
The ubiquitous integration of advanced AI chatbots, exemplified by platforms such as Claude, ChatGPT, and Gemini, has fundamentally transformed information retrieval and task execution across various sectors. While these sophisticated tools offer unparalleled assistance in synthesizing vast datasets and generating comprehensive responses, their inherent design presents a significant challenge: the potential for "hallucinations," or the generation of factually incorrect yet confidently presented information. This risk underscores a critical need for strategies that ensure the reliability of AI-generated content, particularly when such content forms the basis of critical work or decision-making. The practice of "grounding" an AI chatbot within a user’s specific, verified documentation emerges as a robust solution to mitigate this risk, ensuring that the AI operates strictly within controlled and reliable informational parameters.
Understanding the Challenge: The AI Hallucination Phenomenon
Artificial intelligence hallucinations refer to instances where a large language model (LLM) generates information that is plausible-sounding but factually incorrect or unsupported by its training data. Unlike human error, AI hallucinations are not deliberate deceptions but rather an emergent property of the models’ probabilistic nature and their architecture. LLMs are trained on vast datasets to predict the next most probable word or sequence of words, creating coherent and contextually relevant text. However, this predictive capability does not equate to genuine understanding or a direct link to factual accuracy.
Several factors contribute to this phenomenon:
- Training Data Limitations: Despite massive datasets, an LLM’s knowledge is finite and frozen at the time of its last training update. It cannot access real-time information or specific niche details unless explicitly provided.
- Lack of Real-World Understanding: LLMs lack true comprehension of the physical world, cause-and-effect relationships, or human intent. Their "knowledge" is statistical pattern recognition.
- Confabulation: When confronted with a query for which it has no direct answer, an LLM may attempt to "fill in the gaps" by generating plausible but fabricated information based on patterns observed in its training data.
- Over-Generalization: The model might over-generalize from partial information, leading to incorrect conclusions when applied to specific contexts.
- Ambiguous Prompts: Vague or poorly constructed prompts can lead the AI to misinterpret the user’s intent, resulting in irrelevant or incorrect outputs.
The implications of AI hallucinations are far-reaching. In academic research, they can lead to spurious findings; in legal contexts, incorrect precedents; in medical applications, dangerous advice; and in business, flawed strategic decisions. The absence of visible source citations, a common characteristic of general-purpose chatbots, exacerbates this problem, making independent verification a time-consuming and often overlooked step. This necessitates a proactive approach to AI deployment, shifting from mere information generation to verified information synthesis.
The Solution: Grounding AI with Retrieval-Augmented Generation (RAG)
To counteract the inherent risks of AI hallucinations and enhance the factual integrity of chatbot responses, the concept of "grounding" or "enclosing" an AI within a defined set of trusted documents has become paramount. Technically, this process is often implemented through a framework known as Retrieval-Augmented Generation (RAG).
RAG combines the strengths of information retrieval systems with the generative power of LLMs. Instead of relying solely on its pre-trained internal knowledge, an RAG-enabled system first retrieves relevant information from a specified external knowledge base (the "grounding documents") in response to a user query. This retrieved information is then provided to the LLM as additional context, allowing the model to generate a response that is directly informed by and constrained by the factual content of the external documents.
The operational mechanism of RAG typically involves:
- Document Ingestion and Indexing: User-provided documents (PDFs, text files, web pages, databases) are processed, chunked into smaller, manageable segments, and converted into numerical representations (embeddings). These embeddings are then stored in a vector database, enabling efficient semantic search.
- Query Processing: When a user submits a query, it is also converted into an embedding.
- Retrieval: The query embedding is used to search the vector database for the most semantically similar document chunks.
- Augmentation and Generation: The retrieved document chunks are then concatenated with the original user query and fed into the LLM as an extended prompt. The LLM then generates its response based only on this augmented context, effectively "grounding" its output in the provided information.
The benefits of implementing RAG are substantial:
- Enhanced Factual Accuracy: By restricting the AI’s knowledge domain, RAG significantly reduces the likelihood of hallucinations, ensuring responses are directly supported by verifiable sources.
- Traceability and Transparency: RAG allows for the direct citation of source documents or specific passages, enabling users to verify the information independently.
- Domain-Specific Knowledge: Organizations can imbue general-purpose LLMs with their proprietary, up-to-date, and highly specific knowledge, making the AI invaluable for specialized tasks.
