
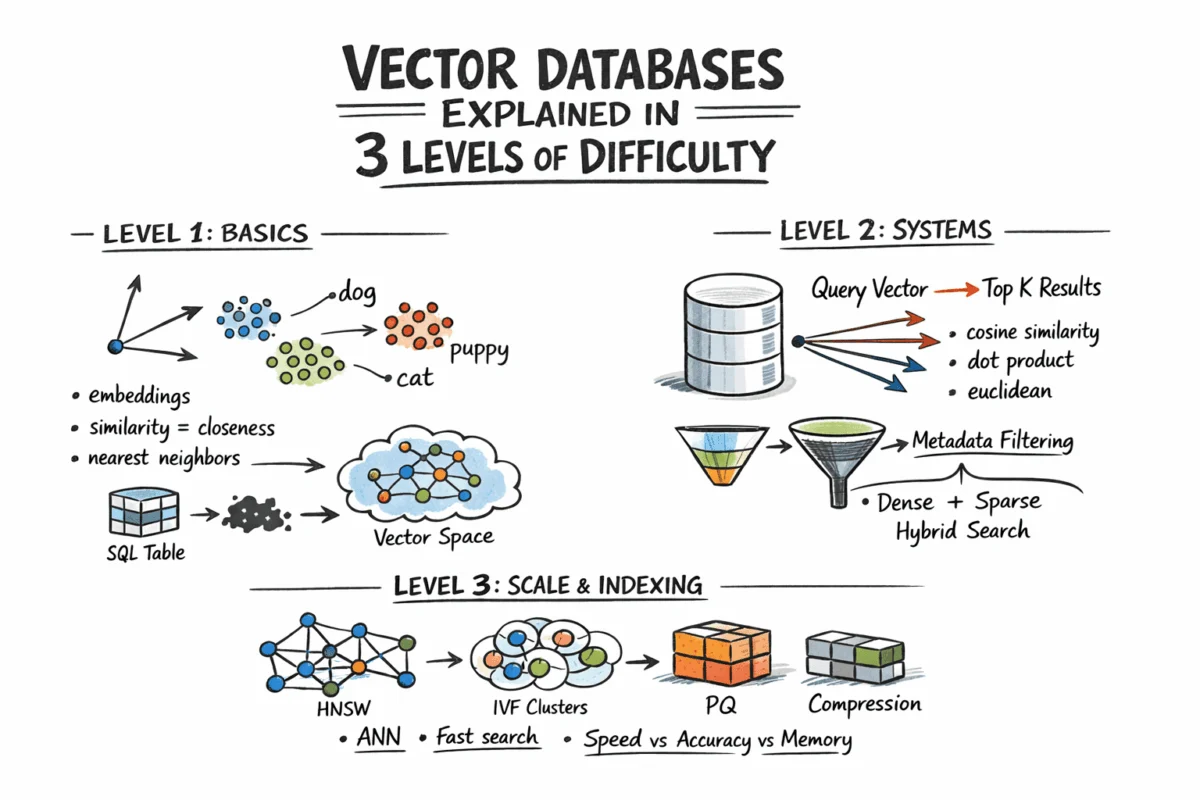
The modern data landscape is awash with unstructured information—documents, images, audio, video, and user behavior logs—a deluge that traditional database systems, designed for precise, exact-match queries on structured rows and columns, are ill-equipped to handle. In this new paradigm, the critical question is no longer "does this record exist?" but rather "which records are most similar to this?" This fundamental shift has propelled vector databases from a specialized niche into an indispensable component of contemporary artificial intelligence (AI) and machine learning (ML) architectures, enabling semantic search at unprecedented scales.
The Unstructured Data Challenge and the Rise of Semantic Search
For decades, databases excelled at managing structured data, where SQL queries could efficiently retrieve information based on exact values or predefined ranges. However, the explosion of digital content in the 21st century—estimated to be growing at an exponential rate, with unstructured data comprising 80-90% of all new data generated—revealed a significant gap. A photograph of a cat, a voice command, or a lengthy research paper cannot be meaningfully queried using exact string matches or numerical ranges. The need arose for systems capable of understanding the meaning or context of data, rather than just its literal form.
