

The global proliferation of artificial intelligence technologies has often been associated with vast computational power, meticulously curated datasets, and large engineering teams. However, a significant portion of real-world machine learning challenges exist within contexts marked by limited computing infrastructure, imperfect data quality, and minimal engineering support. This article delves into practical, robust strategies for developing and deploying useful machine learning solutions under such constraints, drawing lessons from real-world applications, particularly within sectors like agriculture in developing regions.
The conventional narrative of machine learning development frequently highlights advanced deep learning models, cloud-scale infrastructure, and highly optimized data pipelines. Yet, for countless small businesses, non-profit organizations, and local initiatives, especially those operating in rural areas or emerging economies, these resources are simply unavailable. This disparity often leads to the misconception that sophisticated analytical capabilities are out of reach. Contrary to this belief, impactful machine learning projects are frequently born in environments where computing power is modest, internet connectivity is inconsistent, and data might resemble a collection of handwritten logs rather than a meticulously structured database. These conditions, rather than being insurmountable obstacles, often foster ingenious and highly efficient approaches to problem-solving.

Defining the Low-Resource Landscape
Operating in a low-resource setting fundamentally alters the approach to machine learning. Key characteristics typically include:
- Limited Compute: Access to powerful servers, GPUs, or extensive cloud computing resources is restricted. Projects often rely on standard laptops, basic virtual machines, or older hardware. This necessitates algorithms with low computational complexity and efficient memory footprints.
- Imperfect Data: Datasets are rarely pristine. They frequently suffer from missing values, inconsistencies, noise, and lack of standardization. Data collection processes may be manual, prone to human error, or subject to unreliable sensor readings.
- Minimal Engineering Support: Dedicated MLOps teams, data engineers, or full-stack developers are often absent. The responsibility for data cleaning, model deployment, and maintenance may fall on a single individual or a small team with diverse roles.
- Unreliable Infrastructure: Intermittent internet access, unstable power grids, and lack of robust IT support can severely impact data transfer, model training, and continuous deployment efforts.
- Budgetary Constraints: Financial limitations often preclude investments in premium software licenses, extensive cloud subscriptions, or high-end hardware. Solutions must be cost-effective and leverage open-source tools where possible.
These constraints, while challenging, compel developers to prioritize efficiency, interpretability, and practical utility over theoretical complexity, leading to highly adaptable and resilient solutions.

The Strategic Advantage of Lightweight Machine Learning
In an era dominated by the hype surrounding deep learning and large language models, the utility of lightweight, classical machine learning models is often overlooked. However, in low-resource environments, these models—such as logistic regression, decision trees, random forests, and support vector machines—are invaluable assets. Their advantages are multifaceted:
- Computational Efficiency: They require significantly less processing power and memory, allowing them to run effectively on basic hardware. This translates to faster training times and quicker inference, crucial for iterative development and real-time applications.
- Interpretability: Classical models are generally more transparent. Their decision-making processes can be more easily understood and explained, which is vital for building trust among end-users, especially in critical applications like healthcare or agriculture. Farmers or community workers, for instance, need to understand why a certain recommendation is made to adopt it confidently.
- Robustness to Imperfect Data: While advanced models often demand massive, clean datasets, simpler models can perform surprisingly well with smaller, noisier inputs, provided effective feature engineering is applied.
- Reduced Carbon Footprint: The lower computational demands of lightweight models contribute to reduced energy consumption, aligning with growing concerns about the environmental impact of AI.
Successful applications of classical models include predicting crop yields based on soil and weather data, identifying potential disease outbreaks from limited health records, or optimizing inventory for small retailers. The emphasis shifts from achieving marginal gains in accuracy through massive models to securing significant, actionable insights with efficient, understandable tools.

