
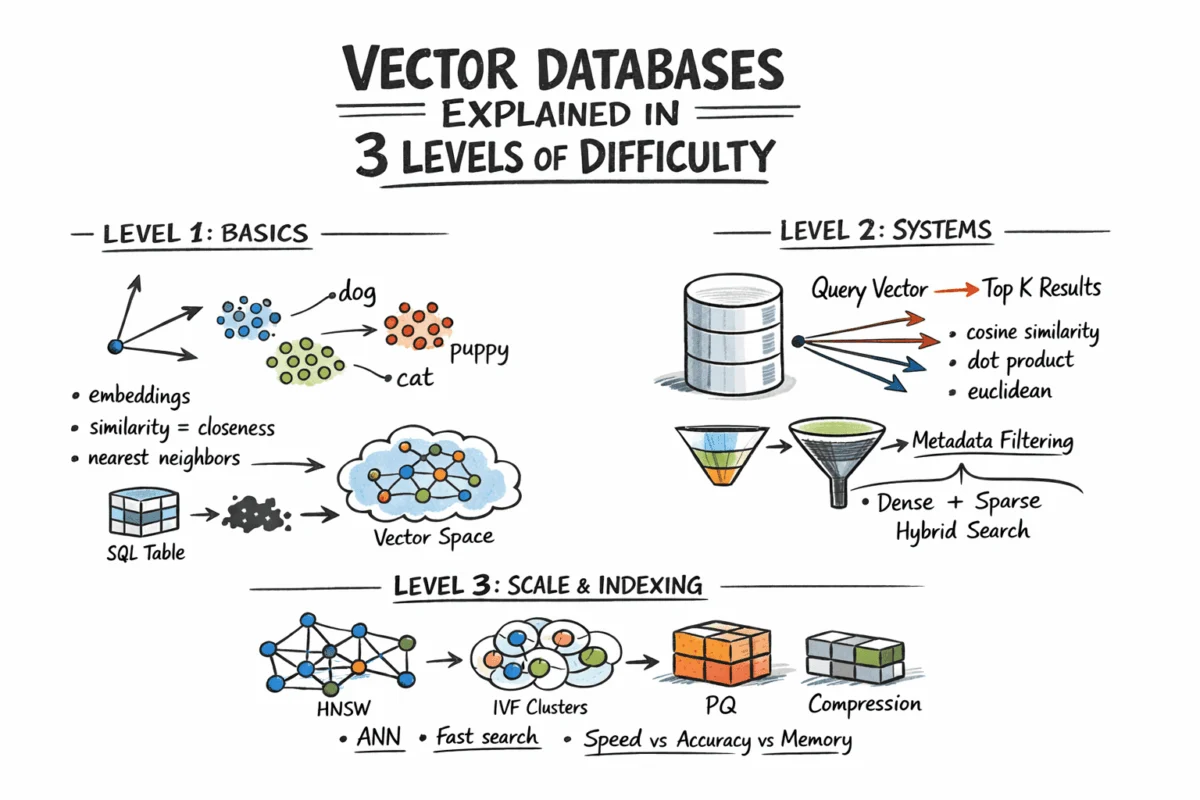
The Rise of Semantic Search: A New Data Frontier
Traditional databases operate on a clear premise: does a record matching predefined criteria exist? This question is elegantly handled by SQL and similar query languages, which efficiently retrieve structured data—rows, columns, integers, and strings—through exact lookups or range queries. However, the contemporary digital landscape is dominated by unstructured data: billions of text documents, images, audio files, and complex user behavior logs. This data defies simple categorization into fixed columns, and for such content, an "exact match" query is often irrelevant. The true challenge lies in finding "what is close to this," or semantically similar items.
