
The rapid acceleration of artificial intelligence deployment is precipitating a fundamental transformation in data center design, shifting the focus from raw computational power to the efficiency of the underlying network fabric. As industry leaders like NVIDIA unveil next-generation platforms such as the Rubin architecture, a consensus is emerging among systems architects: the data center network is no longer merely a communication layer between isolated servers but has become an integral component of a distributed memory and storage hierarchy. This transition is driven by the unique and increasingly rigorous demands of AI inference, which requires a level of deterministic performance and sustained throughput that traditional network architectures were never designed to provide.
The Shift from Probabilistic to Deterministic Infrastructure
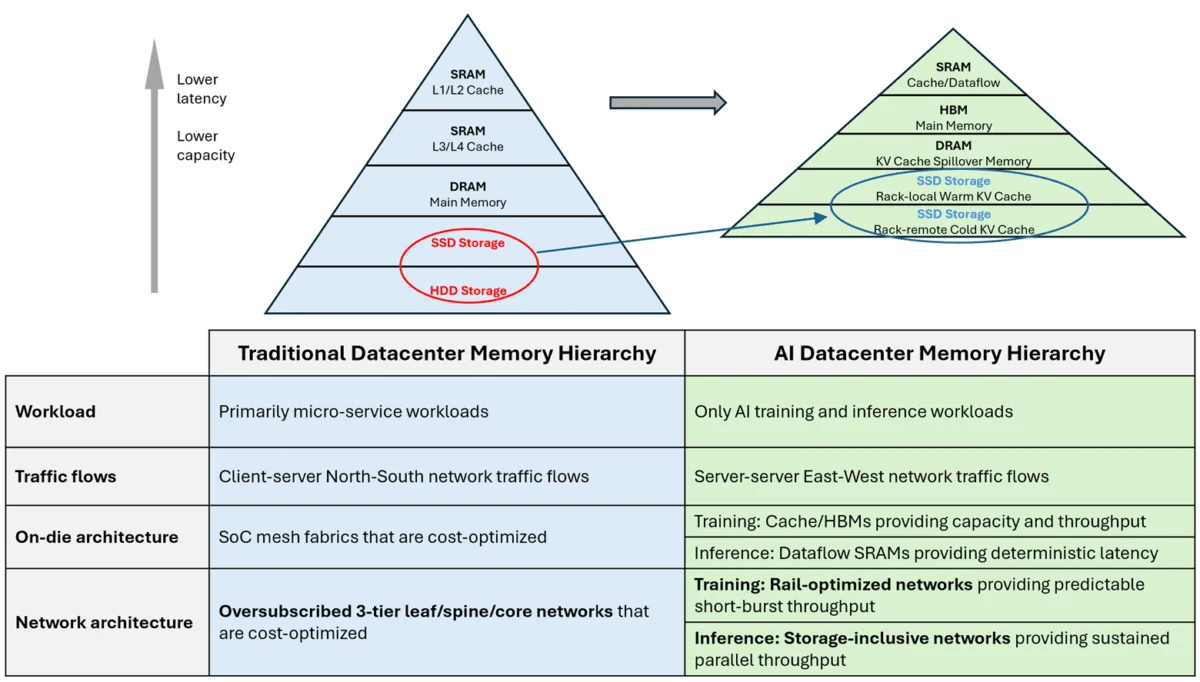
To comprehend the magnitude of this architectural shift, it is necessary to examine the historical trajectory of data center evolution. For decades, the "classic" data center was optimized for general-purpose cloud computing, characterized by microservices and client-server interactions. In this era, traffic patterns were primarily "North-South"—moving between the user and the data center—and were characterized by their probabilistic and bursty nature.
