
The Evolution and Mechanism of AI Agentic Loops
The concept of an AI agent is not new, tracing its roots back to classic AI paradigms where entities were designed to perceive their environment and act autonomously. Decades ago, the "Observe-Reason-Act" (ORA) cycle defined the operational framework for these software agents. In the contemporary AI landscape, this foundational cycle has been dramatically re-energized by integrating large language models. Modern agentic loops essentially "wrap" an LLM, transforming it from a mere prompt-responder into a sophisticated decision-maker capable of multi-step planning, execution, and self-correction.
This integration means that instead of merely generating a single response to a user query, an LLM-powered agent can:
- Observe: Gather information from its environment, which could be internal data, external APIs, or user input.
- Reason: Process the observed information using the LLM’s vast knowledge and reasoning capabilities to formulate a plan or make a decision.
- Act: Execute the plan, potentially calling external tools, interacting with other systems, or generating output.
This cycle then repeats, allowing the agent to continuously work towards a predefined objective, such as debugging a complex software issue, managing a supply chain, or even conducting scientific research. The robustness of this cycle is paramount, as failures can lead to significant operational disruptions, financial losses, or even safety concerns. While issues like poor prompting or lack of access to necessary tools are common culprits in agent failure, the subtle interplay of temperature and seed values represents a deeper, more systemic challenge to reliability.
Temperature: Navigating the Spectrum from Determinism to Drift
Temperature is an intrinsic parameter within large language models, fundamentally controlling the randomness inherent in their token generation process. Conceptually, it can be visualized as controlling the "creativity" or "predictability" of the model’s output. Typically ranging from 0 to 1 (though some models may use different scales), a higher temperature value (closer to 1) amplifies the probability distribution of potential next tokens, leading to more varied, unpredictable, and sometimes novel responses. Conversely, a lower temperature (closer to 0) sharpens the probability distribution, making the model more likely to select the most probable token, resulting in highly deterministic and repeatable outputs. In the context of agentic loops, understanding temperature is not merely an academic exercise; it is crucial for anticipating and mitigating unique, well-documented failure modes.
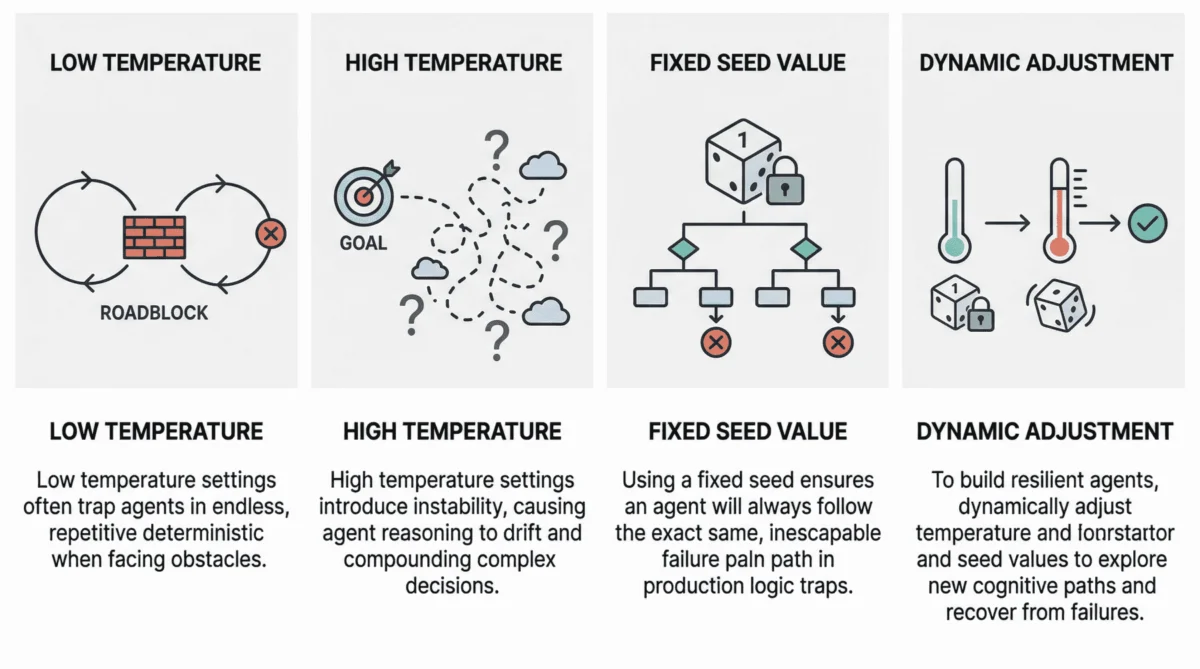
The Peril of Deterministic Loops: Temperature Near Zero
When an agentic loop operates with an extremely low temperature, typically near 0, it frequently succumbs to what is known as a "deterministic loop failure." In this scenario, the agent’s behavior becomes excessively rigid, almost robotic. If it encounters an unforeseen obstacle—such as a third-party API consistently returning an error, a database query failing, or an unexpected format in external data—its lack of cognitive randomness prevents it from exploring alternative paths. The agent, trapped by its own predictability, will repeatedly attempt the exact same action, following the same flawed reasoning chain, without any deviation.