This is where semantic search, powered by vector databases, enters the picture. The core innovation lies in representing complex, unstructured content as numerical vectors—fixed-length arrays of floating-point numbers. These "embeddings" are generated by sophisticated machine learning models, often deep neural networks, trained to capture the semantic essence of the input. Crucially, content that is semantically similar will yield vectors that are geometrically close in this high-dimensional vector space. For instance, an embedding model might place vectors for "dog" and "puppy" very near each other, just as a picture of a cat and a drawing of a cat would be represented by closely aligned vectors. This transformation allows for a completely new mode of data retrieval: finding "what is close to this" instead of "find this."
The Foundation: Embeddings and Vector Space
Before any vector database can function, raw content must be converted into these numerical embeddings. This process is typically handled by specialized embedding models. For text, models like Google’s BERT (Bidirectional Encoder Representations from Transformers), OpenAI’s GPT series (Generative Pre-trained Transformers), or dedicated embedding models such as text-embedding-3-small from OpenAI, convert sentences or documents into dense vectors, often ranging from 256 to 4096 dimensions. For images, vision models like CLIP (Contrastive Language-Image Pre-training) can generate embeddings that represent visual concepts. The specific values within an embedding vector hold no direct human-interpretable meaning; their significance lies purely in their geometric relationship to other vectors. A typical workflow involves passing content to an embedding API or running an inference model locally, receiving an array of floats, and then storing this array alongside any associated metadata.
The similarity between these vectors is quantified using various distance metrics. The choice of metric is crucial and should align with how the embedding model was trained, as using an inappropriate metric can significantly degrade search quality.
- Cosine Similarity: This measures the cosine of the angle between two vectors. It is widely used, particularly for text embeddings, as it focuses on the orientation of the vectors rather than their magnitude. A value close to 1 indicates high similarity, while -1 indicates dissimilarity.
- Euclidean Distance: Also known as L2 distance, this is the straight-line distance between two points in Euclidean space. Smaller Euclidean distances imply greater similarity. It is often suitable for embeddings where magnitude is also a relevant factor.
- Dot Product: This metric calculates the projection of one vector onto another. While mathematically related to cosine similarity (especially if vectors are normalized), it can also reflect vector magnitude, making it useful in certain contexts like recommendation systems where the "strength" of a preference might be encoded in magnitude.
The Challenge of Scale: Exact vs. Approximate Nearest Neighbor Search
While the concept of finding the "nearest neighbors" in vector space is straightforward, its implementation at scale presents a formidable computational challenge. For small datasets, a "brute-force" or "flat" search—where the query vector is compared against every single stored vector—is 100% accurate. However, this approach scales linearly with the dataset size. In real-world applications, where databases might contain tens of millions, hundreds of millions, or even billions of vectors, each potentially having hundreds or thousands of dimensions, a brute-force comparison requires billions of floating-point operations. This makes real-time search impractical, leading to unacceptably high latencies.
The solution to this computational bottleneck is Approximate Nearest Neighbor (ANN) algorithms. These algorithms cleverly trade a minuscule amount of accuracy for massive gains in speed, enabling near real-time retrieval even with colossal datasets. Production-grade vector databases universally rely on ANN algorithms to deliver their performance. While they might not guarantee the absolute closest vector every single time, they consistently return results that are highly similar to an exhaustive search, often achieving recall rates above 95% at a fraction of the computational cost. The specific algorithms, their tuning parameters, and their inherent trade-offs in terms of speed, memory usage, and recall are central to the effectiveness of any vector database.
