
When artificial intelligence (AI) developers and operations teams first integrate large language models (LLMs) into Kubernetes environments, the initial objective is typically functional: getting the model to run. The immediate success of an inference service, characterized by accurate responses and acceptable latency, often transforms a proof of concept into a production endpoint. This initial phase, often termed "Day 0" operations, can create a false sense of accomplishment, leading teams to believe the most challenging aspects have been surmounted. However, as AI adoption scales, the operational landscape undergoes a significant transformation, revealing the intricate complexities of "Day 1" and "Day 2" operations. These advanced stages of management grapple with the realities of running inference infrastructure reliably across diverse geographical regions, fluctuating traffic patterns, and multiple cloud providers, presenting a formidable challenge that extends far beyond the initial deployment.
To illustrate these infrastructure challenges concretely, consider a real-world use case: event-driven incident triage and root cause analysis (RCA). This scenario is particularly demanding, as it inherently combines several characteristics that place significant stress on AI platforms simultaneously. The critical nature of incident response demands low latency, unpredictable traffic spikes are a common occurrence, and the tolerance for failure is exceptionally low. A service degradation, for instance, might trigger an on-call engineer to be alerted. In a sophisticated system, this alert initiates a comprehensive data aggregation process. Logs from multiple services are collected, recent configuration changes and deployments are scrutinized, and metrics across various dependencies are correlated. The crux of this automated analysis lies in a large language model-powered step. This LLM evaluates the gathered signals and generates a structured summary, proposing a probable root cause for the incident. This summary is then disseminated into the incident management channel for human review and action.
The seemingly straightforward nature of this process belies the underlying technical complexities. The entire pipeline is critically dependent on GPU-backed inference capacity and consistently low-latency routing across different environments. The core challenge is not merely achieving a single model response under ideal conditions. Instead, it is the imperative to ensure that this multi-stage, model-dependent workflow operates with unwavering reliability and predictability, especially during periods of acute operational stress. This necessitates a robust infrastructure capable of handling dynamic demands and ensuring seamless execution under duress.
Common Pain Points in Scaling AI Platform Operations
Operating AI platforms at scale introduces a predictable set of pain points that frequently emerge as organizations move beyond initial deployments. These challenges often stem from the way infrastructure is provisioned, how models are exposed, and the fundamental architectural choices made in the early stages of adoption.
1. Fragmented GPU Capacity
A pervasive issue in AI operations is the fragmentation of GPU capacity. GPUs are typically acquired and deployed incrementally, often involving distinct Stock Keeping Units (SKUs) sourced from different regions and cloud providers. These acquisitions are frequently tied to specific projects, leading to a scattered distribution of valuable computational resources over time.
From a Kubernetes perspective, the ideal scenario is a unified scheduling domain. However, in practice, teams often find themselves with idle GPUs in one cluster or region while another is experiencing saturation. Even if the total aggregate GPU capacity across an organization is sufficient, it is rarely fungible. The ability to shift workloads seamlessly across regions or clouds is hampered by the need for external orchestration tools and the inherent increase in operational complexity. This fragmentation directly impacts the ability to dynamically allocate resources to meet fluctuating inference demands, a critical requirement for event-driven AI workloads.
2. Inconsistent Inference Interfaces
Another significant hurdle is the inconsistency in how AI models are exposed to consuming applications. Teams often adopt a variety of approaches, ranging from custom model servers and managed endpoints to lightweight HTTP wrappers. Each of these methods defines its own unique error semantics, scaling behaviors, and monitoring metrics.
For multi-stage AI pipelines, such as the incident triage example, this inconsistency creates tight coupling between different components. Application code must be engineered to handle disparate request formats and implement distinct retry logic for each model. Consequently, inference capabilities cease to function as a standardized platform primitive and instead become a collection of bespoke, application-specific integrations. This lack of uniformity hinders agility, increases maintenance overhead, and complicates the process of troubleshooting and scaling.
3. Batch-Oriented Infrastructure
Traditionally, GPU clusters have been optimized for steady-state batch workloads, where computational tasks are processed in large, predictable batches. However, event-driven inference, by its very nature, is characterized by bursty traffic patterns and stringent latency requirements. When infrastructure is provisioned and sized based on predictable, average demand, sudden spikes in traffic can lead to significant queuing delays or unacceptable increases in latency.
