
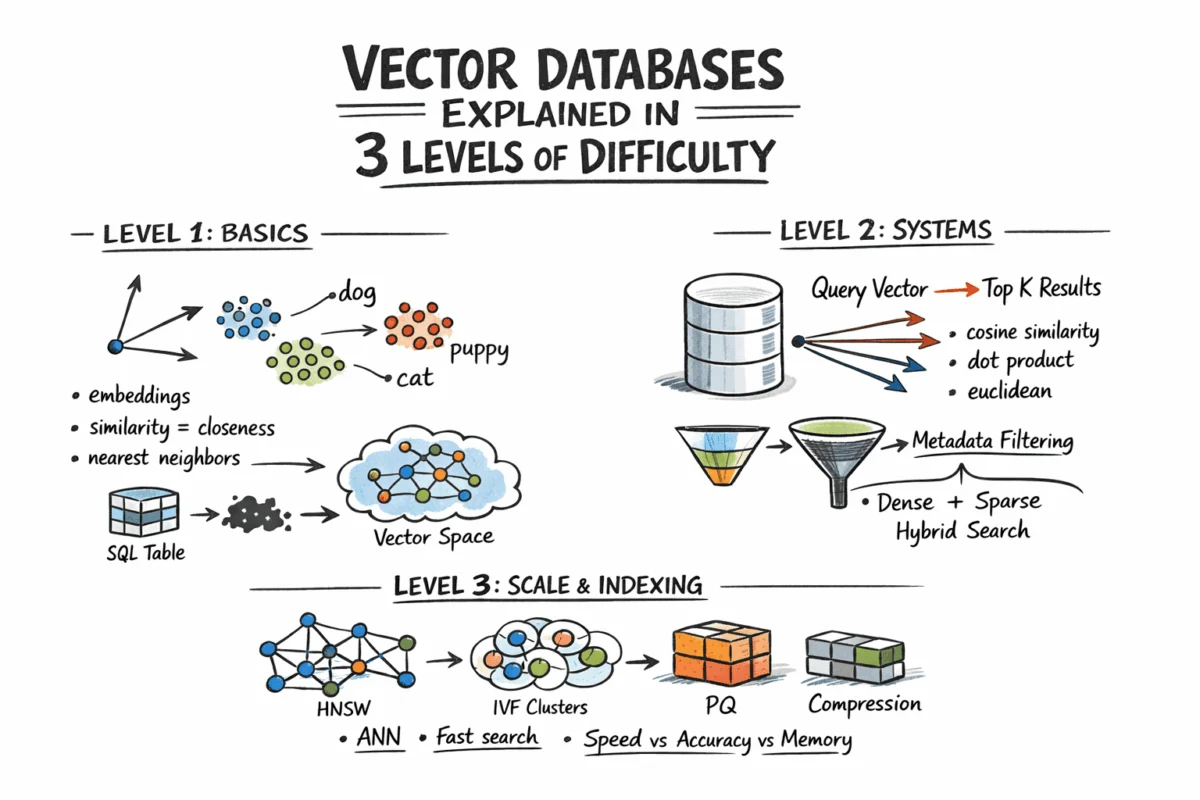
In an era increasingly dominated by artificial intelligence and the explosion of unstructured data, vector databases have emerged as a pivotal technology, fundamentally redefining how information is stored, searched, and retrieved. Unlike traditional relational or NoSQL databases that excel at exact matches or structured queries, vector databases specialize in answering a more nuanced question: "Which records are most similar to this?" This paradigm shift is critical because a vast and growing class of modern data—ranging from text documents and images to audio files and user behavior logs—cannot be effectively queried using precise keyword matches. Instead, these systems leverage the power of semantic similarity, enabling applications to understand context and meaning rather than just keywords.