Transforming Imperfect Data into Actionable Insights: The Art of Feature Engineering
When faced with chaotic or incomplete datasets—whether from broken sensors, missing sales logs, or unstructured notes—the ability to extract meaningful features becomes paramount. Feature engineering is not merely a preprocessing step; it is a creative process of transforming raw data into a format that better represents the underlying problem to the model.
- Temporal Features: Even inconsistent timestamps can yield rich information. Breaking them down into components like ‘day of the week,’ ‘hour of the day,’ ‘month,’ or ‘season’ can reveal crucial cyclical patterns. For instance, agricultural models might benefit from ‘days since last rain’ or ‘time of day of temperature peak.’
- Categorical Grouping: Datasets with a large number of unique categories can overwhelm simple models. Grouping granular categories into broader, more meaningful ones (e.g., individual product names into ‘perishables,’ ‘snacks,’ ‘tools’) reduces dimensionality and can highlight stronger patterns. This requires domain expertise to ensure logical groupings.
- Domain-Based Ratios: Ratios often provide more context and stability than raw numbers. Examples include ‘sales per employee,’ ‘crop yield per acre,’ or ‘cost of feed per unit of livestock.’ These ratios normalize data and can reveal efficiencies or inefficiencies that raw counts obscure.
- Robust Aggregations: To mitigate the impact of outliers (e.g., sensor malfunctions, data entry errors), using robust statistics like medians instead of means for aggregations is crucial. Medians are less sensitive to extreme values, providing a more stable representation of central tendency.
- Flag Variables: Binary ‘flag’ or ‘indicator’ variables are powerful for capturing specific events or conditions. Examples include ‘is_weekend,’ ‘is_holiday,’ ‘sensor_malfunction_flag,’ or ‘data_missing_flag.’ These flags provide the model with essential contextual information that can significantly improve its predictive power.
Navigating Missing Data: A Signal in the Silence

Missing data is a common predicament in low-resource settings, but it should not always be viewed as a problem to be eradicated. Sometimes, the very absence of data can be a valuable signal.
- Treat Missingness as a Signal: The fact that a data point is missing can itself convey information. For example, if farmers consistently skip certain entries in a log, it might indicate that the information is irrelevant to them, too difficult to obtain, or points to a specific issue in their farming practice. A separate binary feature indicating "data was missing for this field" can be highly informative.
- Simple Imputation Strategies: When imputation is necessary, simplicity is key. Medians, modes, or forward/backward fill are computationally inexpensive and often sufficiently effective. Complex multi-model imputation methods, while theoretically appealing, add computational overhead and can introduce noise or spurious correlations in low-resource contexts.
- Leveraging Domain Knowledge: Field experts possess invaluable insights into why data might be missing or what plausible values could be. For instance, a local agricultural expert might know the average rainfall during a specific planting season or understand typical holiday sales dips, allowing for more intelligent, context-aware imputation.
- Avoiding Complex Chains: Trying to impute every missing value from every other available feature can quickly become a convoluted and error-prone process. It is generally better to define a few solid, interpretable imputation rules based on domain knowledge and stick to them, rather than building an intricate imputation pipeline that is hard to debug or understand.
Maximizing Small Datasets: The Power of Transfer Learning
Even with limited local datasets, it is possible to leverage the vast knowledge embedded in larger, publicly available models through simplified forms of transfer learning. This approach allows developers to benefit from extensive pre-training without needing the resources to perform it themselves.
- Text Embeddings: For unstructured textual data like inspection notes, customer feedback, or farmer observations, using small, pre-trained word embeddings (e.g., Word2Vec, GloVe, or even lightweight BERT variants) can transform text into numerical vectors that capture semantic meaning. This provides rich features for models at a low computational cost.
- Global to Local Adaptation: A pre-existing model trained on a large, global dataset (e.g., a worldwide weather-yield model) can be fine-tuned or adapted using a small number of local samples. Often, simple linear adjustments or retraining the output layer of a pre-trained model can yield significant improvements tailored to local conditions.
- Feature Selection from Benchmarks: Public datasets or established benchmarks can guide the selection of relevant features, especially when local data is noisy or sparse. Identifying features that consistently prove important in similar problems on larger datasets can help prioritize data collection and feature engineering efforts.
- Time Series Forecasting: Borrowing seasonal patterns, trend components, or lag structures from global time series datasets can significantly enhance local time series forecasting, even with limited local historical data. These generalized patterns can be customized with local observations to improve accuracy for predicting demand, resource consumption, or environmental factors.
A Real-World Application: Smarter Crop Recommendations in Indian Agriculture
A compelling example of effective machine learning in a low-resource setting is demonstrated by a StrataScratch project focused on agricultural data from India. The project’s objective is to recommend optimal crops based on actual environmental conditions, including variable weather patterns and imperfect soil data.
The dataset used is modest, comprising approximately 2,200 rows, yet it captures critical agricultural parameters: soil nutrients (Nitrogen, Phosphorus, Potassium), pH levels, and basic climate information (temperature, humidity, rainfall). Rather than employing complex deep learning architectures, the analysis adheres to a principle of intentional simplicity, prioritizing interpretability and computational efficiency.