This demand for semantic understanding escalated dramatically with the proliferation of deep learning models, particularly embedding models. These models, such as OpenAI’s text-embedding-3-small or advanced vision models, convert raw content—be it a sentence, an image, or a sound clip—into fixed-length numerical representations called vectors. In this multi-dimensional vector space, geometric proximity directly correlates with semantic similarity. For instance, the word "dog" and "puppy" would occupy closely located points, as would a photograph of a cat and a stylized drawing of one. The ability to represent complex concepts as quantifiable vectors laid the groundwork for a new generation of search capabilities.
Decoding the Core Mechanics: Embeddings and Distance Metrics
At its heart, a vector database stores these high-dimensional embeddings and facilitates similarity search. This process, known as nearest neighbor search, aims to identify the K vectors closest to a given query vector. Before any search can occur, raw content must undergo an embedding process. Neural networks, specifically trained embedding models, map diverse inputs into a dense vector space, typically ranging from 256 to over 4096 dimensions depending on the model’s complexity and the data type. The individual numerical values within a vector do not carry direct human-interpretable meaning; their collective arrangement and relative positions within the vector space are what convey semantic information. Developers interact with these models via APIs or by running them locally, receiving an array of floating-point numbers that are then stored alongside the original content’s metadata.
The notion of "similarity" in this context is mathematically quantified as geometric distance between vectors. Three primary distance metrics are commonly employed:
- Euclidean Distance (L2): Measures the straight-line distance between two points in Euclidean space. It’s often used when the magnitude of the vector is important.
- Cosine Similarity: Measures the cosine of the angle between two vectors. It’s preferred when the orientation of the vectors, rather than their magnitude, determines similarity, making it robust to differences in vector length.
- Dot Product: A simple scalar product of two vectors, often used in conjunction with normalization. For normalized vectors, it’s equivalent to cosine similarity.
