
In the rapidly evolving landscape of artificial intelligence, a groundbreaking approach known as Recursive Language Models (RLMs) is emerging, promising to redefine how large language models (LLMs) interact with and process extensive inputs. This paradigm shift addresses critical limitations in conventional LLM architectures, particularly their struggles with "context rot" when confronted with very long texts. This article will delve into the mechanics of RLMs, explain their significance for long-input reasoning, and differentiate them from established methods such as standard long-context prompting, retrieval-augmented generation (RAG), and agentic systems.
The Persistent Challenge of Long Context: Understanding "Context Rot"
For several years, the advancements in large language models have been nothing short of remarkable. Their capacity to understand, generate, and reason with textual information has expanded exponentially, leading many to believe that the problem of handling long inputs was largely resolved. However, practical experience reveals a more nuanced reality. While contemporary LLMs boast impressive context windows, often extending to tens or even hundreds of thousands of tokens, their performance tends to degrade noticeably when these windows are pushed to their limits. This degradation, colloquially termed "context rot," manifests as a series of critical failures: models frequently overlook crucial details embedded within the lengthy input, generate responses that contradict earlier statements, or produce superficial answers instead of performing deep, analytical reasoning.
This phenomenon is not merely a matter of memory or computational capacity. Even when an LLM is theoretically capable of "seeing" the entire prompt, its ability to effectively utilize that information diminishes. Several factors contribute to this behavior. Firstly, the attention mechanisms central to transformer architectures, while powerful, can struggle to maintain uniform focus across an exceedingly long sequence. The signal-to-noise ratio can decrease, making it harder for the model to identify the most relevant pieces of information amidst a vast sea of text. Secondly, positional encodings, which provide the model with information about token order, can become less effective over very long distances, blurring the relationships between disparate parts of the input. Lastly, the sheer cognitive load of processing an immense amount of information in a single pass can overwhelm the model, leading to a kind of "information overload" where deep understanding is sacrificed for broad but shallow coverage. This is particularly problematic for tasks requiring intricate logical deductions, cross-referencing, or synthesizing information from widely separated sections of a document.
Evolution of Solutions: From Summarization to Agentic Systems
The recognition of these long-context limitations spurred the development of various mitigation strategies prior to the advent of RLMs. Early attempts often relied on summarization, where long documents were condensed into shorter, more manageable texts before being fed to the LLM. While useful for extracting main ideas, summarization is inherently a lossy process; critical details, specific clauses, or subtle nuances essential for precise reasoning can be inadvertently discarded.
Another significant advancement was Retrieval-Augmented Generation (RAG). RAG systems operate by first retrieving a small, highly relevant set of document chunks from a larger corpus based on a user query, and then feeding these chunks, along with the query, to the LLM. This approach has proven highly effective for question-answering tasks where the answer resides in a few distinct, identifiable passages. However, RAG makes a crucial assumption: that relevance can be accurately and reliably identified before the reasoning process begins. Many real-world tasks violate this assumption. For instance, a legal analysis might require synthesizing information from dozens of disparate sections of a contract, where no single section is "most relevant" until the full context is understood. If the initial retrieval misses a key piece of information, the subsequent reasoning will be flawed.
More recently, agentic systems have gained traction. These frameworks involve an LLM acting as a "controller," breaking down complex tasks into sub-tasks, interacting with external tools (like search engines, code interpreters, or databases), and maintaining a working memory or conversation history. While agent systems represent a significant leap in enabling LLMs to perform multi-step reasoning, they often grapple with their own context management challenges. The full conversation history or working memory is frequently re-injected into the model’s context in each turn. As this context grows, older information might be summarized or simply dropped, leading to a form of "internal context rot" or loss of long-term coherence.
While each of these approaches offers valuable solutions for specific scenarios, none fully address the fundamental problem of an LLM struggling to deeply and interactively process an extremely long input document where relevance is dense and distributed, and aggregation across many parts is required. This is precisely the gap that Recursive Language Models aim to fill.