- Reduced Training Costs: Instead of continuously retraining large LLMs with new information, RAG allows for dynamic updates to the external knowledge base, which is far more cost-effective and agile.
- Improved Relevance: Responses are more tailored and relevant to the user’s specific informational needs, as they draw from a targeted corpus.
Despite its advantages, RAG implementation requires careful attention to the quality and organization of the source documents. Poorly structured, contradictory, or incomplete documentation can still lead to suboptimal or erroneous outputs.
Practical Implementation: Leveraging Chatbots for Document-Specific Tasks
The increasing sophistication of AI platforms has made RAG-like capabilities accessible to a broader user base, moving beyond complex enterprise deployments to user-friendly interfaces. Platforms like Claude, ChatGPT, and Gemini now offer features that allow users to upload their own documents and instruct the AI to reference these exclusively.
Claude: A Preferred Tool for Controlled Information Retrieval
Among the current generation of AI chatbots, Claude, developed by Anthropic, has garnered significant attention for its capabilities in handling extensive contexts and generating coherent, detailed responses. Many users, based on extensive practical experience, often express a preference for Claude when tasks demand meticulous documentation organization and the generation of concrete, elaborated answers. While acknowledging that no AI is entirely infallible and instances of "confabulation" can still occur, Claude’s architecture is frequently cited for its perceived reliability and structured output.
Claude’s robust context window allows users to upload a substantial volume of information—including multiple documents, links, photos, and PDFs—and instruct the model to base its responses solely on this provided data. This feature is particularly valuable for complex research, report generation, or internal knowledge management where adherence to specific source material is non-negotiable. The platform’s ability to process and synthesize information from diverse document types makes it a versatile tool for creating bespoke knowledge agents.
Step-by-Step Guide: Creating a Document-Grounded Project with Claude
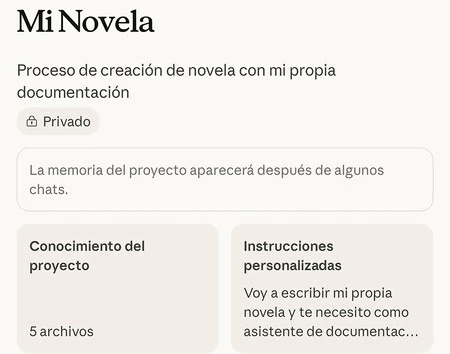
For optimal organization and consistent performance, it is highly recommended to centralize document-based AI interactions within a dedicated "project" rather than relying on ephemeral chat sessions. This structured approach helps maintain context, track progress, and prevent information from being lost amidst a proliferation of open chats.
Here’s a generalized process for establishing a document-grounded project with Claude:
- Initiate a New Project: Within the Claude interface, navigate to the option for creating a new project or a new conversation specifically designed for document upload. This ensures a clean slate and dedicated environment for your task.
- Upload Your Documentation: Upload all relevant source materials. This can include:
- PDFs: Research papers, reports, manuals, legal documents.
- Text Files: Meeting notes, articles, proprietary data.
- Web Links: URLs to specific articles, company websites, or online databases.
- Images/Photos: Diagrams, charts, or visual data that can be interpreted by the AI (though interpretation accuracy for complex visuals may vary).
- Formulate a Clear Directive Prompt: The crucial step is to explicitly instruct Claude to confine its responses to the uploaded documents. A highly effective prompt, as recommended by experienced users, is:
"You must base your responses only on the documentation I have uploaded. Optionally, I can ask you to search elsewhere, do so only at my request."
This prompt establishes a clear boundary, making the AI’s "knowledge base" explicitly defined. The optional clause retains flexibility should external verification or additional context be required later. - Begin Interaction and Task Execution: Once the documents are uploaded and the directive prompt is issued, all subsequent conversations within that project will ideally be grounded in the provided information. Users can then ask specific questions, request summaries, compare data points, or generate content, confident that the AI’s output is derived from controlled sources.
- Continuous Verification: Despite explicit instructions, it is imperative to maintain a regimen of periodic verification. AI models, even when grounded, can occasionally "derail" or make inferences that subtly stray from the precise wording of the source material. Users should routinely cross-reference key facts and figures against the original documents to ensure unwavering fidelity to the provided data. This "human-in-the-loop" validation remains a critical component of responsible AI utilization.
Expanding the Horizon: ChatGPT, Gemini, and Custom AI Agents
While Claude is a strong contender for document-grounded tasks, other leading AI platforms also offer comparable functionalities, albeit with slight variations in implementation and accessibility.