The selection of an appropriate distance metric is crucial and must align with how the embedding model was trained. Mismatching the metric can significantly degrade the quality and relevance of search results.
Overcoming the Scale Challenge: Approximate Nearest Neighbor (ANN)
While finding exact nearest neighbors is straightforward for small datasets—involving a brute-force computation of distances from the query vector to every stored vector, followed by sorting—this approach quickly becomes impractical at production scale. Comparing a query vector against, for example, 100 million stored vectors, each with 1536 dimensions, would necessitate billions of floating-point operations. Such computational demands render real-time search unfeasible.
This is where Approximate Nearest Neighbor (ANN) algorithms become indispensable. ANN algorithms intelligently trade a minuscule amount of accuracy for substantial gains in speed and efficiency. Instead of exhaustively checking every vector, ANN techniques employ various strategies to quickly narrow down the search space, typically returning results that are nearly identical to an exhaustive search but at a mere fraction of the computational cost. These algorithms are the underlying engines of production vector databases, enabling the rapid retrieval critical for interactive applications.
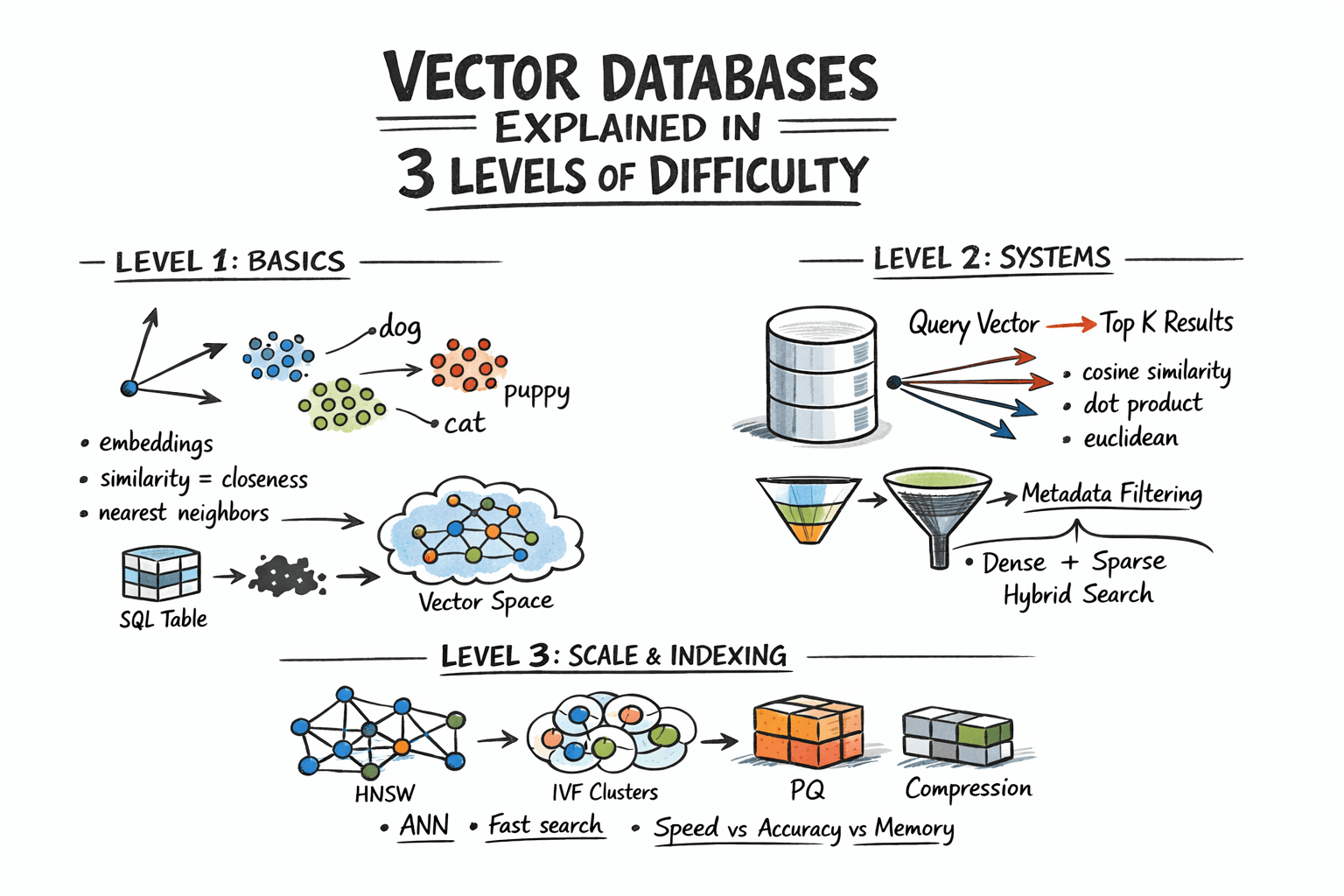
Sophisticated Querying: Beyond Pure Similarity
In real-world applications, pure semantic similarity often needs refinement. Users rarely want simply "the most similar items globally"; rather, they seek "the most similar documents that belong to a specific user and were created after a certain date." This necessitates hybrid retrieval, combining vector similarity with traditional attribute filters.
Implementations of hybrid retrieval vary:
- Pre-filtering: The attribute filter is applied first, narrowing down the dataset, and then ANN search is performed on the remaining subset. This method offers high accuracy but can be computationally intensive for highly selective queries that result in very small subsets.
- Post-filtering: ANN search is performed on the entire dataset first, and then the attribute filter is applied to the retrieved results. While faster initially, this can lead to suboptimal recall if many relevant items are filtered out after the ANN step.
Most production vector databases utilize sophisticated variants of pre-filtering, often coupled with smart indexing for metadata, to balance speed and accuracy.