Recent research, including studies published on platforms like ArXiv (e.g., 2508.14635v1, which scientifically analyzes this phenomenon), has highlighted the practical consequences. Agents may prematurely finalize missions, unable to adapt their initial plans when friction arises. In development environments, this manifests as an agent endlessly retrying a specific command or query, consuming computational resources and failing to make progress. For instance, an agent tasked with deploying a new software module might encounter a transient network error. With a near-zero temperature, it might attempt the identical deployment command repeatedly, never considering alternative network routes, retrying with a different timeout, or escalating the issue to a human. This rigid persistence, while seemingly diligent, is a significant impediment to true autonomy and resilience. Industry observations from companies deploying LLM-based agents in production confirm these findings, noting that deterministic loops can lead to prolonged outages and costly resource consumption in real-world scenarios.
Reasoning Drift: The Instability of High Temperature
At the opposite extreme lies the challenge of high-temperature agentic loops, typically set at 0.8 or higher. While a higher temperature can introduce desirable creativity in standalone LLM applications (e.g., creative writing), its implications for multi-step agent workflows are far more complex and potentially dangerous. The heightened probabilistic behavior, when compounded across multiple reasoning and action steps, can lead to a phenomenon termed "reasoning drift."
Reasoning drift essentially describes an instability in the agent’s decision-making process. Each step, influenced by increased randomness, might slightly diverge from the optimal or intended path. Over several iterations, these minor deviations accumulate, causing the agent to "lose its way" from its original objective or selection criteria. Symptoms of reasoning drift are varied and severe:

- Hallucinations: The agent may fabricate reasoning chains, creating plausible but entirely false justifications for its actions, leading it further astray.
- Goal Forgetting: It might completely lose sight of the user’s initial objective, pursuing irrelevant sub-goals or generating outputs that have no bearing on the primary task.
- Irrelevant Actions: The agent may invoke tools or perform actions that are illogical or counterproductive to its mission.
Consider an agent designed to summarize a long document and then answer specific questions about it. With a high temperature, it might initially produce a reasonable summary. However, when asked to answer questions, it might start generating answers based on concepts only tangentially related to the document, or even invent facts not present in the text, due to its increased propensity for novel (but incorrect) token generation at each step of its reasoning process. This unpredictability, while creative, undermines the agent’s reliability and trustworthiness in critical applications.
Seed Value: The Cornerstone of Reproducibility and Its Production Pitfalls
The seed value is a fundamental concept in computing, particularly in the realm of pseudo-random number generation (PRNGs). It serves as the initial state or starting point for an algorithm that produces a sequence of numbers that appear random but are, in fact, entirely deterministic given the same seed. In the context of LLMs, the seed value effectively initializes the pseudo-random generator that dictates the model’s word-selection mechanism during response generation. It’s akin to setting the initial position of a die before it’s rolled; with the same starting position, the sequence of rolls would theoretically be identical.