Key Approximate Nearest Neighbor Algorithms
Several ANN algorithms have emerged as industry standards, each occupying a distinct point on the performance-resource spectrum:
-
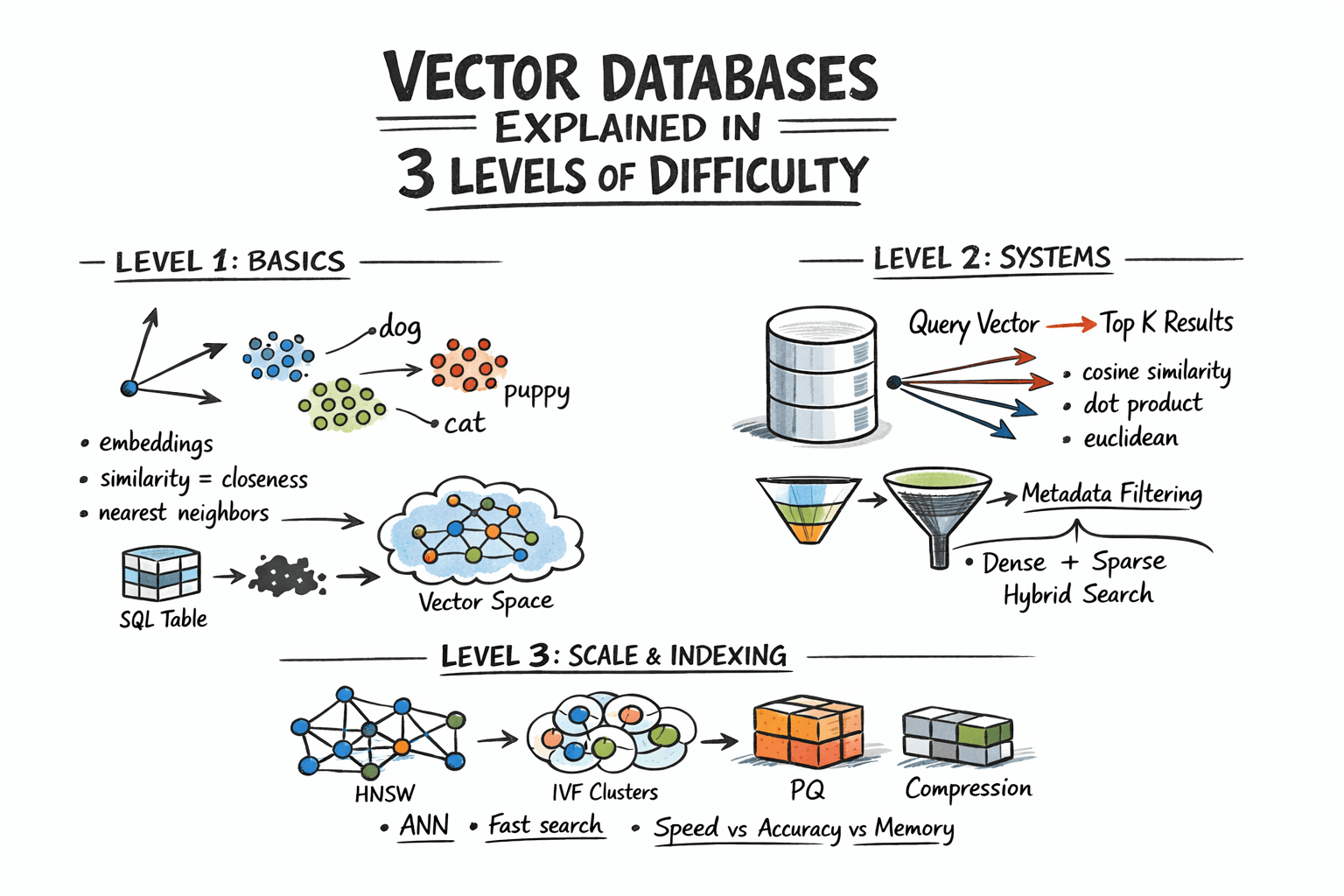
Hierarchical Navigable Small World (HNSW): Considered a gold standard in many modern systems, HNSW constructs a multi-layer graph. Each vector is represented as a node, with edges connecting similar neighbors. Higher layers of the graph are sparse, allowing for rapid, long-range traversal to quickly narrow down the search space. Lower layers are denser, facilitating a more precise local search once the general vicinity of the nearest neighbors is identified. At query time, the algorithm efficiently navigates this graph, moving towards the closest nodes. HNSW is renowned for its exceptional speed and high recall, making it a popular choice for latency-sensitive applications. Its primary trade-off is its relatively higher memory consumption compared to other methods.
