
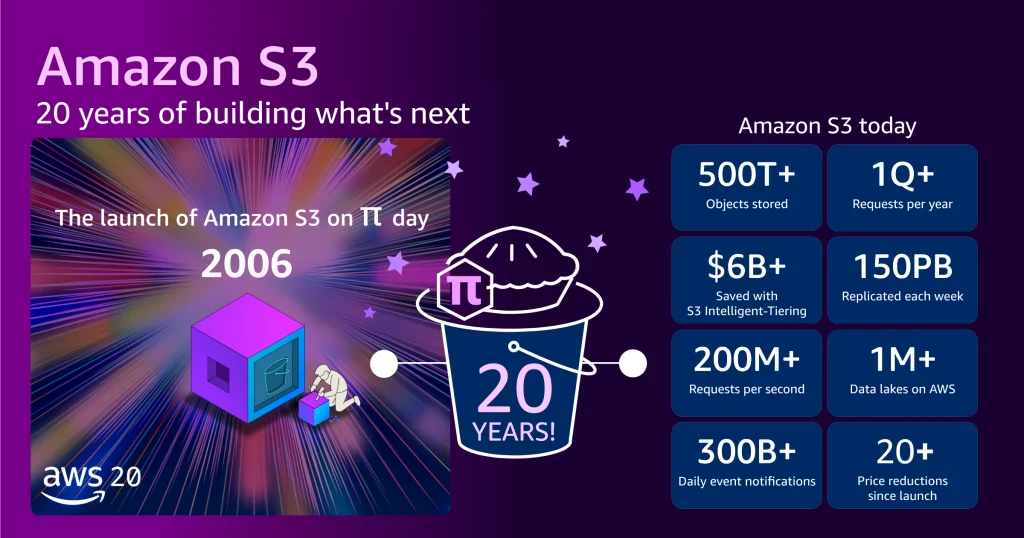
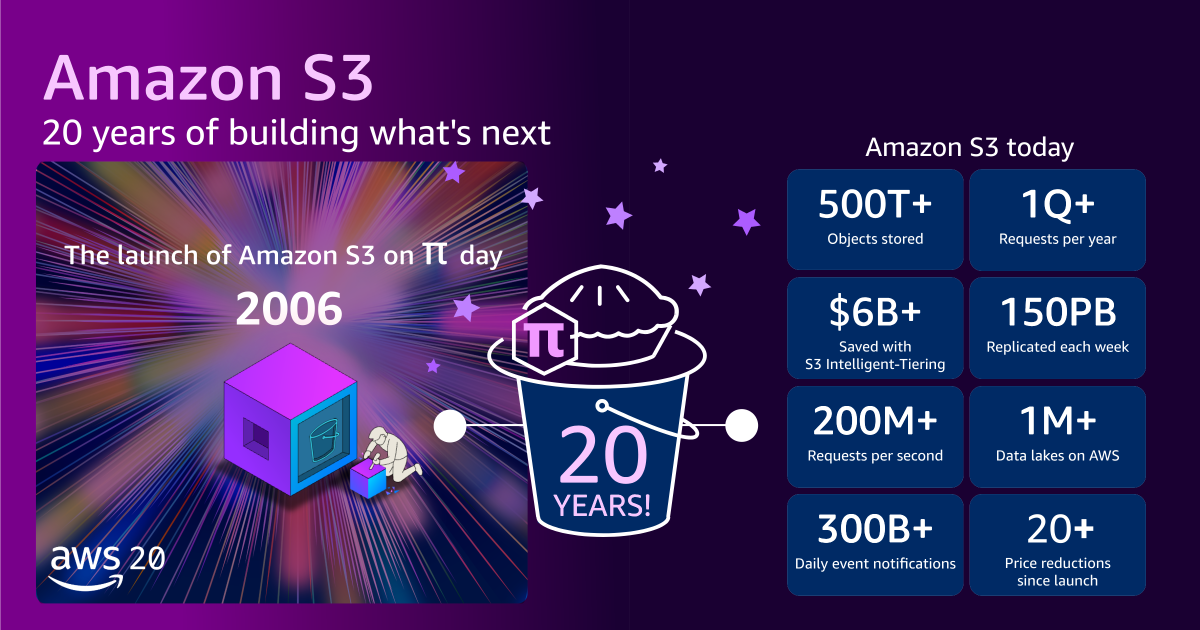
March 14, 2006, marked a pivotal, yet understated, moment in the history of cloud computing: the quiet launch of Amazon Simple Storage Service (Amazon S3). Introduced with a modest one-paragraph announcement on the AWS What’s New page, and a similarly brief blog post from Jeff Barr, S3’s debut lacked the fanfare typically associated with paradigm-shifting technologies. Few, if any, could have predicted that this seemingly simple "storage for the Internet" would fundamentally reshape the global digital landscape, democratizing access to enterprise-grade scalability and reliability for developers worldwide. Twenty years on, S3 stands not just as a foundational pillar of Amazon Web Services (AWS), but as a testament to the power of abstracting complex infrastructure, enabling an era of unprecedented innovation from startups to multinational corporations.
