
The industry has largely converged on Retrieval Augmented Generation (RAG) as a foundational technique to extend LLM capabilities beyond their initial training data and limited context windows. RAG systems enable LLMs to retrieve relevant information from external knowledge bases before generating a response, thereby improving factual accuracy and reducing "hallucinations." Within this paradigm, the choice of memory architecture—how that external knowledge is stored and retrieved—becomes paramount. Two primary contenders have emerged: vector databases, which leverage semantic similarity, and Graph RAG, an approach that integrates knowledge graphs for structured, relational memory. Understanding the nuanced differences and optimal applications of each is crucial for developers designing the next generation of intelligent systems.
The Imperative for Long-Term AI Memory
The initial wave of generative AI, spearheaded by powerful LLMs, demonstrated remarkable capabilities in language understanding and generation. However, these models inherently operate with a limited "context window," meaning they can only process and retain information from a relatively small segment of recent interactions or input text. For an AI agent tasked with ongoing projects, continuous learning, or complex decision-making processes, this short-term memory is insufficient. Imagine a human assistant who forgets every detail discussed in a meeting five minutes prior, or a software engineer unable to recall previously written code. Such limitations render AI agents ineffective for persistent, adaptive roles.
Long-term memory in AI agents addresses this by providing a mechanism to store and retrieve vast amounts of information, enabling continuity, personalization, and deeper reasoning. This includes conversational history, user preferences, domain-specific knowledge, project details, and complex interdependencies. The challenge lies not just in storage, but in efficient and accurate retrieval of the most relevant information at precisely the right moment, without overwhelming the agent’s active context window with extraneous data. This is where memory architectures like vector databases and Graph RAG play a pivotal role in augmenting the capabilities of AI agents, moving them closer to truly autonomous and intelligent systems.
Vector Databases: The Foundation of Semantic Retrieval
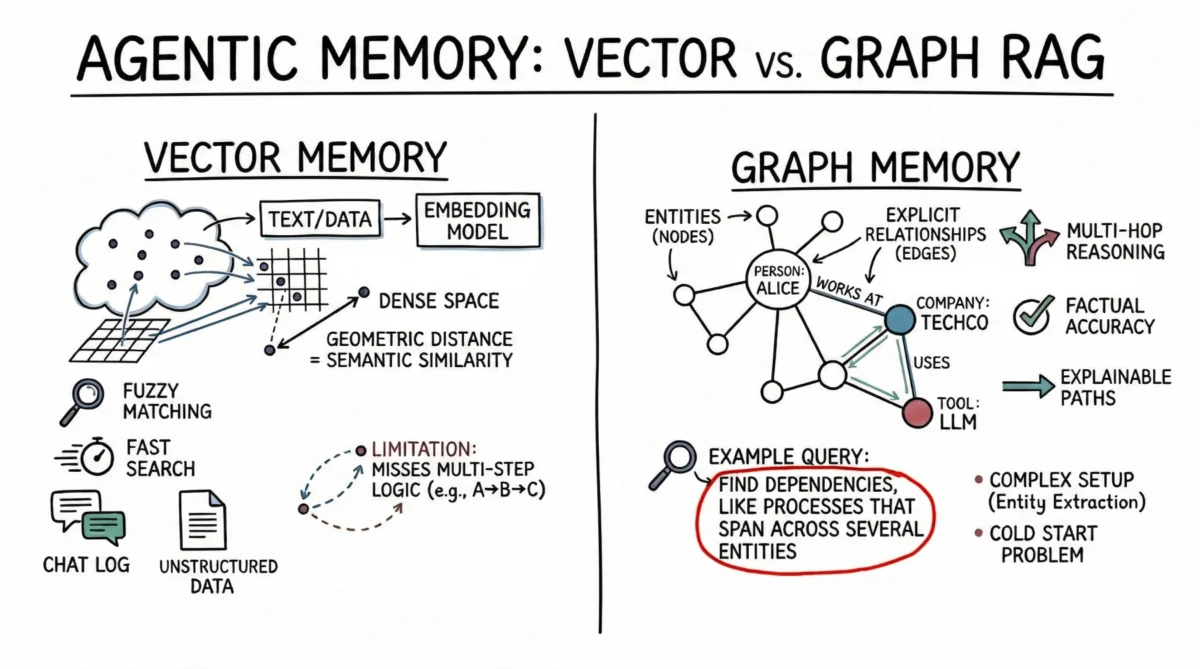
Vector databases have rapidly become the de facto standard for implementing RAG, primarily due to their efficiency in handling unstructured data and performing semantic search. At their core, vector databases represent information—whether text, images, or audio—as dense mathematical vectors, or "embeddings," in a high-dimensional space. An embedding model, often a neural network, transforms raw data into these numerical representations such that semantically similar items are geometrically closer in this vector space. For instance, the embedding of "car" would be closer to "automobile" than to "banana."
