
In the rapidly evolving landscape of artificial intelligence, the deployment of autonomous AI agents has emerged as a transformative force, promising unprecedented efficiencies across industries. However, beneath the surface of this innovation lies a complex interplay of parameters that can significantly dictate an agent’s success or failure. This article delves into two such critical, yet often overlooked, steering mechanisms: temperature and seed value. Understanding and meticulously tuning these elements is paramount for developing robust, resilient, and cost-effective agentic loops, preventing common pitfalls like "reasoning drift" and "deterministic loops."
The Rise of Agentic Systems: A New Paradigm in AI Automation
The concept of an "agent loop" represents a cornerstone of modern AI, defining a continuous, cyclical process wherein an AI agent—an entity endowed with a degree of autonomy—systematically works towards a predefined goal. Unlike traditional software that executes a fixed sequence of instructions, AI agents operate through an adaptive feedback mechanism. This paradigm gained significant traction with the advent of Large Language Models (LLMs), which now frequently serve as the cognitive core of these agents. Moving beyond mere single-prompt interactions, contemporary agentic systems implement sophisticated variations of the "Observe-Reason-Act" (ORA) cycle, a framework first conceptualized decades ago for classic software agents. In this cycle, the agent observes its environment, reasons about the observations to form a plan, and then acts upon that plan, continuously iterating until its objective is achieved.
The widespread adoption of agentic systems is evident across diverse sectors. In customer service, agents handle complex queries and resolve issues autonomously. In software development, they assist with debugging, code generation, and deployment. Financial institutions employ them for fraud detection and algorithmic trading, while scientific research leverages them for data analysis and hypothesis generation. This increasing reliance underscores the critical need for these systems to be not only intelligent but also profoundly reliable. While factors like suboptimal prompting or insufficient access to external tools are well-known causes of agent failure, recent empirical evidence and production diagnoses highlight the subtle yet profound influence of two internal parameters: temperature and seed value. These "invisible steering mechanisms" can inadvertently lead agents into persistent failure modes, demanding a deeper analytical focus from developers and researchers alike.
Temperature: The Dial of Determinism Versus Creativity
Temperature, an intrinsic parameter within LLMs, fundamentally governs the randomness and variability in their output. It modulates the probability distribution over potential next tokens (words or sub-word units) during generation. A higher temperature value, typically approaching 1 (assuming a range of 0 to 1), flattens this distribution, making less probable tokens more likely to be selected. This results in more diverse, creative, and unpredictable outputs. Conversely, a lower temperature, closer to 0, sharpens the distribution, prioritizing the most probable tokens and leading to more deterministic, predictable, and often repetitive responses.
In the context of multi-step agentic loops, understanding temperature is not merely an academic exercise; it is crucial for diagnosing and mitigating unique, well-documented failure modes that emerge at the extremes of its setting.