The Genesis of a Giant: A Look Back at 2006
Before the advent of cloud computing as we know it, developers and businesses faced significant hurdles in managing their data. Building and maintaining robust storage infrastructure required substantial upfront capital investment, specialized hardware, data center space, and dedicated engineering teams. Scaling storage up or down was a time-consuming and often prohibitive endeavor, leading to over-provisioning or critical capacity shortages. This "undifferentiated heavy lifting" diverted valuable resources and attention away from core business innovation.
It was into this challenging environment that Amazon S3 emerged. The initial announcement positioned it as a service "designed to make web-scale computing easier for developers," offering "a simple web services interface that can be used to store and retrieve any amount of data, at any time, from anywhere on the web." Crucially, it promised to grant "any developer access to the same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of web sites." This vision, articulated succinctly, was nothing short of revolutionary. It implied a future where storage was an on-demand utility, not a capital expenditure.
Foundational Principles: The Five Pillars of S3
From its inception, S3 was engineered around a set of five core fundamentals that have remained sacrosanct and unchanged over two decades, underpinning its enduring success and trustworthiness:
- Security: Data protection has always been paramount, with S3 designed to secure customer data by default through robust access controls, encryption options, and integration with AWS Identity and Access Management (IAM). This commitment ensures that customers retain granular control over who can access their information.
- Durability: Perhaps S3’s most celebrated attribute, durability is designed for 11 nines (99.999999999%). This extraordinary level of durability means that, on average, for every 10 million objects stored, one object might be lost once every 100,000 years. This is achieved through automatic replication of data across multiple devices and Availability Zones within an AWS Region, and continuous integrity checks. AWS’s operational philosophy ensures that S3 is effectively "lossless."
- Availability: Recognizing that failures are an inherent part of any large-scale distributed system, S3 is architected for high availability at every layer. This involves redundancy, automatic failover mechanisms, and resilient design patterns that ensure data is accessible when needed, even in the face of component outages.
- Performance: S3 is optimized to handle virtually any amount of data and any number of requests without degradation. Its architecture allows for massive parallelization of operations, ensuring consistent high performance for diverse workloads, from static website hosting to large-scale data analytics.
- Elasticity: The service epitomizes the "pay-as-you-go" cloud model. It automatically scales to accommodate growing data volumes and request rates, and conversely, shrinks when data is removed. This eliminates the need for manual provisioning or capacity planning, allowing developers to focus purely on their applications.
These principles, diligently applied and continuously refined, transformed storage from a significant infrastructure challenge into an invisible, reliable utility, freeing developers to innovate at an unprecedented pace.
From Petabytes to Exabytes: S3’s Unprecedented Scale
The journey from its modest beginnings to its current colossal scale is one of the most compelling narratives in cloud computing. At launch, S3 offered approximately one petabyte (PB) of total storage capacity, distributed across about 400 storage nodes in 15 racks spanning three data centers, with a total bandwidth of 15 Gbps. It was designed to store tens of billions of objects, each with a maximum size of 5 GB, at an initial price of 15 cents per gigabyte per month.
Today, S3’s metrics are staggering, reflecting an expansion that few could have envisioned:
- Objects Stored: More than 500 trillion objects, a monumental increase that underscores its role as the backbone for global data.