AI agents primarily leverage vector databases to store vast amounts of unstructured text data. Common applications include maintaining conversational history, allowing agents to recall previous user queries or dialogue segments by searching for semantically related past interactions. Beyond conversations, vector stores are invaluable for retrieving pertinent documents, API documentation, or code snippets. Instead of relying on brittle, exact keyword matches, which can fail with synonyms or rephrasing, vector search allows agents to understand the implicit meaning of a user’s prompt and retrieve conceptually similar information. This "fuzzy matching" capability makes them robust against variations in language and intent.
From a practical standpoint, vector databases offer several compelling advantages. They provide remarkably fast search capabilities, even across billions of vectors, a critical factor for real-time AI agent interactions. Developers also find them relatively straightforward to set up and integrate compared to more structured database systems. The typical workflow involves segmenting text into manageable chunks, generating embeddings for each chunk using a pre-trained model, and then indexing these embeddings in the database. This ease of deployment, coupled with their strong performance in broad similarity matching, has positioned vector databases as the default choice for many early-stage AI agent prototypes and general-purpose assistants. According to a recent industry report, the vector database market is projected to grow significantly, reflecting their widespread adoption in AI and machine learning applications, with some estimates placing its compound annual growth rate (CAGR) at over 20% in the coming years.
However, semantic search, while powerful, has inherent limitations for advanced AI agent memory. Vector databases can struggle with complex, multi-step logic or when an agent needs to infer relationships that are not explicitly captured by semantic closeness. For example, if an agent needs to determine the connection between "Product A" and "Customer C" but only has data showing "Product A is used by Company B" and "Company B services Customer C," a simple semantic similarity search might fail to bridge these distinct but related pieces of information. The implicit nature of vector relationships can lead to challenges in following chains of reasoning. Furthermore, when dealing with dense, interconnected facts—such as dependencies in a software project or intricate organizational charts—vector databases can sometimes return a flood of "related but irrelevant" information. This "noise" can quickly overwhelm an agent’s context window, leading to suboptimal responses or increased computational load as the LLM attempts to distill useful insights from a large, less precise input.
Graph RAG: Structured Context and Relational Memory
To address the limitations inherent in purely semantic retrieval, Graph RAG has emerged as a sophisticated alternative, combining the explicit structure of knowledge graphs with the reasoning capabilities of LLMs. In this paradigm, memory is not a collection of dense vectors but a network of discrete entities and their explicit relationships. Entities, such as a "person," a "company," a "technology," or a "document," are represented as nodes in the graph. The connections between these entities—like "works at," "uses," "manufactures," or "approved by"—are represented as edges, each with a defined type and direction.
AI agents leveraging Graph RAG construct and continuously update a structured world model. As new information is processed, the agent employs advanced techniques, often including specialized LLM prompts or entity extraction models, to identify and extract relevant entities and the explicit relationships between them. These extracted facts are then added to the knowledge graph. When the agent needs to retrieve information, it doesn’t perform a broad semantic search; instead, it traverses explicit paths within the graph, following defined relationships to pinpoint the exact context required. This approach transforms retrieval from a probabilistic similarity match into a deterministic search for connected facts.