-
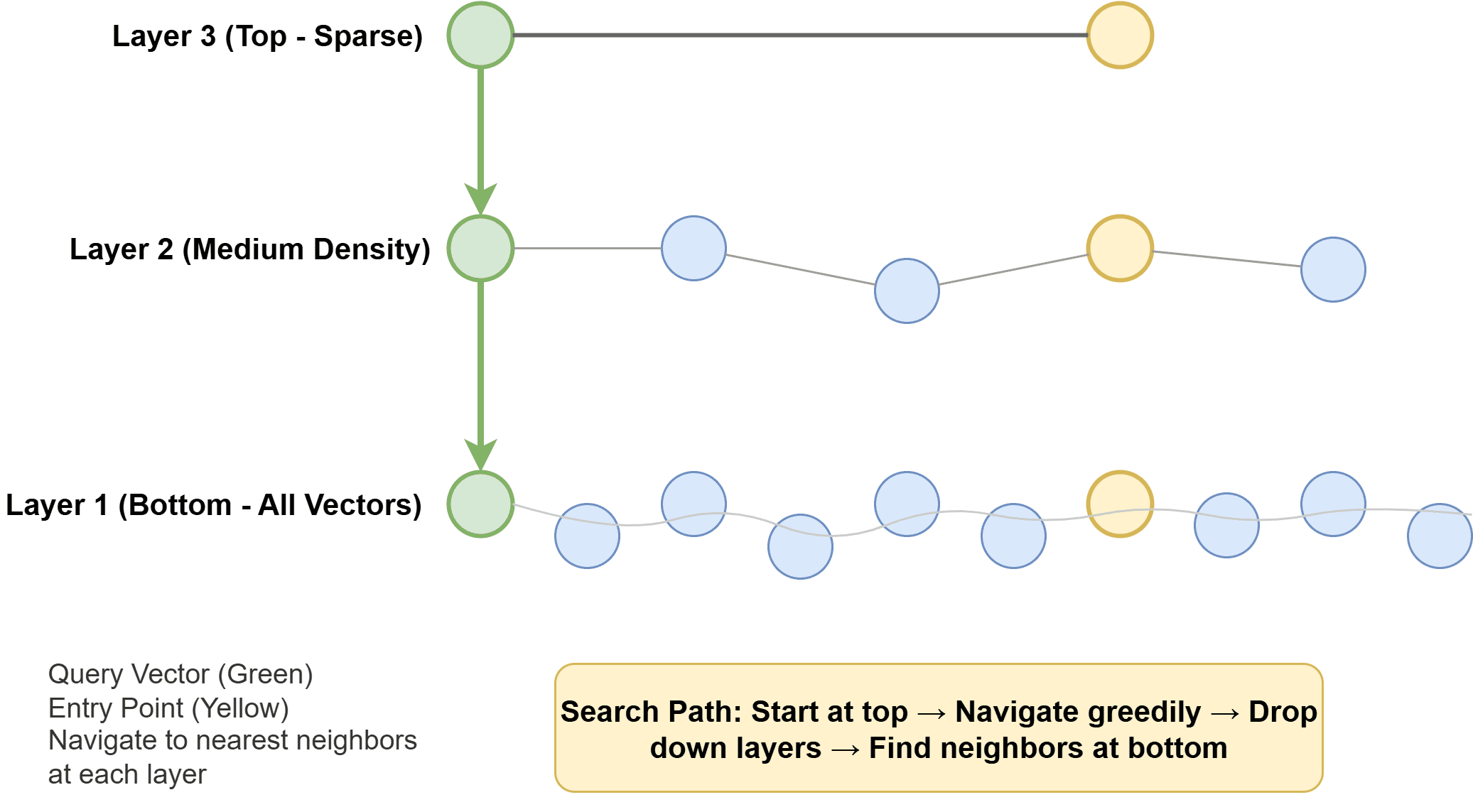
Inverted File Index (IVF): This algorithm operates by first clustering vectors into groups using a technique like k-means. An inverted index is then built, mapping each cluster to its constituent vectors. During a query, instead of searching the entire dataset, the system only identifies and searches the few clusters whose centroids are closest to the query vector. IVF offers better memory efficiency than HNSW and is suitable for very large datasets where memory is a constraint. However, it typically requires an initial "training" step to build the clusters and might be somewhat slower than HNSW for equivalent recall levels.
-
Product Quantization (PQ): PQ is primarily a compression technique often used in conjunction with other ANN algorithms, most notably IVF (forming IVF-PQ). It works by dividing high-dimensional vectors into several subvectors and then quantizing each subvector independently to a small codebook. This process can dramatically reduce the memory footprint of vectors, often by a factor of 4 to 32, enabling the indexing of billions of vectors within practical memory limits. While PQ significantly reduces memory usage, it introduces quantization errors, which can slightly impact recall accuracy. Libraries like Faiss (Facebook AI Similarity Search) extensively leverage PQ for large-scale similarity search.