The Paradigm Shift: Beyond Exact Matches
Historically, databases have been designed to manage structured data, neatly organized into rows, columns, integers, and strings, with SQL providing a fast and precise language for retrieval. However, the advent of sophisticated AI models, particularly large language models (LLMs) and advanced computer vision systems, has led to an unprecedented volume of unstructured data. This data, inherently complex and lacking a rigid schema, presents significant challenges for traditional indexing and search methodologies. Searching for "find this" is often inadequate when dealing with the nuances of human language or visual content; the more pertinent query becomes "find what is close to this."
This fundamental need gave rise to vector embeddings. Embedding models, which are deep neural networks, transform raw, complex content—be it a paragraph of text, a spoken phrase, or an image—into a fixed-length array of floating-point numbers, known as a vector. Critically, these vectors are designed such that items with similar semantic meaning or content are positioned geometrically close to each other in a high-dimensional vector space. For instance, the embedding for "dog" would be near "puppy," and a vector representing a photograph of a cat would reside close to one depicting a cartoon drawing of a cat. This geometric proximity allows computers to grasp abstract relationships and context, a capability previously beyond the reach of standard database systems.
The Foundation: Embeddings and Geometric Similarity
Before any vector database can function, the raw data must undergo this crucial transformation into embeddings. These neural networks, often pre-trained on massive datasets, map diverse inputs into a dense vector space, typically ranging from 256 to over 4096 dimensions depending on the specific model used (e.g., OpenAI’s text-embedding-3-small for text, or specialized vision models for images). The individual numerical values within a vector do not hold direct, human-interpretable meaning; their significance lies entirely in their collective geometric relationship to other vectors. This principle—close vectors mean similar content—forms the bedrock of semantic search. Developers interact with embedding APIs or run models locally, receiving these numerical arrays, which are then stored alongside any relevant metadata for the original content.
Measuring Closeness: Distance Metrics
The concept of "similarity" in vector space is quantified through geometric distance. The choice of distance metric is paramount and must align with how the embedding model was originally trained, as using an inappropriate metric can significantly degrade the quality and relevance of search results. Three common metrics dominate the field:
- Cosine Similarity: Measures the cosine of the angle between two vectors. It is insensitive to vector magnitude and is particularly effective for text embeddings where the direction of the vector (semantic orientation) is more important than its length.
- Euclidean Distance: The straight-line distance between two points in Euclidean space. It is a common choice for various data types but can be influenced by vector magnitude.
- Dot Product: A measure of the projection of one vector onto another. When vectors are normalized (unit length), dot product is equivalent to cosine similarity. For unnormalized vectors, it incorporates both direction and magnitude.
The Scale Challenge: Why Brute Force Fails
While finding exact nearest neighbors is trivial for small datasets—simply computing the distance from a query vector to every stored vector, sorting, and returning the top K results—this "brute-force" or "flat search" approach becomes computationally prohibitive at scale. For a dataset of, say, 10 million vectors, each with 1536 dimensions, performing billions of floating-point operations per query makes real-time search impractical in production environments.
This is where Approximate Nearest Neighbor (ANN) algorithms become indispensable. ANN algorithms trade a minuscule amount of accuracy for exponential gains in speed, enabling near real-time retrieval even with massive datasets. Production-grade vector databases rely heavily on these sophisticated algorithms to efficiently prune the search space, skipping the vast majority of candidates while still returning results that are remarkably close to those an exhaustive search would yield, but at a fraction of the computational cost.
Advanced Retrieval Strategies
Modern applications rarely require pure semantic similarity in isolation. Practical use cases often demand a combination of semantic understanding and precise filtering.
-
Metadata Filtering: In many scenarios, users need to refine their search results based on traditional attributes. For instance, "find the most similar documents that belong to this specific user and were created after this date." This "hybrid retrieval" combines vector similarity with attribute-based filtering. Implementations vary, but most production databases employ some form of pre-filtering, where attribute filters are applied first to narrow down the candidate set, followed by ANN search on the reduced subset. This approach, while potentially more expensive for highly selective queries, generally yields more accurate and relevant results.
