
The Allen Institute for AI (Ai2) has launched MolmoWeb, a significant advancement in the field of open-source visual web agents. This new model family, part of Ai2’s broader Molmo 2 initiative, aims to provide researchers and developers with powerful tools to build AI agents capable of navigating and interacting with the web in a manner similar to human users. Available in 4-billion and 8-billion parameter versions, MolmoWeb is designed to be lightweight enough for local execution, a key feature that distinguishes it from many proprietary, resource-intensive alternatives. The release extends beyond just the models themselves, encompassing the weights, training data, and evaluation tools, fostering transparency and accelerating open research in AI-driven web automation.
For months, the capabilities of AI agents that can browse the internet and execute tasks on behalf of users have been rapidly improving. However, the underlying models powering these sophisticated agents have largely remained proprietary, limiting the accessibility and reproducibility of research in this domain. MolmoWeb emerges as a direct response to this gap, offering a robust, open-source alternative. This initiative by Ai2, a renowned research institution dedicated to advancing artificial intelligence for the common good, underscores a commitment to democratizing access to cutting-edge AI technologies.
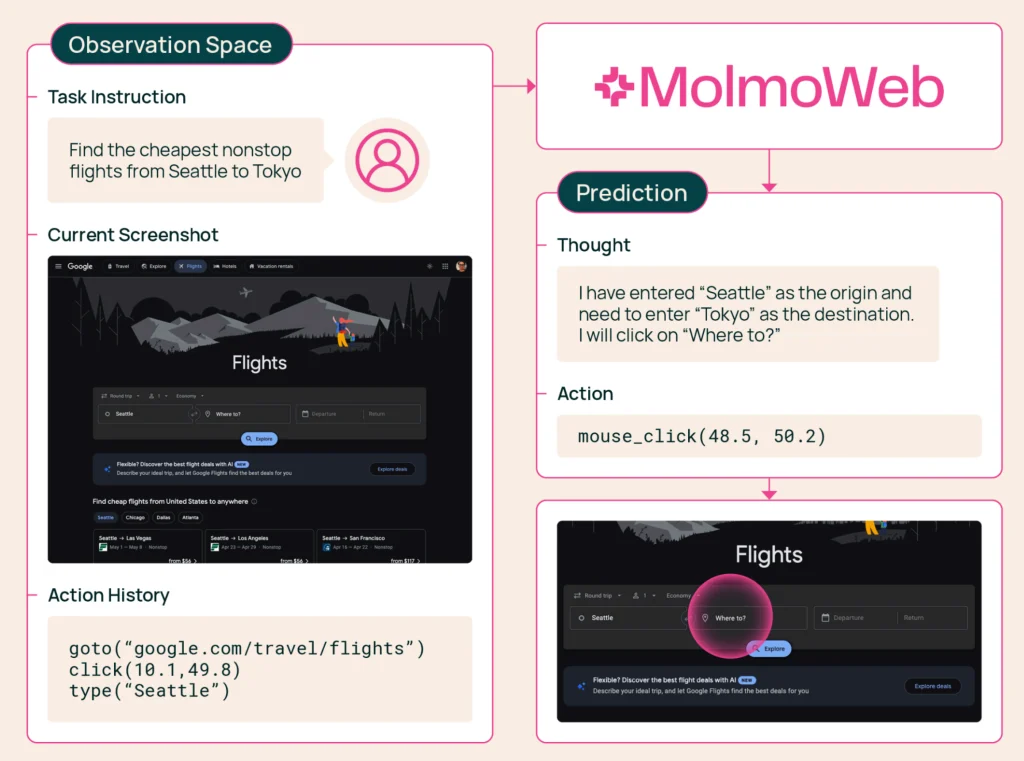
MolmoWeb’s core functionality lies in its ability to interpret visual information from web pages—essentially, screenshots—and then predict the necessary actions to achieve a given task. This includes navigating complex websites, accurately filling out forms, efficiently searching for products on e-commerce platforms, and retrieving specific pieces of information. Unlike some approaches that focus on interacting with the underlying code or structured data of individual websites, MolmoWeb operates at the user interface level, mimicking how a human would interact with a browser. This visual, action-oriented approach makes it versatile across a wide range of web applications.
A critical differentiator for MolmoWeb is its training methodology. Instead of relying on distillation from existing proprietary vision-based agents, Ai2’s team developed MolmoWeb using a novel combination of synthetic data and human demonstrations. The training data originates from "synthetic trajectories generated by text-only accessibility-tree agents and human demonstrations." This approach is particularly noteworthy because it avoids the ethical and technical challenges associated with distilling knowledge from closed-source models and instead builds a foundation from the ground up. Accessibility-tree agents, which can parse web content through its underlying structure rather than visual rendering, provide a scalable way to generate initial training data. These synthetic trajectories are then augmented with detailed human demonstrations, offering a rich and nuanced dataset.