These algorithms are under continuous development, with researchers constantly seeking new ways to optimize the trade-offs between speed, memory, and accuracy.
Enhancing Search: Hybrid Retrieval and Metadata Filtering
Pure semantic search, while powerful, often needs to be combined with traditional filtering capabilities to meet real-world application requirements.
-
Metadata Filtering: In practical scenarios, users rarely want any similar item; they want similar items that also meet specific criteria. For example, "find similar documents authored by this user and created after a certain date." Vector databases address this through metadata filtering. Implementations vary, but generally fall into two categories:
- Pre-filtering: The attribute filter is applied before the ANN search, narrowing down the dataset to a relevant subset. This is often more accurate as the ANN search operates on precisely the intended data, but it can be computationally expensive for highly selective queries or when the filtered subset is still large.
- Post-filtering: The ANN search is performed first on the entire index, and then the attribute filter is applied to the results. This can be faster if the ANN search is very efficient, but it risks filtering out potentially relevant items if the initial ANN results do not contain enough items matching the metadata criteria. Most production systems employ sophisticated variants of pre-filtering, leveraging smart indexing for metadata to maintain speed.
-
Hybrid Search (Dense + Sparse): While dense vector embeddings excel at capturing semantic meaning, they can sometimes miss exact keyword matches. A query like "GPT-5 release date" might semantically drift towards general AI topics if the specific phrase "GPT-5" is rare in the embedding space. To overcome this, hybrid search combines the strengths of dense vector search (semantic understanding) with sparse retrieval methods (keyword precision). Sparse methods, such as BM25 (Best Match 25) or TF-IDF (Term Frequency-Inverse Document Frequency), are traditional information retrieval techniques that identify documents based on keyword frequency and rarity.
The standard approach for hybrid search involves running both dense (ANN) and sparse searches in parallel. The results from both systems are then combined using algorithms like Reciprocal Rank Fusion (RRF). RRF is a rank-based merging algorithm that aggregates results from multiple sources without requiring complex score normalization, providing a robust way to blend semantic similarity with keyword relevance. This dual approach ensures that applications can leverage both the nuanced understanding of embeddings and the pinpoint accuracy of keyword matching, a feature now natively supported by most leading vector database systems.
Operationalizing Vector Databases: Index Configuration and Scaling
Deploying and maintaining vector databases at production scale involves careful configuration and architectural decisions.
-
Index Configuration and Tuning: ANN algorithms come with various parameters that must be tuned to balance recall (the proportion of relevant items retrieved) against latency (query response time) and memory usage.
- For HNSW, key parameters include
ef_construction(controlling the number of neighbors considered during index building, affecting index quality and build time) andM(the maximum number of connections per node, influencing memory and search quality). At query time,ef_searchdetermines how many candidates are explored, directly impacting recall and latency; this parameter can often be adjusted dynamically without rebuilding the index. - For IVF,
nlistsets the number of clusters (affecting precision and memory), whilenprobedictates how many clusters are searched at query time (impacting recall and latency). Optimal tuning requires extensive benchmarking against specific datasets and query patterns. A recall@10 of 0.95 might be excellent for a general search engine, while a recommendation system might demand 0.99 for optimal user experience.
- For HNSW, key parameters include
-
Scale and Sharding: A single HNSW index can typically handle tens of millions to around 100 million vectors, depending on vector dimensionality and available RAM. Beyond this threshold, sharding becomes necessary. Sharding involves partitioning the vector space across multiple nodes or machines. Queries are then fanned out to relevant shards, and their results are merged. While sharding enables massive scalability, it introduces coordination overhead and requires careful selection of shard keys to prevent "hot spots"—where certain shards become disproportionately burdened.
-
Storage Backends: The storage strategy for vectors significantly impacts performance and cost.
- In-memory: Storing vectors entirely in RAM provides the fastest ANN search performance. This is ideal for latency-critical applications but can be costly for extremely large datasets.
- Memory-mapped files: Some systems support memory-mapped files, allowing indexes to spill to disk when they exceed available RAM. This offers a balance between latency and scale but introduces some performance overhead for disk accesses.
