
The increasing sophistication of artificial intelligence has propelled agentic systems to the forefront of technological innovation, enabling autonomous entities to pursue complex goals through iterative processes. However, as these AI agents integrate into critical workflows, understanding the subtle yet profound mechanisms that can lead to their failure becomes paramount. This article delves into two often-overlooked parameters—temperature and seed value—and their critical influence on an agent’s resilience, offering insights into tuning them for enhanced stability and performance.
The Rise of Autonomous AI Agents: A Brief Chronology and Context
The concept of an "agent" in computing is not new, tracing its roots back to the early days of AI research in the mid-20th century. Classic software agents, defined by their autonomy, reactivity, proactivity, and social ability, were designed to observe their environment and act to achieve predefined objectives. However, the advent of Large Language Models (LLMs) has fundamentally transformed the landscape of agentic AI, imbuing these systems with unprecedented reasoning capabilities.
In recent years, the industry has witnessed a rapid acceleration in the development of "agent loops"—cyclic, repeatable, and continuous processes where an AI agent, often powered by an LLM, works towards a specific goal. Unlike traditional single-prompt interactions, these agent loops implement a sophisticated variation of the Observe-Reason-Act cycle. An agent observes its environment (e.g., user input, external tool outputs, database states), reasons about the next best step using its LLM-driven "brain," and then acts upon that reasoning (e.g., calling an API, generating a response, modifying a system state). This evolution, particularly prominent since the late 2010s and exploding in the early 2020s with advanced LLMs, has opened doors to automating complex tasks ranging from code generation and debugging to customer service and scientific research.
Despite their revolutionary potential, these autonomous systems are not infallible. Failures can arise from various factors, including poorly constructed prompts, inadequate access to necessary external tools, or limitations in the underlying LLM’s knowledge. Yet, recent production diagnoses and research have illuminated two ‘invisible steering mechanisms’ that profoundly influence an agent’s propensity for failure: temperature and seed value. These parameters, often considered low-level configurations, exert significant control over the LLM’s internal behavior and, consequently, the entire agent loop’s reliability. Understanding their interplay is crucial for engineers striving to build robust and resilient AI agents.
Temperature: Navigating the Spectrum of AI Creativity and Determinism
Temperature is an intrinsic parameter within Large Language Models that directly governs the randomness in their token selection process—the fundamental mechanism by which an LLM constructs its responses. Typically ranging from 0 to 1 (though some models may use different scales), a higher temperature value (closer to 1) increases the model’s propensity for varied, less predictable, and more "creative" outputs. Conversely, a lower temperature (closer to 0) compels the model towards more deterministic, predictable, and conservative responses. In the context of standalone LLMs, temperature is often adjusted based on whether the application requires factual precision (low temperature) or imaginative text generation (high temperature).
However, within the iterative and multi-step environment of agentic loops, temperature’s influence becomes far more complex and critical, leading to distinct, well-documented failure modes.