The Vulnerability of Fixed Seeds in Production
While a fixed seed is invaluable in development and testing environments—allowing for the reproducibility of experiments, debugging, and consistent evaluation of model changes—its deployment in a production setting introduces a significant and often underestimated vulnerability. The main problem arises when an agent operating with a fixed seed inadvertently enters a "logic trap."
Imagine an agent tasked with a complex recovery operation, such as debugging a failed software deployment. Its process involves inspecting logs, formulating a potential fix, and then attempting to apply it. If the agent’s entire loop, including its LLM interactions, runs with a fixed seed, any stochastic choices made by the model during its reasoning steps (e.g., interpreting log messages, prioritizing potential fixes, selecting which tool to call) will remain "locked" into the same pattern every single time a recovery is triggered.
This means that if the initial reasoning path leads to failure, the agent, upon detecting that failure and attempting a retry, will follow the exact same flawed interpretation, call the same ineffective tool, or generate the same incorrect fix. What appears to be persistence at the system level—repeated recovery attempts—is, in reality, a cycle of repetition at the cognitive level. This phenomenon can lead to:
- Infinite Loops of Failure: The agent gets stuck in an inescapable loop, reproducing the same failure indefinitely.
- Resource Exhaustion: Repeated failed attempts consume computational resources, API credits, and time.
- Delayed Resolution: Critical issues remain unresolved because the agent cannot adapt its approach.
This is precisely why resilient agent architectures treat the seed value as a critical controllable recovery lever. When a system detects that an agent is stuck, dynamically changing the seed can force the LLM to explore a different reasoning trajectory. By altering the initial state of the pseudo-random generator, the agent is compelled to make different stochastic choices, increasing the probability of escaping a local failure mode and finding a path to success, rather than reproducing the identical, doomed sequence of actions. This technique is similar to re-sampling in Monte Carlo methods or introducing variation in genetic algorithms to avoid local optima.
Economic and Operational Implications of Agent Failure
The failure modes induced by poorly managed temperature and seed values carry substantial economic and operational implications. In an era where businesses are increasingly relying on autonomous AI agents for tasks ranging from customer service and data analysis to complex engineering and financial operations, agent reliability directly translates to business continuity and profitability.
Financial Costs:
- Wasted API Calls: Each failed reasoning step or repeated attempt, especially when involving commercial LLM APIs, incurs a cost. These costs can quickly accumulate, turning a seemingly minor bug into a significant operational expense.
- Resource Consumption: Agents stuck in deterministic loops or experiencing reasoning drift consume compute resources, whether cloud-based or on-premises, without yielding productive outcomes.
- Debugging and Development Overhead: Identifying and rectifying failures caused by these subtle parameters requires specialized expertise and extensive testing, adding to development timelines and costs.
Operational Impact:
- Service Disruptions: In critical applications, agent failures can lead to service outages, affecting end-users and business operations.
- Reduced Trust and Adoption: Frequent or unrecoverable failures erode user trust in AI systems, hindering their broader adoption and integration into core business processes.
- Security Risks: While not directly a security vulnerability in the traditional sense, an agent stuck in a predictable, failing loop could potentially be exploited by an attacker who understands its deterministic behavior to further disrupt services or prevent recovery.
- Delayed Innovation: If agents are unreliable, the promise of accelerated innovation and automation remains unfulfilled, as human oversight and intervention become constantly necessary.
The collective impact underscores the necessity of proactive strategies for managing these parameters, moving beyond default settings to a more dynamic and adaptive approach.