-
Hybrid Search: Blending Dense and Sparse Retrieval: Pure dense vector search, while powerful for semantic understanding, can sometimes overlook exact keyword matches. A query like "GPT-5 release date" might semantically drift towards general AI topics if the exact phrase "GPT-5" is not strongly embedded, potentially missing the specific document containing that information. Hybrid search addresses this by combining the strengths of dense vector search (semantic understanding) with sparse retrieval methods (like BM25 or TF-IDF, which excel at keyword matching). The standard approach involves running both dense and sparse searches in parallel and then merging their results using techniques like Reciprocal Rank Fusion (RRF). RRF is a rank-based merging algorithm that avoids the complexities of normalizing scores from disparate retrieval methods, effectively leveraging both semantic context and keyword precision. The integration of native hybrid search capabilities is now a common feature in most leading vector database systems.
Under the Hood: Key ANN Algorithms for Production Scale
The efficacy of vector databases at scale hinges on their underlying ANN algorithms, each offering distinct tradeoffs between speed, memory consumption, and recall (the proportion of relevant items found).
-
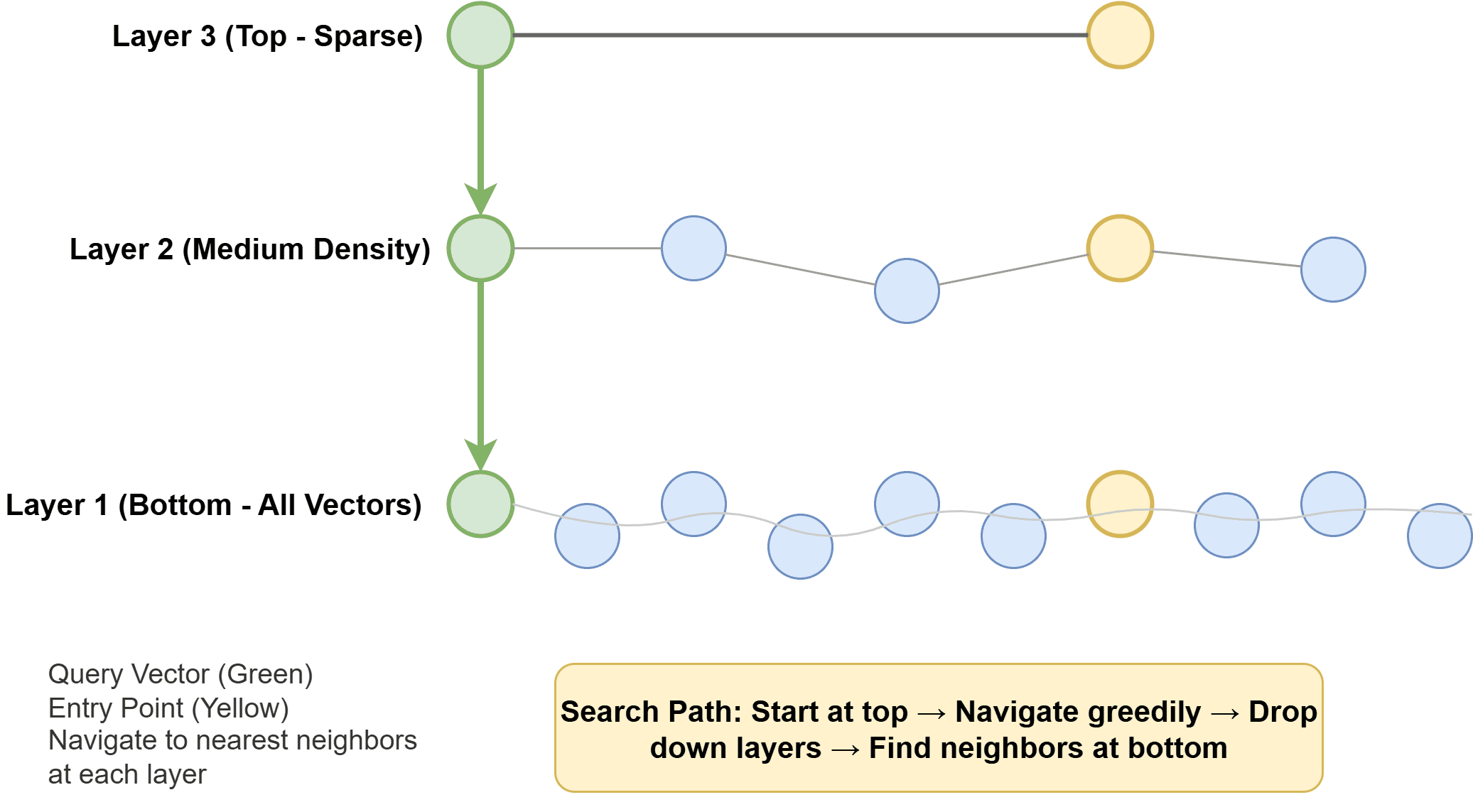
Hierarchical Navigable Small World (HNSW): Widely adopted and often the default in modern systems, HNSW constructs a multi-layer graph. Each vector is represented as a node, connected to its similar neighbors via edges. Higher layers are sparse, facilitating rapid long-range traversal across the vector space, while lower layers are denser, enabling precise local searches. During a query, the algorithm