Architecturally, this led to the widespread adoption of oversubscribed three-tier networks consisting of leaf, spine, and core switches. Because traffic was sparse and bursts were brief, network designers could rely on statistical multiplexing. Technologies such as Equal-Cost Multi-Path (ECMP) routing and local buffer management were sufficient to handle transient congestion. If a "cache miss" occurred or a brief traffic spike hit a specific link, the system’s overall performance remained stable on average, as the probability of sustained, simultaneous collisions across the entire fabric was low.
However, the rise of Large Language Models (LLMs) and generative AI has rendered these probabilistic assumptions obsolete. The industry is moving toward a deterministic model where the network must behave with the precision of an on-chip bus, ensuring that data reaches the processor exactly when needed to prevent computational stalls.
The Training Era: Synchronized Bursts and East-West Dominance
The first major disruption to the classic model arrived with the era of large-scale AI training. Training deep learning models requires massive synchronization across thousands of GPUs, shifting the primary traffic flow to an "East-West" pattern—server-to-server communication within the data center.
Training workloads introduced "collective operations," such as All-Reduce and All-to-All, which generate intense, highly synchronized bursts of communication. To meet these demands, the industry developed rail-optimized fabrics and high-bandwidth interconnects like NVIDIA’s NVLink and InfiniBand. These systems were designed to provide non-blocking, high-speed paths between tightly coupled GPUs.
While training is bandwidth-intensive, it remains somewhat tolerant of transient congestion. Training fabrics utilize internal buffers to absorb "incast"—a phenomenon where multiple sources send data to a single destination simultaneously. Because these bursts are typically short-lived and tied to specific phases of the training algorithm, the buffers can drain before the next cycle begins. In this context, the network acts as a high-speed buffer, managing the ebb and flow of data as models are iteratively refined.
The Inference Challenge: Sustained Elephant Flows and the Memory Wall
The current shift toward massive-scale inference, particularly for LLMs with expansive context windows, has introduced a far more grueling set of requirements. Unlike training, which is a batch process, inference is a continuous service. As models grow in size, they often exceed the physical memory capacity of a single GPU or even a single server node. This necessitates the frequent loading of Key-Value (KV) cache state from pooled memory and storage systems.
This requirement gives rise to "elephant flows"—long-lived, continuous high-bandwidth data streams that persist for the duration of an inference request. When a user interacts with an AI, the system may need to stream tens of gigabytes of data from remote DDR or flash-backed SSD tiers. Because thousands of these requests occur simultaneously and continuously, the network is no longer dealing with transient bursts but with persistent, unrelenting pressure on its links.
In a network designed for probabilistic traffic, these sustained flows lead to chronic congestion. Traditional buffering strategies fail because no buffer is large enough to hold an elephant flow indefinitely. Furthermore, standard ECMP routing often fails to distribute these long-lived flows effectively, leading to "hot spots" where certain links are overwhelmed while others remain idle. Consequently, storage is being redefined; it is no longer an external repository but a high-performance extension of the GPU’s own memory, accessed via a low-latency, high-performance fabric.

Chronology of Data Center Interconnect Evolution
The transition to inference-optimized networking can be viewed through a timeline of technological milestones that have redefined the industry:
- 2010–2017: The Ethernet Dominance. Data centers focused on 10G and 40G Ethernet, optimizing for "North-South" web traffic and virtualization.
- 2017–2022: The Training Explosion. The release of the Transformer model architecture led to the rise of 100G and 400G InfiniBand and specialized "Scale-Up" fabrics. This period saw the introduction of the Data Processing Unit (DPU) to offload networking tasks.
- 2023–2024: The Inference Pivot. The industry began prioritizing "Scale-Out" memory architectures. NVIDIA announced the Blackwell and Rubin platforms, emphasizing unified memory fabrics and the BlueField-4 DPU, which integrates inference-context memory storage.
- 2025 and Beyond: The Deterministic Era. Expected deployment of 1.6T networking and the maturation of the Ultra Ethernet Consortium (UEC) standards, aimed at providing the reliability of InfiniBand with the scale of Ethernet to support sustained inference loads.
