
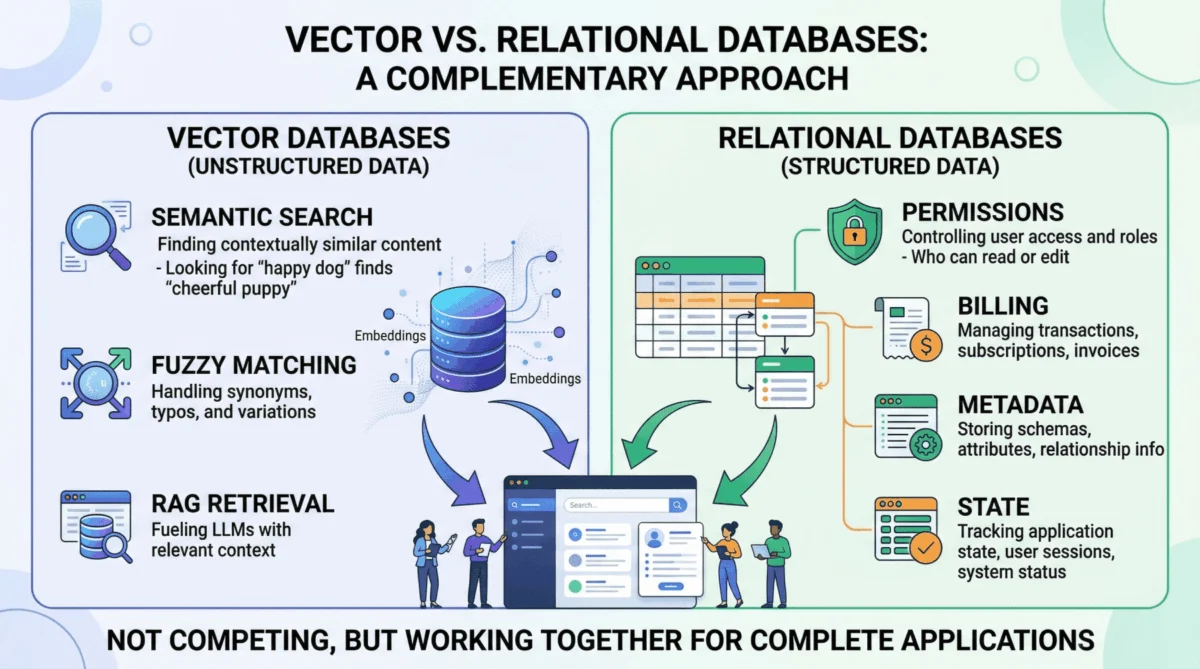
In the rapidly evolving landscape of artificial intelligence, particularly with the proliferation of large language models (LLMs) and generative AI, a critical understanding is emerging regarding the foundational data infrastructure required for production-grade applications. While the initial wave of AI development often highlighted vector databases as the singular innovation for AI data layers, industry experience is unequivocally demonstrating that enterprise-ready AI systems necessitate a sophisticated interplay between vector databases, optimized for semantic retrieval, and traditional relational databases, which remain indispensable for structured, transactional workloads and stringent data integrity. This synergy is not merely an architectural preference but a fundamental requirement for applications that handle real users, sensitive data, financial transactions, and compliance mandates.
The advent of powerful LLMs has democratized access to advanced natural language understanding and generation, sparking a revolution across industries. However, these models, while incredibly capable, often suffer from "hallucinations" – generating plausible but factually incorrect information – especially when detached from specific, authoritative context. This challenge led to the widespread adoption of Retrieval Augmented Generation (RAG), a paradigm where an AI system first retrieves relevant information from a knowledge base before generating a response. Vector databases, designed to store and efficiently query high-dimensional numerical representations (embeddings) of data, became the cornerstone of this RAG architecture. They excel at identifying conceptually similar data points, allowing an AI agent to search for "tenant rights regarding mold and unsafe living conditions" and retrieve documents mentioning "habitability standards" or "landlord maintenance obligations," even without exact keyword matches. This capability transformed how unstructured data, from legal documents to customer support tickets, could be leveraged by AI.