Furthermore, pure dense vector search, while excellent for semantic understanding, can sometimes overlook keyword-level precision. A query like "GPT-5 release date" might semantically drift towards general AI topics if only dense vectors are used, potentially missing the exact document containing that specific phrase. Hybrid search addresses this by combining dense ANN with sparse retrieval methods like BM25 or TF-IDF. Sparse retrieval excels at keyword matching, while dense vectors capture semantic meaning. The standard approach involves running both dense and sparse searches in parallel, then merging their results using Reciprocal Rank Fusion (RRF). RRF is a rank-based merging algorithm that combines ranked lists without requiring complex score normalization, providing a robust solution for achieving both semantic understanding and keyword precision. Many modern vector database systems now support hybrid search natively.
Architectural Foundations: Indexing for High Performance
The efficiency of vector databases hinges on their underlying ANN algorithms, which represent different trade-offs in speed, memory footprint, and recall (the proportion of relevant items retrieved).
-
Hierarchical Navigable Small World (HNSW): This algorithm constructs a multi-layer graph where each vector is a node, and edges connect similar neighbors. Higher layers are sparse, facilitating rapid long-range traversal, while lower layers are denser, enabling precise local searches. During a query, the algorithm navigates this graph, iteratively moving towards the nearest neighbors. HNSW is renowned for its speed and excellent recall, though it can be memory-intensive. Its robust performance makes it a default choice in many leading vector database systems.