The primary strength of Graph RAG lies in its unparalleled precision and ability to handle complex, multi-hop reasoning. Because retrieval follows explicit, predefined relationships, the risk of inferential error or "hallucination" is significantly reduced. If a relationship does not exist in the graph, the agent cannot falsely infer it. This makes Graph RAG ideal for scenarios demanding high factual accuracy and adherence to specific logical structures. For instance, to answer a query like "Who are the direct reports of the manager who approved the Q3 budget for the R&D department?", a Graph RAG system can meticulously trace a path through the organizational structure, budget approval chain, and departmental assignments. This type of query, which relies on a precise sequence of relationships, would be exceptionally difficult, if not impossible, for a purely vector-based system to answer accurately.
Another major advantage of Graph RAG is its inherent explainability. The retrieval path is not an opaque similarity score but a clear, auditable sequence of nodes and edges, illustrating precisely how the answer was derived. This "glass box" approach is invaluable for enterprise applications requiring compliance, transparency, and the ability to debug or justify an AI agent’s reasoning process, particularly in regulated industries like finance, healthcare, or legal. Experts in knowledge graph technology, such as Dr. Claudia Gold, a leading researcher in semantic web technologies, note that "the explicit nature of graph relationships provides an unparalleled level of auditability and trust, which is becoming non-negotiable for mission-critical AI applications."
However, Graph RAG introduces considerable implementation complexity. Populating a knowledge graph demands robust entity-extraction pipelines that can accurately parse raw text into structured nodes and edges. This often requires carefully engineered prompts for LLMs, specialized natural language processing (NLP) models, or rule-based systems, all of which require significant development and fine-tuning. Furthermore, developers must design and maintain an ontology or schema, which defines the types of entities and relationships allowed in the graph. This schema can be rigid and challenging to evolve as new domains are encountered or as the agent’s knowledge scope expands. The "cold-start problem" is also prominent: unlike a vector database that provides immediate utility once text is embedded, a knowledge graph requires substantial upfront effort to populate with foundational entities and relationships before it can effectively answer complex, structured queries. This higher initial investment and ongoing maintenance overhead often deter organizations with immediate deployment needs or limited resources.
A Comparative Framework: Tailoring Memory to Task
The decision between vector databases and Graph RAG for AI agent memory hinges critically on the inherent structure of the data and the expected complexity of query patterns. Each architecture offers distinct strengths that make it better suited for particular use cases.
Vector Databases are ideal for:
- Unstructured Data: Chat logs, general documentation, sprawling knowledge bases derived from raw text, or multimodal content (images, audio).
- Broad Similarity Matching: When the query intent is to explore themes, find analogies, or discover conceptually related information (e.g., "Find me concepts similar to X," "What have we discussed regarding topic Y?").
- Low Setup Cost & Rapid Prototyping: They offer a quicker path to deployment due to simpler data preparation and indexing processes.
- Fuzzy Matching: Accommodating typos, paraphrasing, and variations in language without requiring strict query structures.
- High-Volume, Diverse Queries: Excellent for scenarios where the range of potential queries is vast and unpredictable, and precision on specific relationships is not the absolute highest priority.
Graph RAG is preferable for:
- Structured or Semi-Structured Data: Financial records, codebase dependencies, organizational charts, legal precedents, scientific ontologies, or product catalogs where relationships are explicit.
- Precise, Relational Queries: When queries demand categorical answers, multi-hop reasoning, or verification of specific connections (e.g., "How exactly is X related to Y?", "What are all the dependencies of this specific component?", "Who authorized this transaction?").
- High Factual Accuracy & Explainability: Critical for regulated industries or applications where trust, auditability, and verifiable reasoning are paramount.
- Managing Complex Hierarchies & Networks: Excels at navigating intricate structures where entities have defined roles and relationships.
- Context Window Optimization: By retrieving only the precisely relevant sub-graph, it can provide highly condensed and accurate context to the LLM, preventing information overload.
From a project management perspective, vector databases offer a lower entry barrier and provide good general accuracy for many applications, making them a default choice for early-stage prototypes and general-purpose assistants. Conversely, the higher setup cost and ongoing maintenance overhead of a Graph RAG system are justified by its ability to deliver unparalleled precision on specific connections, especially where vector search might overgeneralize, hallucinate, or simply fail to identify complex logical paths. Industry analysts often highlight that companies in sectors like finance, pharmaceuticals, and legal are increasingly exploring Graph RAG to leverage their highly structured internal data assets, which are often poorly served by purely semantic approaches.