- Request Volume: It serves over 200 million requests per second globally, illustrating the sheer volume of data interactions it facilitates.
- Total Data Stored: Hundreds of exabytes (EB) of data, making it one of the largest and most widely used storage systems in the world.
- Geographic Reach: Deployed across 123 Availability Zones in 39 AWS Regions, ensuring low-latency access and data residency options for millions of customers across the globe.
- Object Size: The maximum object size has expanded from 5 GB to a staggering 50 TB, a 10,000-fold increase that accommodates increasingly large datasets prevalent in scientific research, media, and enterprise applications.
- Physical Scale: To put its physical footprint into perspective, if one were to stack all the tens of millions of hard drives comprising S3’s infrastructure, they would reach the International Space Station and almost back again, a truly mind-boggling scale of physical hardware managed as a single logical service.
Alongside this explosive growth in scale and capability, the economic value proposition of S3 has dramatically improved. The initial price of 15 cents per gigabyte has plummeted by approximately 85% over 20 years, with AWS now charging slightly over 2 cents per gigabyte for standard storage. Furthermore, the introduction of intelligent storage tiers like Amazon S3 Intelligent-Tiering has allowed customers to collectively save over $6 billion in storage costs compared to using standard storage, by automatically moving data to the most cost-effective access tier based on usage patterns. This combination of massive scale, continuous innovation, and aggressive price reductions has made high-performance, durable storage accessible to virtually any entity, regardless of budget or technical expertise.
The Engineering Marvel: Behind the Scenes of S3’s Reliability
The ability to operate S3 at such an extraordinary scale, while maintaining its five core fundamentals, is a testament to continuous, cutting-edge engineering innovation. Insights into this engineering prowess often emerge from detailed technical discussions, such as the interview between Mai-Lan Tomsen Bukovec, VP of Data and Analytics at AWS, and Gergely Orosz of The Pragmatic Engineer.
At the heart of S3’s legendary durability is a sophisticated system of microservices that relentlessly inspect every single byte across the entire storage fleet. These "auditor services" continuously monitor data integrity, detecting even the slightest signs of degradation. The moment an anomaly is detected, automated repair systems are triggered, initiating re-replication or other corrective actions to ensure data consistency and prevent loss. This proactive, self-healing architecture is critical to achieving the 11 nines of durability, sizing the replication and re-replication fleet to ensure objects are not lost.
AWS engineers also employ highly advanced techniques, including formal methods and automated reasoning, to mathematically prove the correctness of critical S3 components in production. For instance, when new code is introduced to the index subsystem, automated proofs verify that consistency properties have not regressed. This rigorous approach is also applied to validate complex features like cross-Region replication and intricate access policies, ensuring that the system behaves exactly as intended under all circumstances, a critical safeguard when dealing with hundreds of exabytes of customer data.
A significant engineering shift over the past eight years has been the progressive rewriting of performance-critical code in the S3 request path using Rust. Components responsible for blob movement and disk storage have already been rewritten, with work actively ongoing across other core modules. Beyond the raw performance gains, Rust’s robust type system and memory safety guarantees eliminate entire classes of bugs at compile time. This is an invaluable property for a service operating at S3’s scale and with its stringent correctness requirements, significantly enhancing stability and reducing the likelihood of runtime errors.
S3’s engineering is also guided by a counter-intuitive yet powerful design philosophy: "Scale is to your advantage." This means systems are designed such that increased scale inherently improves attributes for all users. For S3, this translates into greater de-correlation of workloads as the system grows larger, which in turn enhances overall reliability for every customer. The sheer volume of operations allows for statistical smoothing of individual component failures, making the aggregate system more robust.
A Universal API: Setting Industry Standards
Beyond its internal engineering marvels, S3’s external impact is equally profound, particularly through its API. The Amazon S3 API has become a de facto industry standard, widely adopted and used as a reference point across the storage industry. Numerous vendors now offer S3-compatible storage tools, systems, and even on-premises solutions, all implementing the same API patterns and conventions.