Introducing Recursive Language Models: A Paradigm Shift
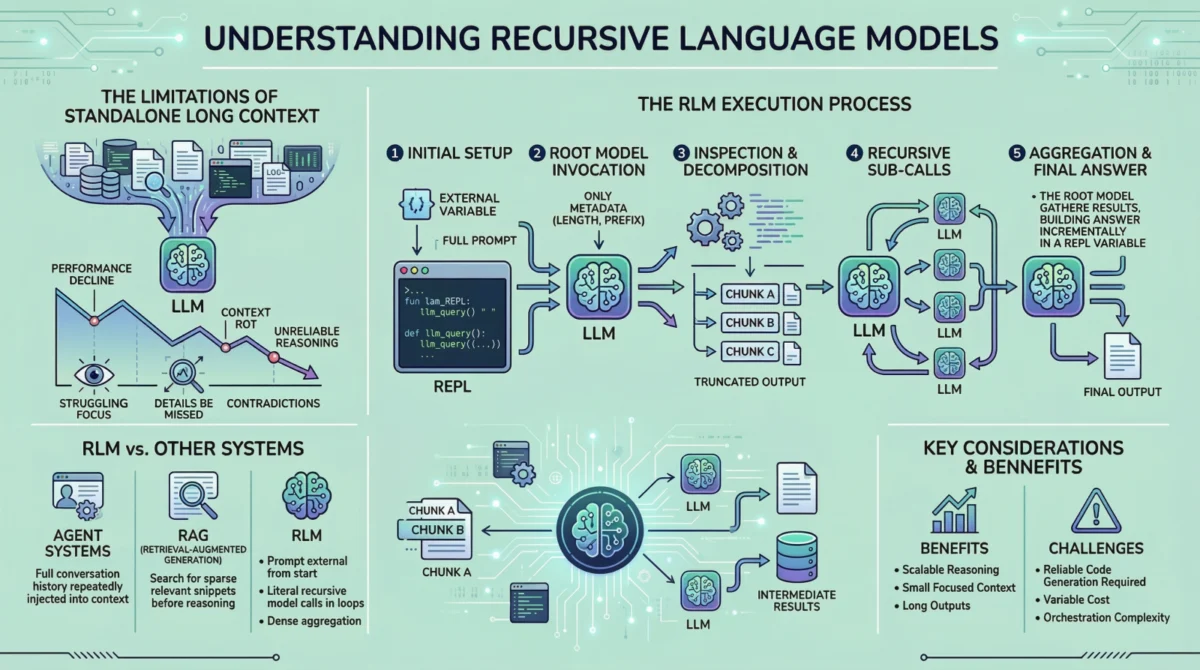
Recursive Language Models fundamentally alter the interaction model between an LLM and its input. Instead of attempting to cram an entire document into the model’s fixed context window for a single forward pass, RLMs treat the prompt itself as an external environment. This means the extensive input text does not reside within the model’s immediate context but rather sits outside, often managed as a variable or object within a dynamic runtime. The LLM is initially provided only with metadata about the prompt—such as its size, format, or high-level structure—along with explicit instructions on how to programmatically access and manipulate it.
This innovative design forces the model to engage with the input intentionally and strategically, rather than passively consuming it. When the model requires specific information, it does not simply "read" it; instead, it issues commands to examine particular parts of the prompt, much like a human researcher selectively scanning a document. This interactive, programmatic approach ensures that the model’s internal context window remains small, focused, and free from the burden of managing the entire input, even when the underlying document is gargantuan. The core idea is to enable the LLM to "explore" and "process" the prompt actively, reflecting a more human-like approach to information processing.
Mechanism in Detail: How RLMs Operate in Practice
To grasp the concrete workings of an RLM, let us walk through a typical execution flow, which is structured to facilitate scalable and precise reasoning over vast amounts of text.
Step 1: Initializing a Persistent REPL Environment
At the genesis of an RLM operation, the system establishes a robust runtime environment. This is typically a Python Read-Eval-Print Loop (REPL), which serves as the operational backbone for the recursive process. This environment is meticulously configured to include:
- The complete, externalized input prompt: This is the large document or dataset that the model needs to process, held outside the LLM’s direct context.
- A suite of utility functions: These functions are pre-defined tools that the LLM can invoke to interact with the external prompt. Examples include functions for reading specific lines, searching for keywords, splitting text based on delimiters, or summarizing designated sections.
- A memory or scratchpad: This acts as a persistent storage area within the REPL, allowing the model to store and retrieve intermediate results, observations, and partial conclusions across multiple steps without cluttering its immediate context window.
From the user’s perspective, the interface remains straightforward: a textual input yields a textual output. Internally, however, the REPL acts as sophisticated scaffolding, enabling the nuanced, scalable reasoning that defines RLMs. This persistent environment is crucial as it maintains state across multiple LLM calls, allowing for cumulative information gathering and processing.
Step 2: Invoking the Root Model with Prompt Metadata Only
The initial interaction involves invoking the primary, or "root," language model. Crucially, this invocation does not include the full prompt. Instead, the model is furnished with:
- A concise, high-level description of the task: This outlines what the model needs to achieve with the input.
- Metadata about the prompt: This might include the document’s length, estimated section count, file type, or any other structural information that can guide the model’s initial exploration. For instance, it might be told, "You have access to a 50-page legal brief; analyze clauses related to intellectual property."