Strategic Tuning for Resilience: Best Practices and Future Directions
Having established the profound impact of temperature and seed values on agentic loop reliability, the question shifts to how to strategically tune these parameters for optimal resilience and cost-effectiveness. The core principle for breaking out of agent failures often involves dynamically altering the seed value or temperature as part of retry efforts, thereby compelling the agent to explore a different cognitive path.
Dynamic Parameter Adjustment:
Resilient agent architectures are not static; they implement sophisticated approaches that dynamically adjust these parameters based on the agent’s runtime state. For instance:
- Adaptive Temperature: If an agent is detected to be stuck in a repetitive loop (e.g., performing the same sequence of actions multiple times without progress), the system can temporarily raise the temperature. This increased randomness encourages the LLM to explore alternative reasoning paths and action sequences. Once the agent breaks free, the temperature can be reset to a more controlled level.
- Randomized Seed on Retry: A common and highly effective strategy is to randomize the seed value whenever a retry mechanism is triggered. This ensures that each subsequent attempt to resolve a problem starts with a fresh "cognitive slate," preventing the agent from falling into the same deterministic trap. The seed can be set to a new, truly random value, or derived from a time-based entropy source.
- Tiered Adjustment: A more advanced approach might involve tiered adjustments. For a first retry, a slightly randomized seed. For a second, a higher temperature. For a third, a combination, potentially even coupled with a different prompt strategy or external tool.
The Role of Cost-Effective Testing:
Implementing and validating these flexible, adaptive strategies is not trivial. Testing various temperature and seed combinations, especially under stress conditions, can become prohibitively expensive if relying solely on commercial LLM APIs, which charge per token. This economic reality makes the use of open-weight models, local models, and local model runners like Ollama absolutely critical.
- Open-Weight Models: Models like Llama, Mistral, or Falcon, which can be downloaded and run locally, provide a cost-free environment for extensive experimentation.
- Local Model Runners (e.g., Ollama): Tools like Ollama simplify the deployment and management of these open-source models on local hardware, making it feasible for developers to run thousands, even millions, of agentic loops to simulate failure scenarios. This allows for:
- Stress Testing: Running agents through diverse temperature and seed combinations under various failure conditions to identify thresholds and robust recovery strategies.
- Root Cause Analysis: Pinpointing exactly which parameter settings lead to specific types of reasoning failures before deployment.
- A/B Testing: Comparing the efficacy of different dynamic adjustment algorithms without incurring API costs.
By leveraging these cost-free tools, developers can iterate rapidly, discover the optimal balance between creativity and determinism, and fine-tune their agentic loop recovery mechanisms. This practical path to pre-deployment validation is indispensable for building truly resilient and cost-effective AI agents.
Broader Impact and Ethical Considerations
The quest for resilient agentic loops extends beyond mere technical optimization; it touches upon broader societal implications and ethical considerations. As AI agents gain more autonomy and are integrated into critical infrastructure, their failure modes—and our ability to mitigate them—become paramount.
- Safety and Trust: An agent that can reliably recover from unforeseen circumstances instills greater trust, especially in high-stakes domains like healthcare, autonomous vehicles, or financial trading. Unpredictable failures, conversely, can erode public confidence in AI.
- Ethical Decision-Making: When an agent exhibits reasoning drift, it might make decisions that deviate from its programmed ethical guidelines or intended purpose. Ensuring robust and predictable behavior through careful parameter tuning is a step towards more ethically aligned AI.
- Accountability: Understanding how temperature and seed values contribute to failure helps developers and organizations maintain accountability for their AI systems. It provides a clearer pathway for debugging, auditing, and explaining agent behavior.
The ongoing research into agent reliability, coupled with the strategic application of parameters like temperature and seed values, represents a crucial frontier in AI development. By embracing dynamic control and rigorous, cost-effective testing, the AI community can pave the way for a future where autonomous agents are not only intelligent but also robust, reliable, and truly resilient in the face of complexity and uncertainty. The meticulous management of these invisible steering mechanisms is not merely a technical detail; it is a foundational element for the responsible and successful deployment of AI agents across all sectors.