efficiently navigates this graph, progressively homing in on the nearest neighbors. HNSW is renowned for its speed and excellent recall but can be memory-intensive. The image "How Hierarchical Navigable Small World Works" visually depicts this multi-layered graph structure.
-
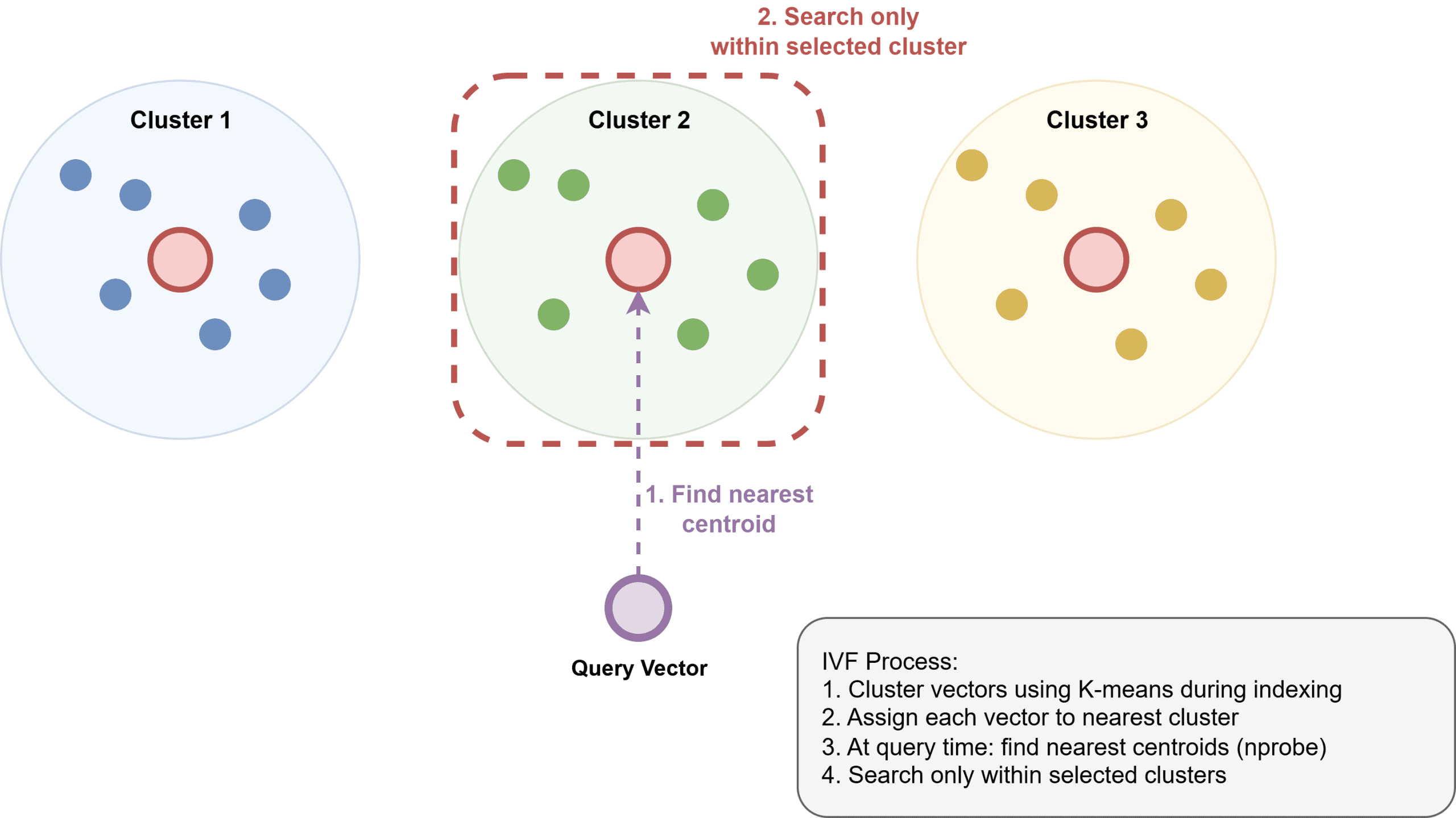
Inverted File Index (IVF): IVF operates by clustering vectors into groups, typically using algorithms like k-means. An inverted index is then built, mapping each cluster to its constituent vectors. At query time, the system only searches the clusters deemed closest to the query vector, significantly reducing the search space. IVF generally uses less memory than HNSW but might be somewhat slower and requires an initial training step to build the clusters. The image "How Inverted File Index Works" illustrates the clustering and inverted indexing process.
-
Product Quantization (PQ): This algorithm is primarily a compression technique designed to manage extremely large datasets. PQ works by dividing high-dimensional vectors into smaller subvectors and then quantizing each subvector to a codebook. This process can achieve substantial memory reductions (e.g., 4-32x), making billion-scale datasets manageable. PQ is frequently employed in conjunction with IVF, forming the IVF-PQ index, a powerful combination seen in libraries like Faiss. The image "How Product Quantization Works" provides a conceptual view of vector compression through subvector division.
Optimizing Performance: Index Configuration and Tradeoffs