The methodology begins with foundational data exploration, including descriptive statistics to understand the distribution and central tendencies of key features. This is followed by visual exploration, such as histograms of temperature, humidity, and rainfall, to identify patterns and potential anomalies.
The core analytical step involves performing Analysis of Variance (ANOVA) tests. These statistical tests are used to determine if there are statistically significant differences in environmental factors (like humidity, rainfall, and temperature) across different crop types. For instance, an ANOVA test on humidity might reveal that certain crops thrive in significantly higher or lower humidity levels compared to others. Similar tests are conducted for rainfall and temperature.
The results of these ANOVA tests, while statistically rigorous, are inherently interpretable. A significant p-value for humidity across crop types indicates that humidity is a critical differentiating factor for crop success. This translates directly into practical guidance for farmers: "This crop performs better under high humidity" or "That crop tends to prefer drier conditions." Such clear, actionable insights are far more valuable to end-users than opaque predictions from complex models.

This entire workflow—from data loading and initial exploration to statistical testing—is designed to be lightweight. It leverages standard Python libraries like Pandas and Seaborn for data manipulation and visualization, and basic statistical functions for analysis. Crucially, all computations run smoothly on a regular laptop, negating the need for specialized hardware or expensive cloud services. This approach embodies the spirit of low-resource machine learning: grounded techniques, computationally gentle processing, and results that are easy to explain and act upon, even without advanced infrastructure. The project highlights how foundational statistical methods, combined with domain understanding, can deliver profound impact in real-world scenarios, contributing to better agricultural practices and potentially improved livelihoods for farmers.
The Future for Aspiring Data Scientists in Low-Resource Settings
For data scientists operating without the luxury of high-end GPUs, extensive cloud budgets, or perfectly clean datasets, a unique and highly valuable skill set is cultivated. These individuals learn to:

- Innovate with Constraints: They are forced to think creatively and find novel solutions within tight boundaries, fostering a problem-solving mindset that transcends mere technical execution.
- Prioritize Impact: The focus shifts from achieving marginal performance gains to delivering tangible, understandable value to real users facing concrete challenges.
- Master Foundational Skills: They develop a deep understanding of data cleaning, feature engineering, and classical statistics, skills that are often overlooked in the pursuit of cutting-edge, but resource-intensive, AI.
- Embrace Interpretability: The necessity of explaining model decisions to non-technical stakeholders instills a strong appreciation for model transparency and clear communication.
The journey in low-resource machine learning prioritizes:
- Understanding the Problem Deeply: Before touching any code, fully grasp the real-world context, user needs, and available resources.
- Clean and Engineer Features Relentlessly: This is where the most significant gains often lie.
- Choose the Simplest Model That Works: Avoid unnecessary complexity.
- Validate on Real-World Data: Test rigorously with imperfect, real-world data, not just sanitized benchmarks.
- Focus on Interpretability and Actionability: Ensure the insights provided are clear and can be acted upon by the end-users.
This practical, impact-driven approach is increasingly recognized as a hallmark of a truly effective data scientist, capable of navigating the complexities of diverse real-world challenges.
Conclusion
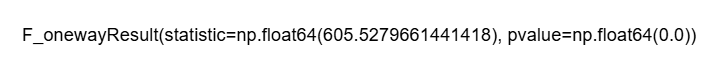
The landscape of machine learning extends far beyond the well-resourced environments often depicted in popular media. Working in low-resource settings demands creativity, resourcefulness, and a profound passion for solving real-world problems. It requires a pragmatic approach that prioritizes finding the signal within noisy data and translating complex findings into actionable insights for real people.
As explored in this article, the strategic deployment of lightweight models, meticulous feature engineering, intelligent handling of missing data, and clever reuse of existing knowledge through simplified transfer learning are not just workarounds; they are powerful methodologies. These strategies enable the development of robust, interpretable, and impactful machine learning solutions that can genuinely make life easier and more productive for individuals and communities globally, bridging the digital divide and democratizing access to advanced analytical capabilities. The growing success stories from these environments underscore the potential for innovation and impact that lies in embracing constraints and focusing on fundamental principles.