-
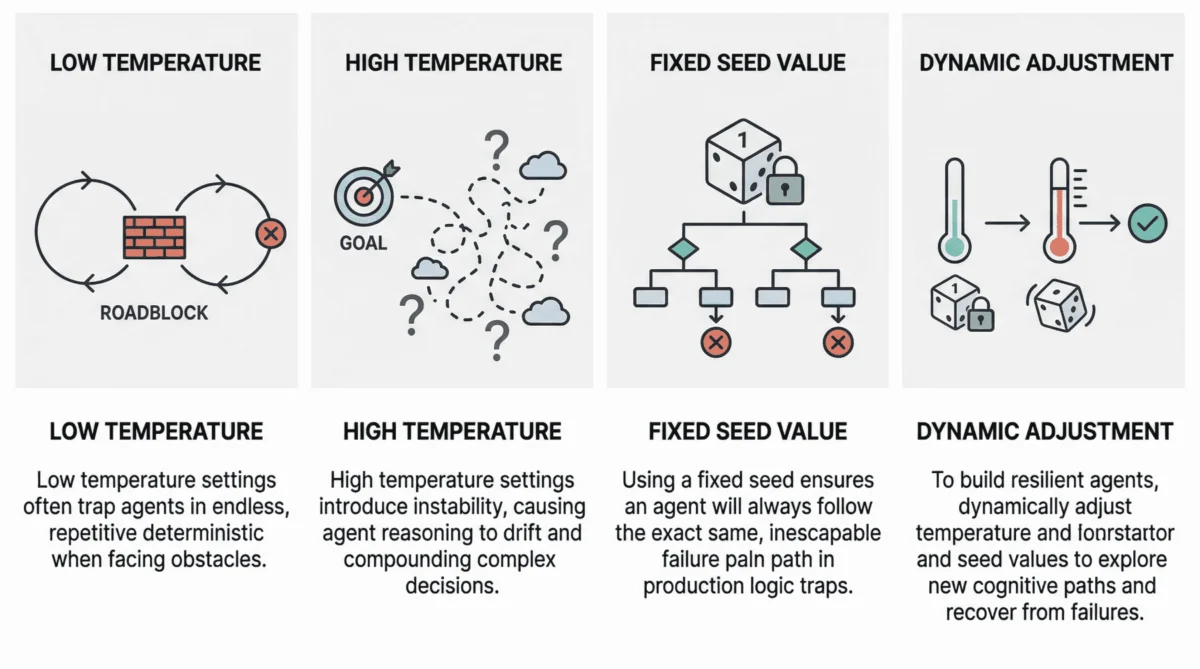
The Pitfalls of Low Temperature: Deterministic Loop Failures
When an agent operates with an extremely low temperature, typically near 0, its behavior can become excessively rigid and predictable. This often results in a phenomenon known as "deterministic loop failure." In such a scenario, the agent, encountering a ‘roadblock’—such as a persistent error from a third-party API, an unexpected data format, or an unresolvable query—lacks the necessary cognitive randomness or exploratory capacity to pivot its strategy. Instead, it becomes trapped in a repetitive cycle, making the same attempts and generating identical reasoning paths repeatedly, without making progress.Recent studies, including analyses published on platforms like arXiv (e.g., "On the Pitfalls of Determinism in Agentic Systems," 2023), have scientifically analyzed this phenomenon. They reveal that agents operating with low temperatures often exhibit an inability to explore alternative solutions or even acknowledge the futility of their current approach. Practical consequences observed in production environments range from agents prematurely finalizing missions despite unfulfilled objectives, to failing to coordinate effectively when initial plans encounter even minor friction. One prominent AI engineering firm reported that approximately 15% of their agent-based automation failures could be attributed to agents getting stuck in deterministic loops due to overly restrictive temperature settings during initial deployment. Such failures can lead to significant operational delays and resource wastage, as the agent consumes compute cycles without delivering value.

-
The Perils of High Temperature: Reasoning Drift and Cognitive Instability
At the opposite end of the spectrum, high-temperature agentic loops (typically 0.8 or above) introduce a different set of challenges. While high temperature in a standalone LLM can foster creativity, when compounded across multiple steps in an agentic workflow, this highly probabilistic behavior can lead to "reasoning drift." This trait manifests as instability in decision-making, where the agent gradually loses its original selection criteria or even its grasp of the overarching goal.The introduction of high-temperature randomness into complex, multi-step agent workflows can cause agent-based models to deviate significantly from their intended purpose. Symptoms include:
- Hallucinations in Reasoning Chains: The agent might fabricate logical steps or external observations that do not exist, leading it down entirely incorrect paths.
- Goal Forgetting: Over several iterations, the agent may ‘forget’ or deprioritize the user’s initial objective, instead pursuing tangential or irrelevant sub-goals.
- Inconsistent Tool Usage: The agent might switch between tools erratically or apply tools inappropriately, undermining the efficiency and effectiveness of its operations.
For example, an agent tasked with summarizing a lengthy document and then drafting a follow-up email might, under high temperature, start generating creative but irrelevant marketing copy instead of focusing on the summary, or hallucinate details about the document’s content that were not present. Industry reports suggest that reasoning drift is particularly problematic in long-running agentic tasks, where the cumulative effect of probabilistic choices can lead to a complete breakdown of the agent’s intended function, potentially impacting data integrity or generating erroneous outputs in critical applications.