-
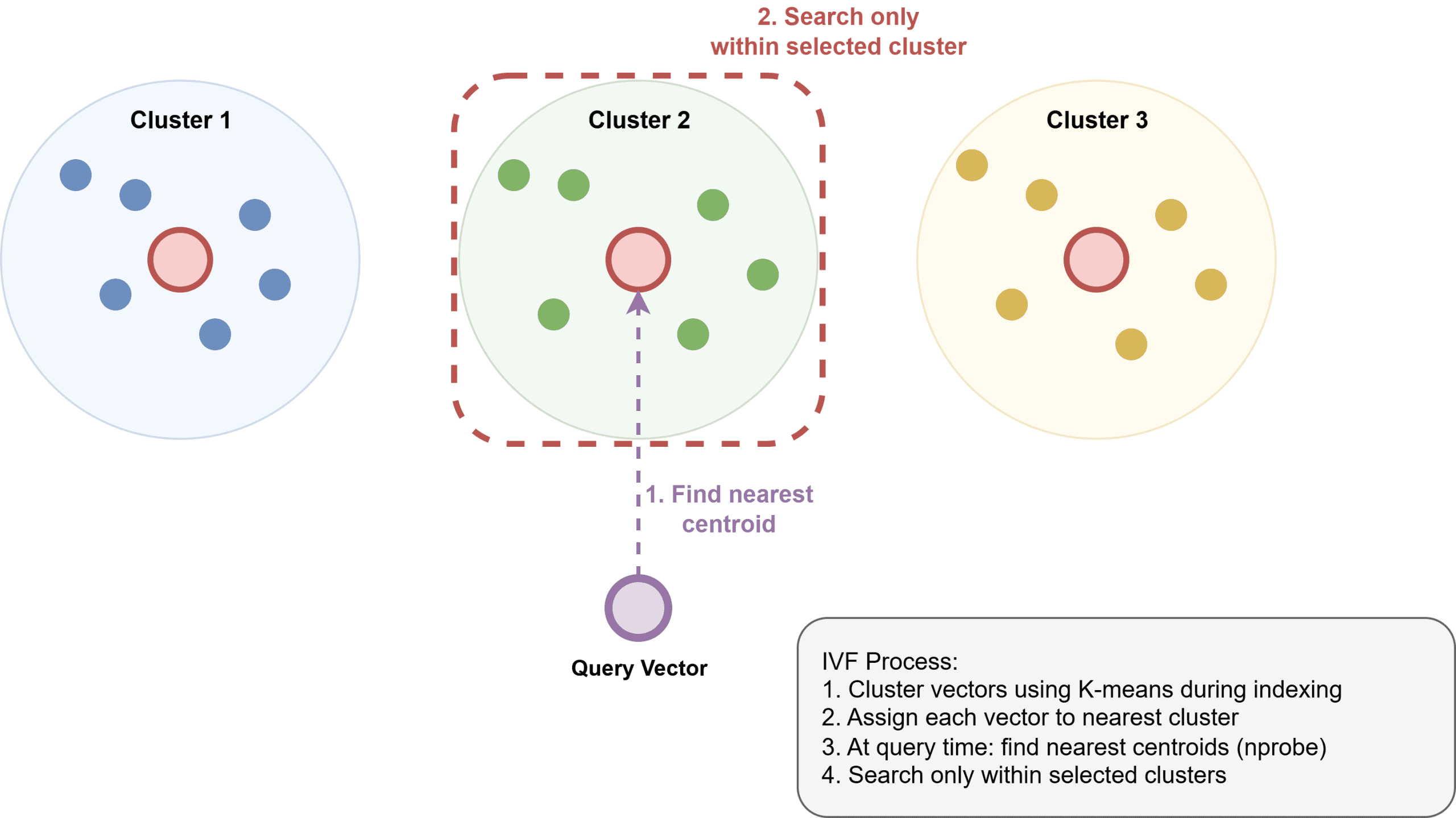
Inverted File Index (IVF): IVF operates by first clustering vectors into groups using an algorithm like k-means. An inverted index is then built, mapping each cluster to its constituent members. At query time, the system identifies the nearest clusters to the query vector and only searches within those clusters. IVF typically uses less memory than HNSW but can be somewhat slower and requires an initial training step to build the clusters effectively.
-
Product Quantization (PQ): PQ is primarily a compression technique. It divides vectors into subvectors and then quantizes each subvector to a codebook. This method can dramatically reduce memory usage, often by a factor of 4x to 32x, making it feasible to manage billion-scale datasets. PQ is frequently combined with other indexing methods, such as IVF, to form hybrid approaches like IVF-PQ, notably utilized in libraries like Faiss.
Optimizing for Production: Configuration and Performance Tuning
The practical deployment of vector databases involves careful configuration and tuning of these ANN algorithms. For HNSW, two critical parameters are:
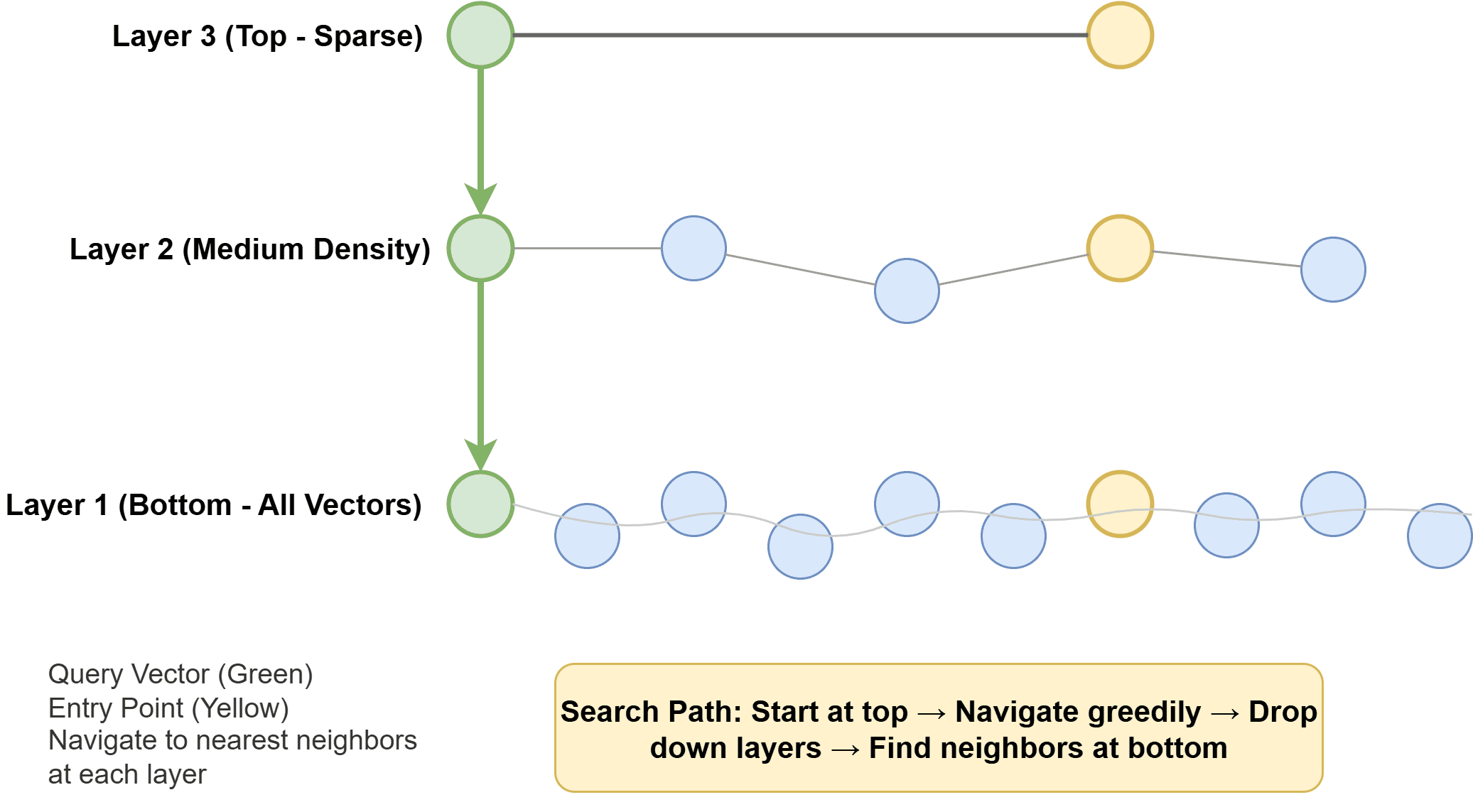
ef_construction: Controls the number of neighbors considered during index construction. Higher values lead to a more accurate, denser graph and better recall but increase index build time and memory usage.M: Defines the maximum number of connections an element can have in the graph. HigherMvalues also improve recall but at the cost of increased memory.