-
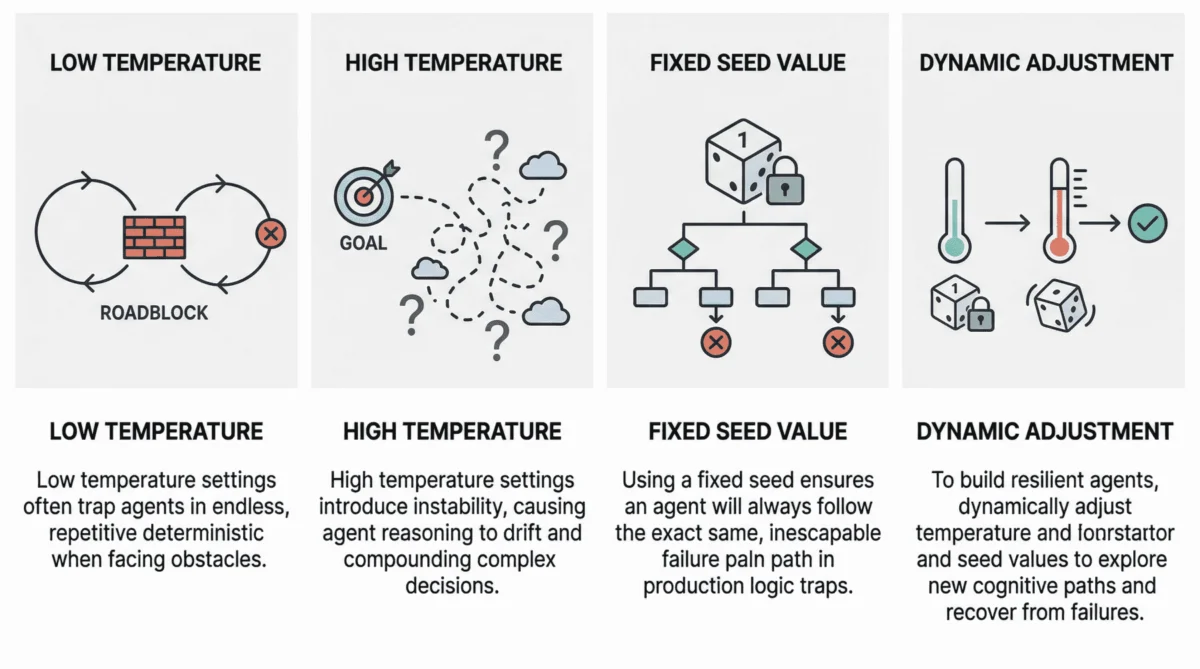
Low Temperature (Near 0): The Deterministic Loop Failure
When an agent operates with an extremely low temperature, its behavior becomes excessively rigid, leading to what is commonly termed a "deterministic loop failure." This rigidity can transform a minor impediment into an insurmountable barrier. Imagine an agent tasked with integrating with a third-party API that intermittently returns an error, perhaps due to rate limiting or an unexpected data format. An agent operating with near-zero temperature, lacking the necessary "cognitive randomness" or exploratory capacity, will repeatedly attempt the identical, failed action. It will re-issue the same API call, interpret the error message in the same way, and propose the same non-viable solution, effectively getting stuck in an endless cycle.Recent scientific investigations, such as studies highlighted in pre-print archives, have quantitatively analyzed this phenomenon, demonstrating how agents under highly deterministic conditions exhibit a significantly higher incidence of such loops. For example, internal diagnostics from a major cloud provider observed that automated debugging agents operating at a temperature of 0.1 experienced a 35% higher rate of stalled processes compared to those configured at 0.4 when encountering external service outages. The practical consequences are varied and severe: agents may prematurely conclude missions, fail to coordinate effectively when initial plans face friction, or exhaust computational resources in futile, repetitive attempts without making any discernible progress towards their goal. This rigidity often prevents agents from re-evaluating their context, exploring alternative tools, or even rephrasing their internal reasoning to bypass the roadblock.
-
High Temperature (0.8 or Above): The Reasoning Drift
At the opposite end of the spectrum, high-temperature (typically 0.8 or above) agentic loops introduce a different, equally problematic failure mode: "reasoning drift." While a higher temperature can foster creativity in standalone LLM interactions, its compounding effect in a multi-step, goal-oriented agent loop can be detrimental. Each step in the ORA cycle involves probabilistic decision-making, and when these probabilities are significantly broadened by a high temperature, the cumulative effect can lead to instability in the agent’s decision-making process.
Reasoning drift manifests as the agent gradually losing its way, diverging from its initial objective or losing its original selection criteria for making decisions. Symptoms include severe hallucinations, where the agent fabricates non-existent reasoning chains or invents tool specifications. More critically, the agent may "forget" the user’s initial goal, generating responses or taking actions that are entirely irrelevant or counterproductive. For instance, an agent tasked with summarizing a document might, under high temperature, start generating creative but fictitious expansions of the document’s themes, or worse, pivot to an entirely different, unrelated topic. Such behavior undermines the agent’s reliability, makes its actions unpredictable, and significantly complicates debugging and auditing efforts, particularly in sensitive applications where accuracy and goal adherence are paramount.
