specialized needs, each with its own namespace characteristics. For instance, S3 Directory Buckets operate within a zonal namespace, optimized for performance-intensive workloads requiring low-latency access, while S3 Table Buckets and Vector Buckets already reside in an account-level namespace. However, general purpose buckets, which constitute the vast majority of S3 usage and support a wide range of applications, continued to operate under the global uniqueness constraint until this recent announcement. This new feature for general purpose buckets thus marks a pivotal step in addressing the most prevalent and widespread naming challenges faced by the AWS customer base.
A Deeper Dive into the Mechanism: How it Works
The new account regional namespace fundamentally alters how S3 bucket names are resolved and managed. Instead of a single, universal registry for all bucket names, the system now prioritizes the combination of the user’s AWS account ID and the specific AWS Region, creating a localized namespace that is isolated and unique to that context.
When a user opts for the "Account regional namespace" option during bucket creation, the S3 service automatically appends a standardized suffix to the user-provided bucket name prefix. This suffix is dynamically generated and comprises three key components:
- AWS Account ID: A globally unique, 12-digit numerical identifier assigned to each AWS account. This ensures that the namespace is explicitly tied to a specific customer entity.
- AWS Region: The specific geographical region where the bucket is being created (e.g.,
us-east-1for N. Virginia,eu-west-1for Ireland). This component ensures regional specificity and aligns with data residency principles. - Namespace Identifier: A fixed, short string, such as
-an(for "account namespace"), which serves as a clear indicator to S3 that this particular bucket operates within the new naming paradigm and should be treated accordingly.
For example, if an account with ID 123456789012 in the us-east-1 region creates a bucket with the prefix my-application-data, the resulting full bucket name would be my-application-data-123456789012-us-east-1-an. This name is guaranteed to be unique within that specific account and region, irrespective of whether other AWS accounts have chosen my-application-data as a prefix in the same or different regions. Another account, even if it tries to create my-application-data in us-east-1, would generate a different suffix based on its own distinct account ID, thus inherently avoiding collision. Crucially, attempting to manually create a bucket with another account’s specific suffix will be automatically rejected by S3, preventing unauthorized usage and ensuring robust resource isolation and security.
The combined length of the bucket name prefix and the account regional suffix must adhere to S3’s standard bucket naming rules, specifically being between 3 and 63 characters long. This ensures backward compatibility with existing S3 APIs and tools while providing ample flexibility for creating meaningful and descriptive bucket names.
Enhancing Security and Compliance Through Policy Enforcement
One of the most significant benefits for enterprise customers, particularly those operating under stringent regulatory requirements, lies in the enhanced security and compliance capabilities offered by this new feature. AWS Identity and Access Management (IAM) policies and AWS Organizations Service Control Policies (SCPs) can now be strategically leveraged to enforce the mandatory adoption of the account regional namespace across an entire organization, ensuring consistent governance.

The introduction of the new s3:x-amz-bucket-namespace condition key is a game-changer for cloud governance. It allows security teams and cloud administrators to mandate that all new general purpose buckets within their AWS accounts or specific organizational units (OUs) must utilize the account regional namespace. This translates into several critical advantages:
- Preventing Shadow IT and Misconfigurations: Organizations can effectively prevent developers from inadvertently or intentionally creating buckets in the global namespace, which might fall outside established naming conventions, security baselines, or compliance mandates. This helps maintain a "least privilege" and "secure by default" posture.
- Standardized Resource Creation: It facilitates the enforcement of a consistent naming strategy across the entire cloud footprint, which is absolutely crucial for efficient auditing, accurate cost allocation, and streamlined management of access controls at scale. Standardized naming simplifies identification and troubleshooting.
- Improved Auditability and Traceability: With predictable and enforced naming conventions, it becomes significantly easier to identify, track, and audit S3 resources. Each bucket name inherently links to specific accounts, regions, and often, by design, to specific application contexts or data classifications. This improved traceability is invaluable for demonstrating compliance with regulatory frameworks such as GDPR, HIPAA, PCI-DSS, ISO 27001, and SOC 2, where clear data ownership, location, and access logs are paramount.
- Reduced Operational Risk and Enhanced Reliability: By eliminating global namespace conflicts and enforcing naming policies, the risk of deploying applications with incorrect bucket names or experiencing deployment failures due to naming issues is substantially reduced. This translates directly into greater stability, reliability, and resilience for critical business workloads, minimizing potential downtime and data access disruptions.
For large enterprises operating under strict compliance regimes, the ability to programmatically enforce bucket naming conventions via SCPs at the organizational level provides a robust guardrail. It ensures that even if individual teams attempt to bypass recommended practices or make configuration errors, the central governance policies will prevent non-compliant resource creation, thereby upholding the organization’s security and compliance posture.
Seamless Integration with Developer Tools and Infrastructure as Code (IaC)
AWS has ensured that the new account regional namespace feature is seamlessly integrated across its ecosystem of developer tools, making adoption straightforward and efficient for various user personas, from GUI-centric users to advanced automation engineers.
-
Amazon S3 Console: The most accessible entry point for many users. Within the familiar "Create bucket" wizard, a new "Account regional namespace" option is now prominently available. Selecting this option allows users to provide any desired prefix, and S3 handles the automatic generation and appending of the account and region-specific suffix. This intuitive interface makes it easy for individuals and small teams to immediately benefit from the feature without delving into complex configurations.
-
AWS Command Line Interface (AWS CLI): For those who prefer scripting, automation, and command-line interactions, the AWS CLI fully supports creating these buckets. Users can specify the
--bucket-namespace account-regionalparameter during thecreate-bucketcommand. This enables DevOps engineers and system administrators to incorporate the new naming convention into their existing scripts,