- On-disk ANN indexes: Solutions like Microsoft’s DiskANN are specifically designed to operate efficiently from Solid State Drives (SSDs) with minimal RAM. These are crucial for very large datasets where the memory footprint is the primary constraint, achieving good recall and throughput even with disk-bound operations.
The Vector Database Ecosystem: Options and Implementations
The growing demand for semantic search has fostered a vibrant ecosystem of vector database solutions, catering to diverse needs and scales. These can broadly be categorized into three groups:
-
Purpose-Built Vector Databases: These are specialized systems engineered from the ground up for efficient vector storage and similarity search, often offering advanced features like hybrid search, metadata filtering, and robust scalability. Examples include:
- Pinecone: A fully managed, cloud-native vector database known for its ease of use and scalability, ideal for organizations preferring a hands-off infrastructure approach.
- Qdrant: An open-source vector search engine offering advanced filtering, geospatial search, and a focus on performance.
- Weaviate: Another open-source, cloud-native vector database that supports GraphQL-like queries and offers integrated data storage for both vectors and metadata.
- Milvus: A widely adopted open-source vector database designed for massive-scale similarity search, supporting various ANN algorithms and distributed deployments.
-
Extensions to Existing Systems: For users already invested in traditional database ecosystems, extensions offer a convenient way to add vector search capabilities without adopting an entirely new system.
- pgvector for Postgres: This extension integrates vector storage and similarity search directly into PostgreSQL. It’s an excellent starting point for small to medium-scale applications, minimizing operational overhead by leveraging existing PostgreSQL infrastructure and expertise.
-
Libraries for Building Custom Solutions: For developers who require maximum control, or who are building specialized research systems, robust libraries provide the underlying ANN algorithms.
- Faiss (Facebook AI Similarity Search): A highly optimized C++ library with Python bindings for efficient similarity search and clustering of dense vectors. It includes implementations of many ANN algorithms, including IVF-PQ.
- Annoy (Approximate Nearest Neighbors Oh Yeah): Developed by Spotify, Annoy is a C++ library with Python bindings that builds forest-of-trees data structures for fast nearest neighbor lookups.
- ScaNN (Scalable Nearest Neighbors): Developed by Google, ScaNN is a highly optimized library for efficient vector similarity search, particularly strong with query-side acceleration techniques.
For new Retrieval-Augmented Generation (RAG) applications or general semantic search needs at moderate scale, pgvector often proves to be a pragmatic initial choice due to its operational simplicity for existing PostgreSQL users. As datasets grow and requirements become more complex, necessitating advanced filtering, higher throughput, or greater scalability, purpose-built solutions like Qdrant or Weaviate become increasingly compelling. For enterprises prioritizing fully managed services and minimal infrastructure burden, Pinecone offers a powerful, scalable solution.
Impact and Future Outlook
Vector databases are not merely a technical novelty; they are a foundational technology powering the next generation of intelligent applications. Their impact is evident across numerous domains:
- AI/ML Development: They are critical for RAG architectures, enabling large language models to access and retrieve factual information from vast, up-to-date knowledge bases, significantly reducing hallucinations.
- Recommendation Systems: By finding items (products, movies, music) similar to a user’s past interactions or current preferences, vector databases drive highly personalized recommendations.
- Image and Video Search: Beyond keyword tags, users can search for visual content based on visual similarity (e.g., "find images similar to this one").
- Fraud Detection: Identifying anomalous patterns by finding vectors that are unusually distant from typical behavior.
- Content Moderation: Automatically detecting and flagging inappropriate content by comparing it to known problematic examples.
The market for vector databases is experiencing rapid growth, fueled by the accelerating adoption of AI and the increasing volume of unstructured data. Industry analysts project continued expansion, with significant investments in research and development to further optimize ANN algorithms, enhance scalability, and integrate advanced features like multimodal embeddings (representing combinations of text, image, and audio in a single vector). Challenges remain, including standardizing data formats, improving the explainability of similarity results, and addressing ethical considerations related to bias in embeddings.
In conclusion, vector databases represent a pivotal advancement in data management, bridging the gap between raw data and semantic understanding. By transforming unstructured content into queryable vectors and employing sophisticated ANN algorithms, they enable organizations to unlock the true potential of their data, driving innovation across AI, personalization, and intelligent information retrieval. As the digital world continues its inexorable expansion, the ability to find "what is close to this" quickly and accurately will only grow in strategic importance.