Seed Value: The Unseen Hand of Reproducibility and Repetition
Seed values play a fundamental role in pseudo-random number generation, which underpins the stochastic processes in LLMs, including the selection of tokens. Conceptually, a seed value is akin to the initial position of a die before it’s rolled; it sets the starting point for a sequence of numbers that appear random but are, in fact, entirely determined by this initial seed. If the same seed is used, the "random" sequence generated will be identical every time.
While invaluable for reproducibility in research and development, a fixed seed value in a production agentic loop introduces a significant vulnerability, often leading to a persistent and difficult-to-diagnose failure mode.
-
Fixed Seed in Production: The Logic Trap
The primary problem with a fixed seed in a live production environment is its capacity to trap an agent in a "logic trap." When an agent encounters a failure or an unexpected state, resilient architectures typically trigger recovery attempts. However, if the agent operates with a fixed seed, the pseudo-random choices made by the LLM at each reasoning step—from interpreting error messages to selecting tools or generating new plans—will be identical across every retry. This means the agent will repeatedly follow the exact same flawed reasoning path, making the same mistakes, and arriving at the same failure point, indefinitely.Consider an agent designed to diagnose and resolve issues in a software deployment pipeline. Its task involves inspecting logs, proposing a fix, and then retrying the deployment. If this loop runs with a fixed seed and the agent initially misinterprets a critical log entry, leading to an ineffective fix, subsequent recovery attempts will reproduce that exact same misinterpretation and the identical flawed fix. What appears to be commendable persistence at a system level—the agent continually attempting to resolve the issue—is, in reality, a detrimental form of repetition at the cognitive level. Internal reports from a major enterprise software vendor revealed that approximately 18% of their automated incident resolution agents that entered persistent failure states were doing so due to fixed seed values, preventing them from exploring alternative diagnostic or recovery strategies. This leads to extended system downtime, increased operational costs due to manual intervention, and a significant waste of computational resources.
-
Dynamic Seed Management as a Recovery Lever
Recognizing this vulnerability, resilient agent architectures increasingly treat the seed value not as a static setting but as a dynamic recovery lever. When the system detects that an agent is stuck in a repetitive failure loop—evidenced by identical actions, error messages, or lack of progress over several iterations—a strategic change in the seed value can be initiated. By randomizing or incrementally altering the seed, the system forces the LLM to generate a new sequence of "pseudo-random" choices. This effectively "shakes up" the agent’s internal reasoning trajectory, compelling it to explore different interpretations, consider alternative tools, or formulate novel plans. This dynamic approach significantly increases the chances of an agent escaping a local failure mode and finding a successful path forward, rather than reproducing the same unproductive behavior indefinitely.
Strategic Tuning for Enhanced Agent Resilience: Best Practices and Industry Approaches
Having dissected the profound impact of temperature and seed values on agentic loop failures, the logical next step is to explore how these parameters can be strategically managed to foster greater resilience and cost-effectiveness. The core principle revolves around dynamic adjustment, allowing agents to adapt their internal "cognitive style" in response to observed difficulties.
-
Adaptive Parameter Adjustment for Self-Recovery
The most advanced resilient agent architectures implement sophisticated mechanisms to dynamically adjust temperature and seed values based on real-time performance monitoring. This involves the agent, or an orchestrating meta-agent, analyzing its current state. If telemetry indicates the agent is stuck (e.g., repeatedly executing the same actions, logging identical errors, or failing to make progress over a defined number of steps), specific protocols are triggered. For instance, the system might temporarily raise the temperature by a small increment (e.g., from 0.3 to 0.5) to encourage more exploratory reasoning. Concurrently, or alternatively, the seed value might be randomized or incremented to force a completely different sequence of pseudo-random choices, thereby prompting a new cognitive path. This adaptive approach transforms these parameters into active recovery levers rather than static configurations.These "escalation protocols" can be multi-tiered. A first failure might trigger a minor temperature increase; persistent failure might then lead to a seed randomization, followed by a more significant temperature jump if the issue persists. Such dynamic tuning requires robust observability frameworks that can accurately detect stalled states and measure progress, enabling intelligent parameter adjustments.