The fundamental mismatch lies in treating inference as an overlay on batch infrastructure. Instead, inference should be recognized and managed as a first-class, declaratively managed workload, equipped with elastic scheduling capabilities to adapt to real-time demand fluctuations. This paradigm shift is crucial for ensuring that AI applications can respond effectively to time-sensitive events.
A Kubernetes-Native Pattern for Scalable AI Infrastructure
To address these multifaceted challenges, a paradigm shift towards treating AI infrastructure as a standard cloud-native systems problem is essential. Rather than introducing a separate, bespoke control plane for managing models and GPUs, the strategy involves extending existing Kubernetes primitives—declarative state management, reconciliation loops, and advanced scheduling—to inference workloads.
A cloud-native AI architecture can be conceptually understood as comprising three logical layers, all operating on a shared Kubernetes control plane. This unified approach simplifies management and enhances operational efficiency.

Model Layer: Declarative Lifecycle Management
The model layer is responsible for managing the lifecycle of AI models declaratively, treating them as first-class Kubernetes resources. Several open-source projects are actively contributing to this space, including KServe, Ray Serve, and NVIDIA Dynamo. For the proposed architecture, the Kubernetes AI Toolchain Operator (KAITO), a project under the Cloud Native Computing Foundation (CNCF) Sandbox, serves as a key component.
KAITO unifies model definition and GPU provisioning into a single custom resource. Development teams can define their desired state, specifying the model type, configuration parameters, and specific GPU requirements. KAITO’s controllers then automatically reconcile this desired state with the actual cluster resources. By making resource requests explicit, KAITO provides the Kubernetes scheduler with the necessary information to place workloads predictably and efficiently. This approach transforms the Kubernetes cluster into the definitive source of truth for model deployment, eliminating the need for ad hoc scripts and significantly reducing operational risk, particularly during model updates or node pool changes. This declarative approach ensures that the entire model lifecycle, from deployment to scaling, is managed consistently and reliably.
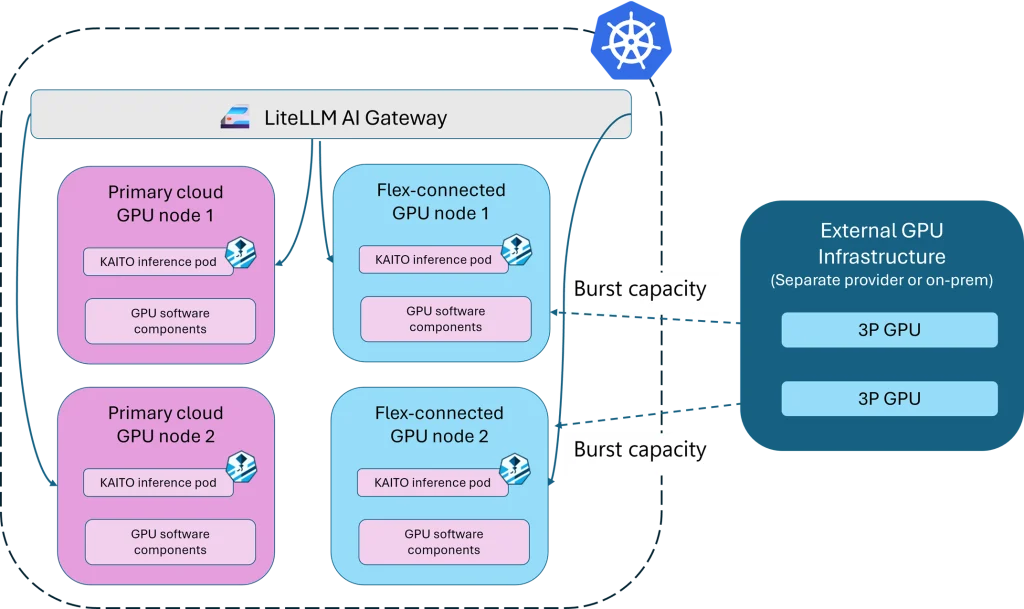
Inference Access Layer: Unified Gateway with liteLLM
The inference access layer is designed to centralize routing, rate limiting, and observability across a diverse range of models and providers. Projects such as the Kubernetes Gateway API Inference Extension, Envoy AI Gateway, and kgateway are addressing this critical need. For this architecture, liteLLM plays a pivotal role.