These parameters are typically tuned based on specific application requirements for recall, latency, and memory budget. At query time, ef_search determines how many candidates are explored. Increasing ef_search enhances recall but lengthens query latency. This is a runtime parameter, allowing for dynamic tuning without requiring index rebuilding.
For IVF, nlist sets the number of clusters, while nprobe dictates how many clusters are searched at query time. A higher nlist can improve precision but demands more memory. Similarly, increasing nprobe boosts recall but adds to latency. Achieving a target recall at the fastest possible query speed involves a delicate balance of these parameters, often determined through empirical testing on representative datasets.
ANN inherently operates on a tradeoff surface: higher recall invariably comes at the cost of increased search latency and computational resources. Therefore, rigorous benchmarking against specific datasets and query patterns is essential. A recall@10 of 0.95 might be perfectly acceptable for a general search application, while a sophisticated recommendation system might demand 0.99 for optimal user experience.
Scaling Data: Sharding and Storage Strategies
Handling truly massive datasets in vector databases often necessitates advanced scaling techniques. A single HNSW index can typically reside in memory on a single machine, supporting up to approximately 50-100 million vectors, depending on their dimensionality and available RAM. Beyond this threshold, sharding becomes necessary. This involves partitioning the vector space across multiple nodes, distributing the computational load. Queries are then fanned out to relevant shards, and the results are merged. While effective, sharding introduces coordination overhead and requires careful selection of shard keys to prevent "hot spots" where certain nodes become overloaded.