- Instructions on how to access the prompt: This includes details on which utility functions are available and how to call them within the REPL environment.
By deliberately withholding the full prompt, the system compels the model to interact with the input in a structured, intentional manner. The model is forced to ask for information rather than passively absorbing it, a key differentiator from traditional long-context prompting.
Step 3: Inspecting and Decomposing the Prompt via Code Execution
Upon receiving its initial instructions and prompt metadata, the LLM’s first action is often to generate Python code. This code is designed to inspect the structure of the external input. For example, it might generate commands like print(prompt.head(10)) to view the first few lines, prompt.find_sections('heading') to identify document sections, or prompt.split_by_delimiter('nn') to chunk the text.
This generated code is then executed within the persistent REPL environment. The outputs of these operations—such as the first ten lines of the document or a list of identified headings—are carefully truncated before being presented back to the LLM. This truncation is a vital mechanism to prevent the LLM’s context window from being overwhelmed, maintaining focus and efficiency. The model thus iteratively builds an understanding of the document’s layout and content without ever seeing the whole thing at once.
Step 4: Issuing Recursive Sub-Calls on Selected Slices
Once the model has developed an initial understanding of the prompt’s structure and contents, it can strategically decide how to proceed with the task. If the task demands a deep semantic understanding of particular sections, the model can generate code to issue sub-queries. Each sub-query is, in essence, a separate language model call, but critically, it is executed on a much smaller, carefully selected "slice" of the original prompt.
This is where the "recursive" aspect of RLMs truly comes into play. The model effectively decomposes a large problem into smaller, more manageable sub-problems. For each sub-problem, it can initiate another LLM call, passing only the relevant slice of the input and a specific sub-task. The results of these sub-calls are not fed back into the root model’s immediate context. Instead, they are stored as intermediate results within the REPL’s persistent memory. This allows the model to accumulate findings, synthesize insights, and build a comprehensive understanding step-by-step, without any single LLM invocation being burdened by the entire document. This iterative decomposition and processing enable the RLM to scale its reasoning capabilities with the size and complexity of the input.
Step 5: Assembling and Returning the Final Answer
Finally, after a sufficient amount of information has been gathered, processed through recursive sub-calls, and stored in the environment’s memory, the root model generates the final answer. If the output itself is lengthy or complex, the RLM employs further strategies to manage its generation:
- Streaming output: The final answer can be streamed piece by piece, avoiding a single massive output block.
- Storing in the environment: If the final answer is too large for a single output, it can be constructed and stored in the REPL environment, with only a reference or summary presented to the user.
This sophisticated mechanism ensures that RLMs can produce outputs that far exceed the token limits of a single language model call, offering unprecedented flexibility in handling complex, multi-faceted tasks. Throughout this entire recursive process, no single language model invocation ever needs to see or process the full, unadulterated prompt, thereby circumventing the "context rot" problem directly.
What Makes RLMs Different from Agents and Retrieval Systems
While RLMs share some operational similarities with agentic frameworks and Retrieval-Augmented Generation (RAG) systems, their core design principles and objectives are distinct. Understanding these differences is crucial for appreciating the unique value proposition of RLMs.
Agent Systems vs. RLMs: In many agent systems, the cumulative conversation history, tool outputs, and working memory are repeatedly injected into the LLM’s context window. As the interaction progresses and this context grows, agentic systems often resort to summarization or truncation of older information to manage context length. This can lead to a loss of fidelity or important details over long interactions. RLMs, by contrast, fundamentally avoid this pattern. From the very outset, the entire prompt and all intermediate working memory are kept external to the LLM’s immediate context. The LLM only "sees" specific, small slices of information it explicitly requests, maintaining a consistently focused and small internal context. This externalization prevents the "context rot" that can afflict long-running agentic conversations.
Retrieval-Augmented Generation (RAG) vs. RLMs: RAG systems excel in scenarios where the answer to a query is typically contained within a small, identifiable set of relevant document chunks. The underlying assumption is that an initial retrieval step can accurately pinpoint these relevant chunks before reasoning commences. This works well when relevance is sparse and localized. However, RLMs are designed for situations where relevance is dense and distributed across an entire document, and where complex reasoning requires the aggregation and synthesis of information from numerous, potentially non-contiguous parts of the input. For instance, analyzing a detailed financial report might require understanding relationships between data points scattered across dozens of pages, where no single "chunk" holds the complete answer. RAG would struggle here due to its reliance on initial relevance scoring.