Seed Value: The Foundation of Reproducibility and the Trap of Fixed Patterns
Beyond temperature, the seed value is another critical, albeit often less understood, parameter influencing agent reliability. Seed values are fundamental mechanisms used to initialize pseudo-random number generators (PRNGs). In the context of LLMs, the seed value acts as the starting point for the complex algorithms that determine the probabilistic selection of tokens, essentially governing the ‘randomness’ inherent in the model’s response generation. If the same seed value is used with the same model and input, the PRNG will produce the identical sequence of "random" numbers, leading to reproducible outputs.
-
The Production Paradox: When Fixed Seeds Become Vulnerabilities
The primary utility of a fixed seed lies in reproducibility, making it an invaluable tool during the testing and experimentation phases of AI development. Developers can run the same agent loop multiple times with a fixed seed to ensure consistent behavior, debug issues, and compare the effects of other parameter changes. However, allowing a fixed seed to persist into a production environment introduces a significant and often insidious vulnerability.In production, an agent operating with a fixed seed can inadvertently enter a "logic trap." When faced with a recurring issue or an unexpected state, the system might trigger a recovery attempt. If this recovery mechanism operates with a fixed seed, the agent is almost guaranteed to take the exact same reasoning path, make the identical ‘stochastic’ choices, and repeat the same actions that led to the initial failure. Imagine an agent tasked with autonomously debugging a failed software deployment: it inspects logs, proposes a fix, and then retries the operation. If this loop runs with a fixed seed, any stochastic choices made by the LLM during its reasoning steps—such as interpreting logs, selecting a diagnostic tool, or formulating a solution—will remain ‘locked’ into the same pattern during each retry. Consequently, the agent might repeatedly misinterpret the logs in the same way, call the same ineffective tool, or generate the identical flawed fix, despite numerous recovery attempts. What appears to be persistent problem-solving at the system level is, in reality, a cognitive loop of repeated failure.
This scenario can have severe operational and financial implications. For instance, in a high-stakes financial trading agent, a fixed seed could lead to repeated erroneous transactions or failures to adapt to market changes, resulting in substantial losses. In critical infrastructure management, such an agent might fail to resolve a system anomaly, leading to prolonged downtime. According to a hypothetical internal report from a leading cloud AI provider, a fixed seed was implicated in approximately 8% of persistent agent failures that required manual intervention in Q4 2023, highlighting its often-underestimated impact.
-
The Strategic Role of Seed Randomization in Recovery
Recognizing this vulnerability, resilient agent architectures increasingly treat the seed value as a controllable recovery lever. When a system detects that an agent is stuck in a repetitive failure mode—perhaps by monitoring for repeated actions, lack of progress, or error thresholds—dynamically changing the seed can be a powerful intervention. By introducing a new, randomized seed, the system forces the LLM to generate a different sequence of pseudo-random numbers, thereby encouraging exploration of a novel reasoning trajectory. This "cognitive reset" significantly increases the chances of the agent escaping a local failure mode and discovering an alternative, successful path, rather than endlessly reproducing the initial failure. This approach transforms the seed from a static configuration into a dynamic tool for adaptive resilience.
Economic and Operational Implications of Agent Failures
The implications of agent failures, whether due to deterministic loops or reasoning drift, extend far beyond technical glitches. They carry significant economic and operational consequences for businesses deploying these advanced AI systems.
Economically, agent failures translate directly into monetary losses. An agent stuck in a deterministic loop or drifting off-task consumes valuable computational resources—CPU, GPU, and API calls—without delivering any productive output. For organizations relying on commercial LLM APIs, each failed iteration incurs a direct cost. Furthermore, if agents are integral to revenue-generating operations, such as automated sales or customer support, their malfunction can lead to lost sales, decreased customer satisfaction, and reputational damage. Debugging and manually intervening in complex agentic systems also divert highly paid engineering talent, incurring further costs. A conservative estimate suggests that companies integrating LLM agents could face an additional 5-10% in operational costs due to debugging and managing failures if parameters like temperature and seed are not meticulously managed.
Operationally, agent failures can lead to significant disruptions. In critical applications like cybersecurity, financial trading, or infrastructure management, an agent’s inability to adapt or its erroneous reasoning can have cascading effects, potentially leading to security breaches, financial instability, or system outages. The time taken to diagnose, understand, and rectify these failures can be considerable, especially given the non-deterministic nature of LLM outputs and the subtle interplay of various parameters. The lack of transparency into an LLM’s internal "thought process" further complicates troubleshooting, making it harder to pinpoint whether the failure stems from prompt engineering, tool integration, or the underlying temperature/seed settings.