However, the initial enthusiasm sometimes overshadowed the inherent limitations of vector databases. While unparalleled for meaning-based retrieval, their probabilistic nature, a strength in semantic search, becomes a critical vulnerability in scenarios demanding absolute precision and deterministic outcomes. For instance, retrieving all support tickets created by a specific user ID within a defined date range, or calculating the sum of API token usage for billing purposes, are tasks where a vector similarity search is fundamentally inadequate. It cannot guarantee the inclusion of every matching record or the exclusion of non-matching ones. These are exact-match, aggregation, and transactional operations that fall squarely within the domain of relational databases, systems honed over decades for such tasks.
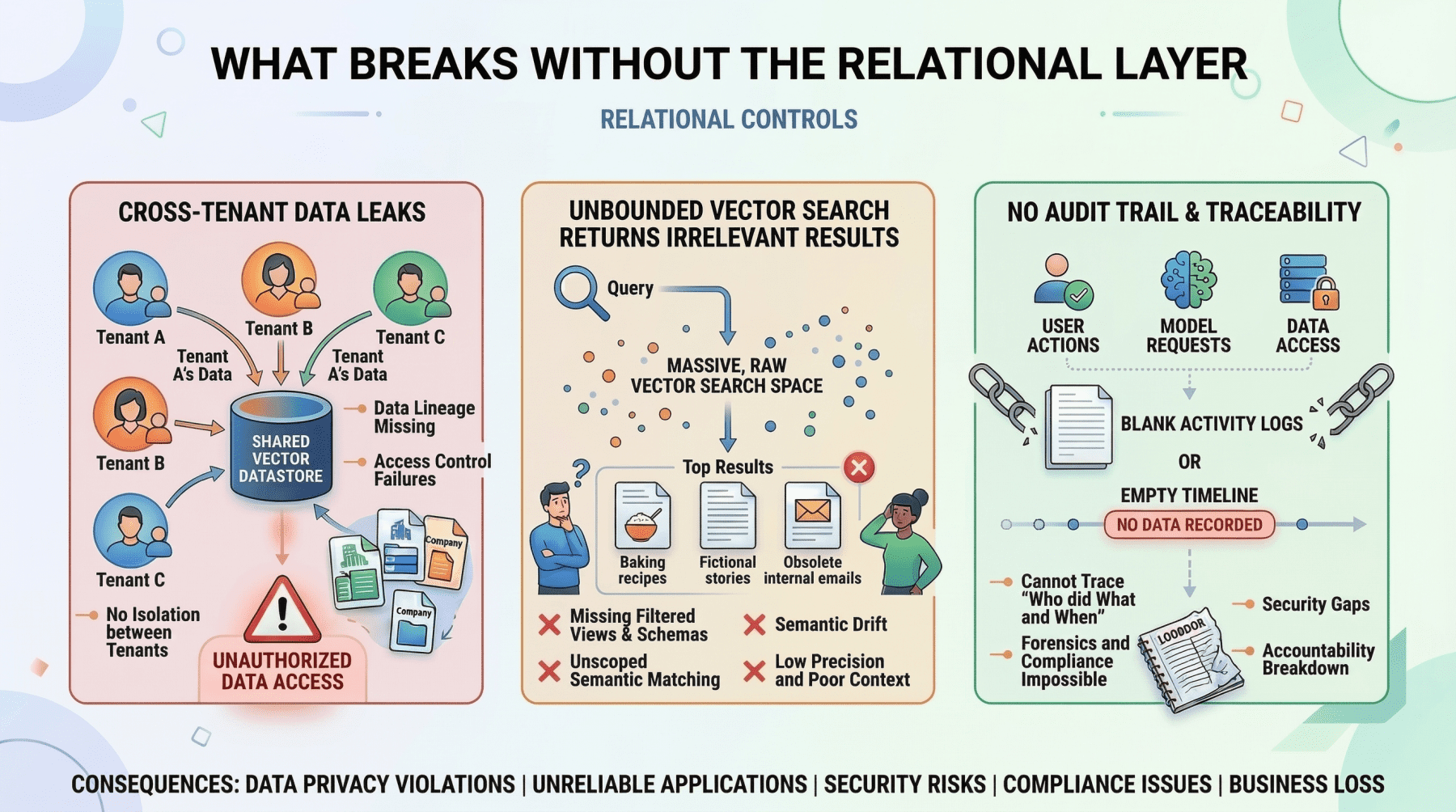
Relational databases, such as PostgreSQL and MySQL, are the operational backbone of virtually all complex software applications, and AI is no exception. They manage "hard facts" with unwavering precision, guaranteeing data integrity through ACID (Atomicity, Consistency, Isolation, Durability) properties. In an AI context, this translates to several critical domains. Firstly, user identity and access control are paramount. An AI agent must precisely enforce role-based access control (RBAC) permissions, ensuring that a junior analyst cannot access confidential financial reports, regardless of how "semantically similar" their query might be to a permitted document. This is a binary, non-negotiable security boundary that only a relational database can definitively manage.
Secondly, metadata management for embeddings is frequently overlooked but vital. While a vector database stores the semantic representation of a document chunk, the relational database holds crucial contextual information: the document’s original URL, author ID, upload timestamp, file hash, and critically, departmental access restrictions. This metadata layer is the bridge connecting the abstract semantic index to the concrete realities of organizational structure and data governance. Without it, the vector embeddings lack essential context for authorization, auditing, and presentation.
Thirdly, relational databases are instrumental in pre-filtering context to drastically reduce the likelihood of LLM hallucinations. Before an AI project management agent summarizes "all high-priority tickets resolved in the last 7 days for the frontend team," an exact SQL query must first isolate precisely those tickets. This deterministic filtering ensures the LLM only reasons over accurately scoped, factual data, making the process cheaper, faster, and significantly more reliable than attempting to achieve the same specificity with vector search alone. This practice is increasingly recognized as a best practice in robust RAG implementations.