Performance Benchmarks and Competitive Landscape
The efficacy of MolmoWeb is demonstrated through its performance on standard browser-use benchmarks. In head-to-head comparisons, MolmoWeb has shown impressive results, even outperforming OpenAI’s GPT-4o on certain tasks, despite GPT-4o’s reliance on annotated screenshots and structured page data. While GPT-4o represents a more established, albeit older, proprietary model, MolmoWeb’s performance highlights the potential of open-weight models when trained with carefully curated data.

Among the existing open-weight models designed for web agent tasks, MolmoWeb, in both its 4-billion and 8-billion parameter variants, consistently outperforms competitors such as Fara-7B and GLM-4.1V-9B. These benchmark results suggest that the unique training approach employed by Ai2 has yielded a model that is not only efficient but also highly capable in executing web-based tasks.
However, it is important to acknowledge that proprietary models from leading AI labs like Anthropic, Google, and OpenAI still generally exhibit superior performance. These commercial entities often benefit from massive datasets, extensive computational resources, and proprietary techniques that are not publicly disclosed. Ai2’s mission, however, is not solely to compete at the bleeding edge of commercial AI capabilities. A significant aspect of their objective is to provide the research community with the foundational tools necessary to explore, understand, and advance the field of AI web agents.
As the Ai2 team articulated in their release, "the open-source community lacks not just the models but the training data, infrastructure, and evaluation tools needed to build competitive alternatives. That gap limits reproducibility, slows research progress, and makes it difficult to understand how these systems actually work. In many ways, web agents today are where LLMs were before Olmo—the community needs an open foundation to build on." This statement clearly delineates Ai2’s strategic role in fostering a more inclusive and collaborative research ecosystem.
MolmoWeb’s Training Data: A Foundation for Open Research
The extensive training dataset underpinning MolmoWeb is a cornerstone of its success and a valuable asset for the research community. The dataset comprises approximately 30,000 human task trajectories, which Ai2 claims to be "the largest publicly released dataset of human web task execution to date." This comprehensive collection spans nearly 600,000 individual subtasks across more than 1,100 unique websites. The sheer scale and diversity of this dataset are crucial for enabling the model to generalize effectively across a wide array of web environments and user intentions.
To supplement the human demonstrations and further enrich the training process, Ai2 generated synthetic trajectories. These were created using agents that interacted with websites by leveraging accessibility trees. This method is significantly more efficient for agent-based generation because it bypasses the complex task of visual interpretation, allowing for the rapid creation of large volumes of task execution data. This hybrid approach—combining authentic human behavior with scalable synthetic data generation—provides a robust and comprehensive training regimen.
Beyond task trajectories, the training set also includes annotated screenshots, providing detailed information about various elements on a webpage, such as buttons, text fields, and links. Furthermore, the dataset incorporates over 2.2 million question-answer pairs derived from reasoning tasks. In these tasks, the model was prompted to answer questions about screenshots from approximately 400 different websites, enhancing its ability to understand context and perform inferential reasoning based on visual web content. This multifaceted dataset is designed to equip MolmoWeb with a deep understanding of web structure, user interface elements, and the cognitive processes involved in web navigation and task completion.

Availability and Future Implications
MolmoWeb is now publicly accessible, with the models, training data, and evaluation tools available on both Hugging Face and GitHub. This immediate availability is critical for enabling researchers worldwide to experiment with, build upon, and contribute to the development of open-source web agents. The release signifies a pivotal moment for the field, providing the much-needed open foundation that Ai2 highlighted as essential for progress.
The implications of MolmoWeb extend far beyond academic research. By lowering the barrier to entry for developing sophisticated web automation tools, it could spur innovation in areas such as:
- Personalized AI Assistants: More capable and customizable personal assistants that can manage online tasks, from booking appointments to managing finances.
- Automated Customer Support: AI agents that can handle complex customer inquiries and tasks on websites, improving efficiency and user experience.
- Web Scraping and Data Analysis: Enhanced tools for collecting and analyzing data from the web in a more nuanced and context-aware manner.
- Accessibility Tools: Development of new assistive technologies that can help individuals with disabilities navigate the web more effectively.
- Educational Tools: Interactive learning platforms that can guide users through complex online processes or simulate real-world web interactions.
The open-source nature of MolmoWeb also promotes transparency and accountability in AI development. Researchers can scrutinize the model’s architecture, training data, and evaluation methods, which is crucial for identifying potential biases, understanding failure modes, and ensuring ethical deployment. This level of transparency is often lacking in proprietary AI systems, where internal workings are closely guarded secrets.
The availability of robust, open-source visual web agents like MolmoWeb marks a significant step towards a more democratized AI landscape. As the field continues to evolve, initiatives like this from the Allen Institute for AI are instrumental in empowering a broader community to participate in shaping the future of artificial intelligence and its applications in the digital world. The ongoing research and development in this area promise to unlock new possibilities for human-computer interaction and automation, making the internet more accessible and manageable for everyone.