Instead of applications directly interacting with multiple, disparate model servers, all inference traffic is channeled through liteLLM. This provides a consistent API surface, abstracting away the underlying complexities of different model endpoints. In multi-stage AI pipelines, this unification significantly reduces coupling between services and simplifies failure handling mechanisms. Applications interact with a single, stable endpoint, while the liteLLM gateway transparently routes requests to the appropriate model version. It also handles retries and can seamlessly fall back to alternative compute nodes when necessary, ensuring high availability and resilience. This unified gateway is crucial for maintaining consistent performance and reliability in dynamic inference scenarios.
Compute Layer: Elastic GPU Scheduling with Flex Nodes
The compute layer directly tackles the challenges of GPU fragmentation and the need for elastic scaling to accommodate bursty demand. Projects like Karpenter, KubeFleet, and the Kubernetes Cluster Autoscaler offer various approaches to this problem. In this architecture, GPU Flex Nodes are employed to provide a flexible and integrated solution.
GPU Flex Nodes enable GPU-backed nodes from multiple cloud providers or regions to join a single Kubernetes cluster. The scheduling of inference workloads then occurs natively within Kubernetes, leveraging the declaratively defined resource requirements originating from the model layer. Workloads are intelligently placed where GPU capacity is available, irrespective of their original cloud provider or specific cluster. This distributed approach significantly enhances resource utilization and eliminates the operational friction traditionally associated with managing fragmented GPU environments across diverse infrastructure. This capability is particularly vital for event-driven AI, where rapid scaling is paramount.
Why This Pattern Fits Event-Driven AI Workloads
The architectural pattern described—unifying model lifecycle, inference access, and compute under a single Kubernetes control plane—is particularly well-suited for event-driven AI workloads. These types of workloads, such as incident triage and automated analysis, inherently demand rapid scale-up capabilities and predictable routing mechanisms, especially when faced with unpredictable surges in demand.
In this proposed architecture, when an alert triggers an AI-driven workflow, the data analysis and inference processes are executed as native Kubernetes components. Inference requests are efficiently routed through liteLLM, ensuring a consistent interface and intelligent load balancing. Subsequently, these requests are scheduled onto available GPU nodes, with the system capable of dynamically spanning across multiple clouds if necessary. The predictability and reliability of the entire system are maintained because the model lifecycle, inference routing, and underlying compute resources are all managed cohesively under a single, unified control plane. This integration allows for swift and dependable responses to critical events.
Looking Ahead: The Future of AI Operations on Kubernetes
Ultimately, the operational complexities associated with AI workloads do not necessitate a separate, distinct operational paradigm. By standardizing the management of model lifecycle, inference services, and GPU capacity as first-class Kubernetes primitives, teams can leverage the inherent benefits of declarative configuration and elastic scheduling.
With the integration of components like KAITO, liteLLM, and GPU Flex Nodes within a cloud-native architecture, platform engineers can establish a robust and reliable foundation for AI developers. This approach transforms cross-cloud GPU capacity into a fungible resource, empowering workloads to scale elastically and fail over efficiently in the face of disruptions.
As Kubernetes clusters increasingly span multiple regions and providers, topology-aware scheduling will become an even more critical capability. Future scheduling decisions can dynamically incorporate factors such as network latency, data locality, and cost considerations. These factors can be expressed declaratively within the cluster configuration, rather than being hardcoded into application logic. This advancement will lead to more intelligent scaling and failover mechanisms, all while adhering to established cloud-native, Kubernetes-driven principles. This evolution promises to streamline AI operations and enhance the resilience and efficiency of AI-powered systems.
The ongoing development and adoption of these cloud-native patterns signify a maturing landscape for AI infrastructure management. The ability to treat AI workloads with the same rigor and efficiency as traditional cloud-native applications underscores the power and adaptability of Kubernetes as a universal platform for modern computing. As organizations continue to push the boundaries of AI, the underlying infrastructure must evolve in parallel, ensuring that innovation is not hindered by operational complexities. The future of AI operations on Kubernetes is one of integration, standardization, and intelligent automation, paving the way for more resilient and scalable AI deployments across the globe.