The Crucial Distinction: Recursion and Code Execution: A key differentiator for RLMs is the literal and intentional use of recursion. Unlike metaphorical uses of the term, RLMs genuinely involve the model calling language models (or instances of itself) within programmatic loops generated as executable code. This allows the model to systematically decompose problems, process information in iterative passes, and store intermediate results within a persistent environment. This programmatic and recursive interaction with an externalized prompt enables RLMs to scale work with input size in a controlled, deliberate, and deeply analytical manner, a capability not inherent in standard RAG or agentic architectures.
Costs, Tradeoffs, and Limitations
Despite their innovative potential, Recursive Language Models are not without their own set of costs, tradeoffs, and practical limitations that warrant consideration.
Computational Cost Shift: RLMs do not eliminate computational costs; rather, they shift them. Instead of incurring the expense of a single, very large model invocation (which can be substantial for extremely long contexts), RLMs involve many smaller invocations. This is coupled with the overhead associated with code generation, execution within the REPL, and the orchestration of these multiple steps. In many practical scenarios, the total cost of an RLM run might be comparable to, or even exceed, a standard long-context call, particularly if the recursive calls are numerous. Furthermore, the variance in cost can be higher, as the number of sub-calls can depend dynamically on the complexity of the input and the reasoning path chosen by the model.
Reliability of Code Generation: A significant practical challenge lies in the model’s ability to reliably generate correct and efficient code. The LLM must be proficient in writing code that accurately interacts with the external environment and utility functions. Poorly constrained or less capable models might generate faulty code, initiate an excessive number of sub-calls (leading to spiraling costs and execution times), or fail to terminate the process cleanly, potentially getting stuck in loops. Robust error handling and careful prompt engineering are crucial to mitigate these risks.
Output Protocol Design: Designing effective output protocols is another engineering challenge. It is essential to clearly distinguish between intermediate steps, debugging information, and the final, definitive answer. The system must intelligently manage what information is presented back to the user versus what remains within the internal REPL memory, especially when the final answer itself is extensive.
These are primarily engineering and operational hurdles, rather than fundamental conceptual flaws. However, they underscore that implementing and deploying RLMs effectively requires careful system design, robust monitoring, and potentially more sophisticated prompt engineering than traditional LLM applications.
Potential Impact and Future Outlook
The implications of Recursive Language Models are far-reaching, promising to unlock new capabilities for AI in domains that are currently bottlenecked by long-input processing.
Enhanced AI Capabilities: RLMs represent a significant step towards building more robust, reliable, and "cognitively" sophisticated AI systems. By enabling LLMs to engage with information interactively and recursively, they move beyond passive text processing towards active knowledge exploration and synthesis. This could lead to a reduction in hallucinations and an increase in factual consistency for complex tasks involving extensive data.
Industry-Specific Applications:
- Legal Sector: Analyzing entire legal briefs, contracts, or discovery documents, cross-referencing clauses, identifying precedents, and drafting summaries with precise factual recall. This could automate much of the painstaking manual review currently performed by legal professionals.
- Scientific Research: Reviewing vast scientific literature, synthesizing findings from multiple papers, identifying research gaps, and assisting in hypothesis generation by connecting disparate pieces of information.
- Healthcare: Processing comprehensive patient histories, medical journals, and clinical trial data to assist in diagnosis, treatment planning, and drug discovery, where every detail can be critical.
- Finance: Analyzing lengthy market reports, regulatory filings, and earnings transcripts to identify trends, assess risks, and inform investment decisions, requiring deep dives into complex financial narratives.
Future of Human-AI Interaction: As RLMs mature, they could facilitate more sophisticated and trustworthy human-AI collaborations. Imagine an AI assistant that can meticulously process a several-hundred-page report and then engage in a precise, fact-checked dialogue about its contents, always capable of drilling down into specific details or providing direct citations from the original document.
Conclusion
In conclusion, Recursive Language Models offer a compelling answer to the enduring challenge of long-input reasoning in large language models. By externalizing the prompt, enabling programmatic interaction, and employing genuine recursion, RLMs circumvent the limitations of "context rot" that plague traditional approaches. A useful rule of thumb for practitioners is this: if a task becomes disproportionately harder solely due to input length, and if existing solutions like summarization or retrieval risk losing critical information, then an RLM is a powerful candidate for consideration. For shorter inputs or simpler tasks, conventional language model calls remain faster and more cost-effective. However, as the demand for AI systems capable of deep, comprehensive understanding of vast information grows across industries, Recursive Language Models stand poised to become an indispensable tool, heralding a new era of intelligent interaction with complex textual data. This image, "Everything You Need to Know About Recursive Language Models," by the Editor, encapsulates the comprehensive ambition of this transformative technology.