Regarding storage, vectors are frequently held in RAM to facilitate rapid ANN search. Associated metadata, however, is usually stored separately in a key-value store or a columnar database. Some advanced systems support memory-mapped files, allowing them to index datasets larger than available RAM by spilling data to disk as needed. This strategy trades a degree of latency for the ability to manage larger datasets. Furthermore, specialized on-disk ANN indexes, such as Microsoft’s DiskANN, are engineered to operate efficiently directly from SSDs with minimal RAM usage, achieving high recall and throughput for colossal datasets where memory constitutes the primary bottleneck.
The Landscape of Vector Database Solutions
The ecosystem of vector search tools is diversifying, generally categorizing into three main types:
-
Purpose-built Vector Databases: These are standalone systems designed from the ground up for vector search. Examples include:
- Pinecone: A fully managed, cloud-native vector database offering high performance and scalability.
- Weaviate: An open-source, cloud-native vector database with a strong focus on GraphQL APIs and semantic search.
- Qdrant: An open-source vector similarity search engine, written in Rust, known for its speed and advanced filtering capabilities.
- Milvus: An open-source vector database designed for massive-scale similarity search, supporting various indexing algorithms.
-
Extensions to Existing Systems: For organizations already invested in traditional databases, extensions offer an entry point into vector search. A prominent example is pgvector for Postgres, which integrates vector storage and similarity search directly into the PostgreSQL database. This is often a suitable choice for small to medium-scale applications, minimizing operational overhead.
-
Libraries: These provide the core ANN algorithms as software libraries that can be integrated into custom applications. Key examples include:
- Faiss (Facebook AI Similarity Search): A highly optimized library for efficient similarity search and clustering of dense vectors.
- ScaNN (Scalable Nearest Neighbors): Developed by Google, optimized for high-dimensional vector search at scale.
- Annoy (Approximate Nearest Neighbors Oh Yeah): Developed by Spotify, a C++ library with Python bindings for approximate nearest neighbors in high dimensions.
For new Retrieval-Augmented Generation (RAG) applications at moderate scale, pgvector often serves as an excellent starting point due to its familiarity and minimal operational burden for existing Postgres users. As data volumes grow or filtering requirements become more complex, purpose-built solutions like Qdrant or Weaviate offer more compelling features and performance. For enterprises prioritizing ease of management and extreme scalability without infrastructure concerns, fully managed platforms like Pinecone present an ideal solution.
Implications for the Future of AI and Data Retrieval
Vector databases are more than just a niche technology; they represent a fundamental shift in how information is organized, queried, and understood in the age of AI. Industry analysts project significant growth in the vector database market, driven by the expanding adoption of large language models, personalized recommendation engines, and sophisticated search applications across various sectors, from e-commerce to scientific research.
Their ability to rapidly identify semantically related content unlocks unprecedented capabilities:
- Enhanced Search: Moving beyond keywords to intent-based search, delivering more relevant results.
- Personalized Experiences: Powering recommendation systems that understand user preferences at a deeper level.
- Generative AI Applications: Serving as the memory layer for RAG systems, enabling LLMs to access and synthesize up-to-date, domain-specific information, mitigating hallucinations.
- Anomaly Detection: Identifying unusual patterns in complex data streams by detecting outlier vectors.
The continuous innovation in ANN algorithms, coupled with advancements in hardware and distributed systems, will further push the boundaries of what’s possible, making billion-scale vector search a standard feature rather than an exception.
In conclusion, vector databases address a critical modern problem: enabling fast, scalable semantic similarity search. While the core concept of embedding content as vectors and searching by distance is intuitive, the sophisticated implementation details—ranging from the choice of HNSW versus IVF, to fine-tuning recall, implementing hybrid search, and managing sharding—are paramount for achieving production-grade performance. As AI continues to permeate every facet of technology, vector databases will remain an indispensable component, empowering intelligent systems to navigate and make sense of the ever-growing ocean of unstructured data.