This widespread adoption has had several crucial implications:
- Skill Transferability: Developers and administrators who learn to work with S3 can easily transfer their skills and tools to other S3-compatible storage systems, making the broader storage landscape more accessible and reducing training overhead.
- Ecosystem Development: A rich ecosystem of third-party tools, libraries, and applications has emerged around the S3 API, further enhancing its utility and interoperability.
- Competition and Innovation: The standardization provided by the S3 API has fostered competition and innovation, as vendors strive to offer better performance, features, or cost-effectiveness while maintaining compatibility.
- Vendor Lock-in Mitigation: While using a cloud provider often implies a degree of lock-in, the S3 API’s widespread adoption offers a pathway for data mobility and architectural flexibility, reducing concerns for many organizations.
The fact that code written for S3 in 2006 still works today, unchanged, is perhaps one of its most remarkable achievements and a cornerstone of its commitment to "just works" reliability. This backward compatibility across two decades of infrastructure migrations, re-architectures, and code rewrites—while preserving data integrity and accessibility—is a testament to a deep-seated engineering discipline focused on long-term customer value.
Beyond Storage: S3 as the Data and AI Foundation
Looking forward, the vision for S3 extends far beyond merely being a highly reliable storage service. It is increasingly positioned as the universal foundation for all data and AI workloads. The underlying philosophy is simple yet powerful: store any type of data once in S3, and then work with it directly, without the costly and complex necessity of moving data between specialized systems. This approach dramatically reduces costs, eliminates data duplication, simplifies architectures, and accelerates time to insight.
In recent years, AWS has continuously launched new capabilities that solidify S3’s role as an active data platform:
- Data Lakes and Analytics: S3 has become the primary storage layer for data lakes, enabling customers to store vast amounts of structured and unstructured data for analytics, business intelligence, and machine learning. Services like Amazon Athena, Amazon Redshift Spectrum, and AWS Glue integrate directly with S3, allowing for powerful querying and processing of data in place.
- Hybrid Cloud and Edge: S3 Outposts and AWS Storage Gateway extend S3 capabilities to on-premises environments and edge locations, enabling consistent storage management and hybrid architectures.
- Advanced Data Management: Features like S3 Object Lock for immutable storage, S3 Batch Operations for large-scale data manipulation, and robust lifecycle policies empower customers with sophisticated data governance and cost optimization.
- AI/ML Integration: S3 is the go-to repository for training data for machine learning models, and for storing model artifacts and inference results. Its seamless integration with services like Amazon SageMaker, Amazon Rekognition, and Amazon Comprehend underscores its central role in the AI/ML pipeline.
These capabilities, built atop S3’s cost-effective structure, allow organizations to handle diverse data types and complex workloads that traditionally required expensive databases or specialized systems. The economic feasibility of managing and processing massive datasets directly within S3 has been a game-changer for big data and AI adoption.
Economic and Innovation Impact
The impact of Amazon S3 on the global economy and the pace of innovation is immeasurable. By abstracting the complexities of storage, S3 effectively democratized access to enterprise-grade infrastructure. This had several profound effects:
- Reduced Barrier to Entry: Startups and small businesses could now access world-class storage without significant capital outlay, lowering the barrier to entry for new ventures and fostering a boom in cloud-native applications.
- Accelerated Innovation: Developers could focus on building applications and solving business problems rather than managing servers, leading to faster development cycles and rapid experimentation.
- New Business Models: S3 enabled entirely new business models that rely on massive data storage and processing, from streaming services and social media platforms to genomics research and autonomous vehicle development.
- IT Cost Transformation: For established enterprises, S3 offered a pathway to dramatically reduce IT operational costs, shift from CapEx to OpEx, and gain unprecedented agility.
From its humble launch of 1 petabyte at 15 cents per gigabyte, to managing hundreds of exabytes at a fraction of the cost, and evolving from simple object storage to the universal foundation for AI and analytics, Amazon S3’s journey over the past 20 years is a testament to relentless innovation driven by a customer-centric philosophy. Its enduring commitment to security, durability, availability, performance, and elasticity—all while maintaining backward compatibility for code written decades ago—ensures its continued relevance and pivotal role in shaping the future of digital infrastructure. Here’s to the next 20 years of innovation on Amazon S3.