Tuning ANN algorithms is crucial for balancing performance goals. For HNSW, key parameters include ef_construction (controlling graph density during index build) and M (the maximum number of neighbors for each node). These are tuned against recall, latency, and memory budgets. At query time, ef_search dictates how many candidates are explored; increasing it improves recall but at the cost of higher latency, and it can be adjusted without rebuilding the index. For IVF, nlist defines the number of clusters, and nprobe specifies how many clusters to search during a query. More clusters can improve precision and distribute data more finely but demand more memory, while a higher nprobe boosts recall but increases latency. Understanding these parameters is vital for achieving target recall at optimal query speeds.
The underlying reality of ANN is a fundamental tradeoff surface: higher recall (finding more relevant items) can always be achieved by exploring more of the index, but this comes at the expense of increased latency and computational resources. Therefore, rigorous benchmarking with specific datasets and query patterns is indispensable. A recall@10 of 0.95 might be perfectly acceptable for a general search application, while a recommendation system might demand a stricter 0.99.
Architectural Considerations for Enterprise Deployment
Scaling vector search beyond a single machine’s capacity introduces architectural complexities. A single HNSW index, depending on dimensionality and available RAM, can typically accommodate 50-100 million vectors. Beyond this, sharding becomes necessary: partitioning the vector space across multiple nodes. Queries are then fanned out to relevant shards, and results are merged. This distributed architecture introduces coordination overhead and necessitates careful shard-key selection to prevent "hot spots" – individual shards becoming bottlenecks due to uneven data distribution or query load.