The Future is Hybrid: Blending Strengths for Advanced Agents
The prevailing wisdom in advanced AI agent development is that the future of agent memory does not lie in an exclusive choice between vector databases and Graph RAG, but rather in a sophisticated hybrid architecture that leverages the strengths of both. Leading agentic systems are increasingly combining these methods to create more robust, versatile, and intelligent memory pipelines.
A common and highly effective hybrid approach involves using a vector database for the initial retrieval step, performing a broad semantic search across a vast corpus of information. This step aims to identify the most relevant "entry nodes" or starting points within a much larger, often massive, knowledge graph. For instance, a user might ask an agent, "Tell me about the recent acquisition by TechCorp." The vector database would semantically identify documents or facts related to "TechCorp" and "acquisition."
Once these initial relevant entry points are identified through semantic similarity, the system then shifts to graph traversal. It uses the identified nodes as anchors to explore the explicit relational context connected to them within the knowledge graph. This allows the agent to extract precise, structured information—such as the specific companies involved in the acquisition, the date, the financial terms, and the key executives—by following defined edges like "acquired," "date," "amount," and "involved party." This hybrid pipeline elegantly marries the broad, fuzzy recall of vector embeddings with the strict, deterministic precision and multi-hop reasoning capabilities of graph traversal.
This layered approach offers several significant benefits:
- Scalability: Vector databases can efficiently manage petabytes of unstructured data, acting as a powerful first filter.
- Precision: Graph traversal ensures that the final context provided to the LLM is factually accurate and logically coherent, minimizing hallucinations.
- Efficiency: By pre-filtering with vector search, the graph traversal can focus on a smaller, highly relevant subset of the knowledge graph, reducing computational overhead compared to blind graph exploration.
- Adaptability: It allows agents to handle both amorphous, exploratory queries and highly specific, fact-based questions within the same system.
- Enhanced Reasoning: The LLM receives not just raw text, but a structured, coherent piece of knowledge, enabling it to perform deeper and more accurate reasoning.
This convergence of technologies represents a significant leap forward in designing AI agents capable of enterprise-grade workflows, where the ability to reason over complex dependencies, ensure factual accuracy, and explain their logic is paramount. Companies like Google, Microsoft, and various AI startups are actively researching and implementing such hybrid systems, recognizing their potential to unlock new levels of AI performance and reliability.
Conclusion and Future Implications
Vector databases, with their ease of deployment and powerful semantic matching capabilities, remain the most practical starting point for general-purpose AI agent memory. For a wide array of applications, from basic customer support bots to preliminary coding assistants and broad research tasks, they provide sufficient context retrieval and a robust foundation for RAG. Their continued evolution, with advancements in embedding models and indexing techniques, will further solidify their role as a core component in many AI architectures.
However, as the demand for truly autonomous agents capable of navigating complex, multi-step, and enterprise-critical workflows grows, the limitations of purely semantic search become increasingly apparent. The need for agents that can reason over intricate dependencies, guarantee factual accuracy, and transparently explain their logical deductions elevates Graph RAG from a niche solution to a critical unlock for advanced AI.
Developers embarking on the journey of building sophisticated AI agents would be well advised to adopt a layered and strategic approach to memory architecture. Starting agent memory with a vector database provides an excellent foundation for basic conversational grounding and broad information retrieval. As the agent’s reasoning requirements mature and approach the practical limits of semantic search—especially when dealing with highly structured data, explicit relationships, or the need for auditable reasoning—selectively introducing knowledge graphs to structure high-value entities and core operational relationships becomes indispensable. This hybrid strategy not only optimizes for performance and precision but also positions AI agents to tackle the most challenging and impactful problems across industries, heralding a new era of intelligent, reliable, and explainable AI systems. The integration of these two powerful paradigms is not merely a technical choice but a strategic imperative for the future of artificial intelligence.