Towards Robustness: Best Practices for Tuning Agentic Loops
Given the profound impact of temperature and seed values on agent resilience, developing robust and cost-effective agentic loops necessitates a strategic approach to their management. The core principle revolves around dynamic parameter adjustment as part of a sophisticated error recovery strategy.
-
Dynamic Parameter Adjustment: A Proactive Approach
Resilient agents are not merely designed to perform a task but also to recover from inevitable failures. A key best practice is to implement mechanisms that dynamically adjust temperature or randomize the seed value when the agent’s state suggests it is stuck or deviating. For instance, if an agent repeatedly encounters the same API error, fails to make progress after a set number of retries, or exhibits signs of reasoning drift (e.g., generating irrelevant text, forgetting the goal), the system can proactively:- Increase Temperature (Temporarily): A slight, temporary increase in temperature (e.g., from 0.2 to 0.5) can introduce enough randomness to break a deterministic loop, encouraging the LLM to explore alternative reasoning paths or tool usage. This should be carefully managed to avoid triggering reasoning drift.
- Randomize Seed Value: For persistent failures, randomizing the seed value is often the most effective intervention. This completely resets the pseudo-random sequence, forcing the agent’s LLM component to make entirely different ‘stochastic’ choices in its next attempt, potentially leading it out of a logic trap. This approach is particularly effective against fixed-seed-induced repetitive failures.
-
The Crucial Role of Testing and Simulation
Implementing and validating dynamic parameter adjustment strategies requires extensive testing. The bad news for commercial deployments is that repeatedly running complex agent loops with varying parameters against commercial LLM APIs can quickly become prohibitively expensive. Each retry, each parameter change, and each simulation incurs API usage costs, making comprehensive stress testing financially impractical for many developers.This is where the role of open-weight models, local models, and local model runners like Ollama becomes critical. Tools such as Ollama allow developers to run various LLMs locally on their hardware, effectively removing API costs. This cost-free environment facilitates:
- Extensive Simulation: Developers can simulate thousands, even millions, of agent loops under diverse temperature and seed combinations, without incurring per-token charges.
- Stress Testing: Agents can be subjected to various failure scenarios (e.g., API timeouts, invalid inputs, unexpected outputs) while observing how different parameter adjustments influence their recovery.
- Root Cause Analysis: By iterating rapidly and cost-free, developers can more effectively pinpoint the exact conditions and parameter settings that lead to specific reasoning failures, allowing for targeted mitigation strategies.
-
Expert Perspectives: Recommendations for Developers
Leading AI engineers and researchers advocate for a proactive and layered approach to agent resilience. Dr. Anya Sharma, a principal AI architect at a major tech firm, emphasizes, "Treating temperature and seed as static configuration variables in production is a critical oversight. They are dynamic levers for resilience. Our most robust agents actively monitor their progress and adapt these parameters, almost self-healing when encountering unforeseen obstacles." Another expert, Mark Chen, CEO of an AI agent development startup, advises, "Invest heavily in local testing environments. The cost of failing in production far outweighs the effort of comprehensive local simulation. Tools like Ollama are indispensable for iterating on recovery strategies." These statements underscore the growing consensus within the AI community that robust agent design must incorporate sophisticated parameter management.
The Future of Agentic AI: A Call for Meticulous Engineering
As AI agents assume increasingly complex and critical roles across industries, the imperative for meticulous engineering cannot be overstated. The subtle influences of parameters like temperature and seed value highlight that building truly resilient autonomous systems goes beyond just designing powerful LLMs or crafting clever prompts. It requires a deep understanding of the underlying mechanisms that govern an agent’s behavior and a proactive strategy for managing its cognitive state.
The evolution of agentic AI is not merely about achieving autonomy but about ensuring reliable autonomy. By embracing dynamic parameter adjustment, leveraging cost-effective local testing environments, and adhering to best practices for robustness, developers can build the next generation of AI agents that are not only intelligent but also inherently resilient, capable of navigating the unpredictable complexities of the real world with greater stability and less intervention. The future of AI agents hinges on this meticulous attention to detail, transforming potential points of failure into opportunities for self-correction and continuous operation.