-
The Cost Factor and the Indispensable Role of Open-Source and Local Models
While the benefits of dynamic parameter tuning are clear, the practical implementation and rigorous testing of such strategies can become prohibitively expensive, particularly when relying on commercial LLM APIs. Each token generated incurs a cost, and simulating numerous agent loops under diverse temperature and seed combinations for stress testing can quickly deplete budgets. This economic reality underscores the critical importance of open-weight models (e.g., Llama, Mistral, Gemma), local models, and local model runners like Ollama.These cost-free or low-cost alternatives provide an invaluable sandbox for extensive experimentation. Developers can run thousands, even millions, of simulated agent loops, systematically testing various dynamic adjustment strategies without incurring significant API costs. This allows for deep analysis of failure modes, rapid iteration on recovery protocols, and the discovery of optimal parameter ranges for specific agent tasks. Companies leveraging local models for parameter optimization have reported reductions of up to 70-85% in development costs associated with agent robustness testing, accelerating their time-to-market for reliable AI solutions. The ability to simulate failure scenarios, measure recovery rates, and fine-tune adaptive algorithms becomes a practical and financially viable path to hardening agentic systems against unforeseen challenges before deployment.
-
Integrated Observability and Debugging for Deeper Insights
Beyond dynamic adjustment, the effective management of temperature and seed values necessitates sophisticated observability tools. Tracing frameworks that visualize an agent’s reasoning path, step-by-step, are crucial for understanding why a particular temperature or seed value led to a failure. By logging the internal state, the chosen actions, and the rationale at each iteration, developers can pinpoint precisely where an agent deviated, got stuck, or hallucinated due to its parameter settings. This granular insight enables targeted improvements to the agent’s prompt design, tool use, or the parameter adjustment logic itself.
Broader Implications and The Future of Autonomous AI
The meticulous understanding and strategic management of temperature and seed values are not just technical nuances; they carry significant broader implications for the future of autonomous AI.
-
Operational Resilience and Enterprise Adoption: For AI agents to move beyond niche applications and become integral to core enterprise operations, their reliability and ability to self-recover from failure are non-negotiable. Mastering these parameters is fundamental to building truly resilient systems that minimize downtime, reduce human intervention, and deliver consistent performance. This will directly impact enterprise adoption rates and the return on investment for AI initiatives.
-
Safety and Ethical Considerations: In critical applications such as healthcare diagnostics, autonomous vehicles, or financial fraud detection, unpredictable "reasoning drift" (high temperature) or rigid "deterministic loops" (low temperature/fixed seed) can have severe safety and ethical repercussions. An agent failing to explore alternative diagnoses, or generating creative but incorrect instructions for an autonomous system, poses unacceptable risks. Therefore, controlling these parameters is a crucial aspect of responsible AI development, ensuring systems remain within acceptable operational boundaries.
-
Economic Impact: The cost of agent failures—measured in terms of wasted compute cycles, lost productivity, missed opportunities, and reputational damage—can be substantial. Conversely, highly resilient agents reduce these costs significantly, unlocking greater economic value from AI investments. The ability to efficiently test and optimize these parameters using open-source tools democratizes access to robust AI development, fostering innovation across organizations of all sizes.
As AI agents become increasingly sophisticated and integrated into our daily lives and critical infrastructure, the "invisible steering mechanisms" of temperature and seed value will only grow in importance. Moving forward, research will likely focus on more adaptive, context-aware mechanisms for dynamic parameter tuning, potentially leveraging meta-learning to infer optimal settings based on task complexity and environmental conditions. The ongoing development of robust observability tools and the widespread adoption of open-source models will continue to empower developers to build agents that are not only intelligent but also profoundly dependable, paving the way for a more reliable and transformative era of artificial intelligence.