Supporting Data: The Growing Scale of AI Networking
Recent market data highlights the shift in capital expenditure toward networking. According to industry analysts, the networking component of AI clusters, which historically accounted for roughly 10% of total hardware costs, is projected to rise toward 20-25% as inference demands grow.
- Bandwidth Requirements: Modern LLM inference can require memory bandwidth exceeding 5 terabytes per second (TB/s). With HBM3e and upcoming HBM4 technologies, the "memory wall" is being pushed to the network level, requiring external fabrics to match these speeds to avoid bottlenecks.
- Switch Radix Evolution: To reduce latency and congestion, switch radix (the number of ports per switch chip) has increased from 32 and 64 to 128 and higher. High-radix switches enable "flatter" networks with fewer hops, which is critical for maintaining the deterministic timing required for KV cache retrieval.
- Power Consumption: Networking now accounts for a significant portion of a data center’s power envelope. The transition to optical interconnects and co-packaged optics is being accelerated specifically to handle the sustained power load of inference-driven elephant flows.
Industry Responses and Strategic Shifts
Major technology providers are realigning their roadmaps to address the inference-memory bottleneck. NVIDIA’s Rubin platform is a primary example, focusing on a "context-aware" memory hierarchy where the BlueField-4 DPU acts as a gatekeeper for distributed storage. By treating the network as a memory fabric, NVIDIA aims to allow GPUs to access remote data with the same ease as local HBM.
The Ultra Ethernet Consortium (UEC), which includes members like AMD, Arista, Broadcom, and Cisco, is working on a new transport protocol designed to replace the aging TCP/IP for AI workloads. Their goal is to create a protocol that can handle sustained flows without the packet loss and "jitter" that plague traditional Ethernet, effectively bringing deterministic behavior to open-standard networking.
Hyperscalers such as Amazon Web Services (AWS) and Google Cloud are also developing custom silicon—such as the Trainium/Inferentia and TPU chips—that feature proprietary inter-chip interconnects. These designs prioritize direct memory access (DMA) across the network, allowing a cluster of thousands of chips to function as a single, giant computer with a unified memory space.
Fact-Based Analysis of Implications
The transformation of the data center network into a memory fabric has several long-term implications for the technology sector:
1. The End of "Best-Effort" Networking:
The industry is moving away from the "best-effort" delivery model of the internet. In the AI data center, the network must provide guaranteed service levels. This requires sophisticated telemetry and automated congestion control that can reroute traffic in real-time before buffers overflow.
2. Integration of Storage and Compute:
The traditional boundary between "storage" (where data sits) and "compute" (where data is processed) is blurring. With inference, the network becomes the "bus" that connects them. This will likely lead to the rise of "Computational Storage," where simple data processing tasks are performed within the network fabric itself to reduce the amount of data that needs to travel to the GPU.
3. Economic and Environmental Impact:
The move toward flatter, higher-radix networks and specialized AI fabrics requires massive capital investment. However, by increasing the efficiency of inference, operators can reduce the "cost per token," making AI services more commercially viable. From a sustainability perspective, the focus on deterministic networking helps reduce wasted compute cycles—and thus wasted power—caused by processors waiting for data.
Conclusion: The Network as the Computer
As AI inference becomes the dominant workload in global data centers, the metrics of success are shifting. While raw TeraFLOPS of compute power remain important, they are no longer the sole determinant of performance. Instead, the ability to sustain massive, parallel data movements across a distributed memory hierarchy has become the new benchmark for excellence.
The data center network has evolved from a simple utility into a sophisticated memory fabric. This evolution, exemplified by the move toward high-radix switches and non-blocking architectures, represents a permanent change in how humanity builds its most powerful machines. In the era of generative AI, the network is no longer just connecting systems; it is the system. Performance, efficiency, and the very future of AI development now depend on the industry’s ability to master the complexities of this new, deterministic networking landscape.