Finally, core enterprise functions like billing, audit logs, and compliance are inherently structured data problems. Every financial transaction, every user action, every data access event needs to be recorded with transactional consistency and immutability. Relational databases, with their mature capabilities for structured queries, indexing, and transactional guarantees, have been solving these problems reliably for decades. Industry analysts consistently highlight that the legal and regulatory implications of AI demand this level of data integrity, making the relational layer non-negotiable for any enterprise deploying AI. According to a 2023 report by Gartner, over 70% of new enterprise applications still rely on relational databases for their core transactional workloads, a testament to their enduring relevance even in the age of specialized data stores.
The limitation of relational databases, in turn, is their lack of native semantic understanding. Searching for conceptually similar passages across millions of rows of raw text using traditional SQL pattern matching is computationally expensive and yields inferior results compared to vector search. This is precisely the void that vector databases are designed to fill, illustrating the complementary nature of these technologies rather than their competitive positioning.
Recognizing these distinct strengths, the most effective AI applications are adopting hybrid architectures where vector and relational databases operate in lockstep, each handling its specialized tasks. Two prevalent patterns have emerged.
The Pre-Filter Pattern leverages the precision of SQL to narrow down the search space before engaging the vector database. Consider a multi-tenant customer support AI. When a user from "Company A" asks about "refund policy for enterprise contracts," the application first queries the relational database to identify documents specific to Company A and accessible to the user’s permissions. Only then is a vector search performed on this pre-filtered, authorized corpus. This sequence is critical for security; without relational pre-filtering, the vector search might inadvertently retrieve semantically relevant but unauthorized documents from Company B or restricted documents from Company A, leading to severe data breaches. This pattern is a fundamental security boundary, not an optional optimization. Data breaches resulting from inadequate access control in AI systems are a growing concern for compliance officers, with recent reports indicating a significant uptick in incidents related to sensitive data exposure in poorly architected AI applications.