Regarding storage backends, vectors are often kept in RAM for the fastest ANN search. Metadata associated with these vectors is usually stored separately in a key-value or columnar store. Some systems support memory-mapped files, allowing them to index datasets larger than available RAM by spilling data to disk as needed, trading some latency for increased scale. For truly massive datasets where memory is the primary constraint, on-disk ANN indexes like Microsoft’s DiskANN are designed to operate efficiently directly from SSDs, delivering robust recall and throughput with minimal RAM requirements.
The Expanding Ecosystem of Vector Database Solutions
The landscape of vector search tools is rapidly maturing, offering solutions across a spectrum of needs and scales. These generally fall into three categories:
-
Purpose-Built Vector Databases: These are specialized systems engineered from the ground up for efficient vector storage and search. Prominent examples include Pinecone (a fully managed service, eliminating infrastructure overhead), Qdrant and Weaviate (open-source, offering advanced filtering and hybrid search capabilities), Milvus (another robust open-source option), and Vespa (a mature, feature-rich platform). These solutions are ideal for large-scale, high-performance applications with complex requirements.
-
Extensions to Existing Systems: For smaller to medium-scale applications or those already embedded in specific technology stacks, extensions offer a pragmatic approach.
pgvectorfor PostgreSQL is a prime example, enabling vector search within an existing relational database. This minimizes operational overhead for organizations already using Postgres and is often a good starting point for retrieval-augmented generation (RAG) applications at moderate scale. -
Libraries: For developers who prefer a more granular control or are building highly customized solutions, libraries like Faiss (Facebook AI Similarity Search), Annoy (Approximate Nearest Neighbors Oh Yeah), and NMSLIB (Non-Metric Space Library) provide core ANN algorithms. These libraries offer maximum flexibility but require significant engineering effort for deployment, scaling, and maintenance.
The choice of solution depends heavily on factors like data scale, complexity of filtering, required latency, and operational resources. For instance, while pgvector is excellent for initial RAG applications, the demands of larger datasets or more sophisticated filtering often make dedicated solutions like Qdrant or Weaviate more compelling. For those seeking minimal infrastructure management, fully managed services like Pinecone present an attractive option.
Implications and Future Outlook
Vector databases are not merely a technical novelty; they represent a fundamental shift in how organizations interact with information, particularly in the context of AI. They are instrumental in enabling advanced applications such as:
- Retrieval-Augmented Generation (RAG): Powering LLMs with up-to-date, domain-specific information, mitigating hallucinations, and enhancing answer relevance.
- Recommendation Systems: Delivering highly personalized product suggestions, content recommendations, and user experiences across e-commerce, media, and other sectors.
- Fraud Detection: Identifying anomalous patterns in financial transactions or network activity by finding vectors that are semantically distant from typical behavior.
- Semantic Search Engines: Moving beyond keyword matching to context-aware search in enterprise knowledge bases, customer support systems, and public web search.
- Drug Discovery and Genomics: Accelerating research by finding similar molecular structures or genetic sequences.
Industry analysts project significant growth in the vector database market, driven by the increasing adoption of AI and the proliferation of unstructured data. However, challenges remain, including the need for better data governance for embeddings, robust support for multi-modal data (combining text, image, audio vectors), continued optimization for cost-efficiency at extreme scales, and the development of industry-wide standards for vector database interoperability.
In conclusion, vector databases address a critical problem: efficiently finding semantically similar information at scale. The core concept—embedding content as vectors and searching by geometric distance—is elegantly simple, yet its implementation involves sophisticated algorithms and architectural decisions. From HNSW and IVF to advanced hybrid search and sharding strategies, these technologies are empowering a new generation of intelligent applications, fundamentally transforming how we retrieve and understand information in the age of AI. As the volume and complexity of data continue to expand, vector databases will remain at the forefront, unlocking deeper insights and driving innovation across virtually every industry.