Conversely, the Post-Retrieval Enrichment Pattern involves using the relational database to augment results obtained from a vector search. After a vector search identifies the most semantically relevant document chunks, the application queries the relational database to fetch associated structured metadata. For example, an internal knowledge base agent might retrieve three relevant passages via vector search, then join against a relational table to append the author’s name, the last-updated timestamp, and the document’s confidence rating. This enriched context allows the LLM to generate more nuanced and verifiable responses, such as: "According to the Q3 security policy (last updated October 12th, authored by the compliance team)…" This adds authority and transparency to the AI’s output.
For many organizations, the operational complexity and cost of managing two distinct database systems can be a deterrent, especially at moderate scales. This is where solutions like pgvector, the vector similarity extension for PostgreSQL, offer a compelling alternative. pgvector allows embeddings to be stored directly as a column within a traditional PostgreSQL table, alongside structured relational data. This unified approach enables a single query to combine exact SQL filters, complex joins, and vector similarity search in one atomic operation, all within the familiar PostgreSQL ecosystem. For example, a single pgvector query can:
SELECT d.title, d.author, d.updated_at, d.content_chunk,
1 - (d.embedding <=> query_embedding) AS similarity
FROM documents d
JOIN user_permissions p ON p.department_id = d.department_id
WHERE p.user_id = 'user_98765'
AND d.status = 'published'
AND d.updated_at > NOW() - INTERVAL '90 days'
ORDER BY d.embedding <=> query_embedding
LIMIT 10;This single transaction demonstrates secure access control by joining user_permissions, applies precise structured filtering based on status and updated_at (a form of pre-filtering), and then performs semantic similarity search on the remaining, authorized content chunks. This eliminates the need for synchronization between separate systems and significantly simplifies the data architecture. According to figures from the PostgreSQL community, pgvector has seen exponential adoption, especially among startups and mid-sized enterprises looking to integrate AI capabilities without incurring the overhead of a dedicated vector database infrastructure.
However, pgvector does present a performance tradeoff at extreme scales. Dedicated vector databases like Pinecone, Milvus, or Weaviate are purpose-built and highly optimized for approximate nearest neighbor (ANN) search across billions of vectors, often leveraging specialized indexing algorithms and distributed architectures. At such scales, they will typically outperform pgvector. Yet, for applications with corpora ranging from hundreds of thousands to a few million vectors, pgvector offers a robust, cost-effective solution, postponing the need for a separate, specialized vector store until scale demands it. This "start simple, scale later" approach aligns with modern DevOps principles.
The decision framework for selecting the appropriate architecture is relatively straightforward: For applications requiring massive-scale vector search (billions of vectors) or specific, advanced vector indexing features, a dedicated vector database alongside a relational database is likely the optimal choice. For most other production AI applications, particularly those prioritizing operational simplicity and unified data management for corpora in the millions or less, pgvector within PostgreSQL provides an excellent balance of capability and convenience. Crucially, in either scenario, the relational layer remains non-negotiable; it is the steadfast guardian of user identities, access permissions, metadata, billing records, and overall application state.
In conclusion, the narrative around AI data infrastructure has matured beyond the initial hype of vector databases as a standalone panacea. While vector databases are undoubtedly a critical enabler for semantic retrieval and RAG architectures, their inherent probabilistic nature dictates a clear boundary where their utility ends and the deterministic reliability of relational databases begins. Production AI applications, particularly those operating in regulated environments or handling sensitive enterprise data, require the robust transactional consistency, precise structured querying, and comprehensive data governance capabilities that only a relational database can provide. The most resilient and effective AI architectures are those that strategically integrate both vector and relational technologies, leveraging each where it is strongest. This dual imperative ensures not only the intelligence and adaptability of AI but also its security, accuracy, and operational integrity, paving the way for truly transformative and trustworthy AI solutions across the global economy.