ChatGPT and Custom GPTs: OpenAI’s ChatGPT, particularly its Plus subscription tier, allows users to create "Custom GPTs." These are personalized versions of ChatGPT that can be configured with specific instructions, capabilities, and, crucially, access to user-uploaded files or knowledge bases. Users can upload documents (similar to Claude) and define the GPT’s behavior, including instructions to strictly adhere to the provided information. Custom GPTs offer a powerful way to create tailored AI assistants for niche applications, research, or internal company knowledge. However, the creation and use of Custom GPTs generally require a paid subscription to ChatGPT Plus.
Gemini and Gems: Google’s Gemini platform introduces a feature called "Gems." These are custom versions of Gemini designed for specific purposes, much like ChatGPT’s Custom GPTs. Users can create Gems and upload their own documentation, instructing the AI to draw solely from these sources. A significant advantage of Gemini’s Gems is that the creation of these personalized agents is often available in the free tier of Gemini, making document-grounded AI more accessible to a broader audience. The process for interacting with a Gem is straightforward: simply select the custom agent from your list of Gems/GPTs and begin your query, knowing it will operate within the predefined document constraints.
In both Gemini and ChatGPT, the principle remains the same: define the AI’s operational boundaries through instructions and document uploads, and then periodically audit its responses for accuracy and adherence to those boundaries. While "hallucinations" in these grounded contexts are less common, the possibility, however remote, necessitates ongoing human oversight.
The Broader Impact: Transforming Information Workflows and Ensuring Accuracy
The ability to "ground" AI chatbots in specific documentation represents a paradigm shift in how individuals and organizations can leverage artificial intelligence.

- Enhanced Research and Analysis: Researchers can feed vast quantities of academic papers, clinical trials, or market reports into an AI and quickly extract precise answers, synthesize findings, or identify trends, knowing the source material is explicitly referenced.
- Streamlined Legal and Compliance Workflows: Legal professionals can use AI to analyze contracts, precedents, and regulatory documents, generating summaries or identifying clauses without the risk of the AI inventing legal interpretations.
- Empowered Customer Support: Companies can train AI chatbots on their comprehensive knowledge bases, FAQs, and product manuals to provide accurate and consistent customer support, reducing the burden on human agents and improving customer satisfaction.
- Efficient Internal Knowledge Management: Organizations can create internal AI agents that are experts on their proprietary data, internal policies, project documentation, and employee handbooks, facilitating quick access to information for employees.
- Personalized Learning and Education: Students and educators can create AI tutors grounded in specific textbooks or curricula, offering targeted explanations and exercises.
This controlled application of AI is not merely about automation; it is about intelligent augmentation. It frees human experts from the laborious task of sifting through mountains of information, allowing them to focus on critical thinking, strategic decision-making, and creative problem-solving.
Best Practices for Maximizing AI Accuracy and Reliability
To fully harness the power of grounded AI while minimizing risks, several best practices should be observed:
- Curate High-Quality Documentation: The accuracy of the AI’s output is directly proportional to the quality of the input documents. Ensure that source materials are accurate, up-to-date, consistent, and well-structured. Remove redundancies or contradictory information before uploading.
- Precise Prompt Engineering: Craft clear, unambiguous instructions for the AI. Explicitly state the desired behavior and constraints, as demonstrated by the "base your responses only on my documents" prompt.
- Iterative Refinement: Treat the AI’s knowledge base as a living entity. Continuously update and refine your uploaded documents as new information becomes available or as your needs evolve.
- Segment and Organize: For large projects, consider segmenting your documentation into logical categories or sub-projects. This can help the AI focus on specific domains and improve retrieval accuracy.
- Human Oversight and Validation: Always maintain a "human-in-the-loop" approach. Periodically review the AI’s responses, especially for critical information, to ensure fidelity to the source documents. This is the ultimate safeguard against subtle deviations or errors.
- Understand AI Limitations: Recognize that even grounded AI is a tool. It excels at information synthesis but does not possess human intuition, ethical reasoning, or real-world judgment. Complex tasks requiring nuanced interpretation or creative leaps still necessitate human expertise.
- Security and Privacy: Exercise caution when uploading sensitive or confidential documents. Ensure that the AI platform adheres to robust data security and privacy protocols, and understand how your data is handled.
The Evolving Landscape of AI Trust and Verification
The journey from initial AI hype to a more nuanced understanding of its capabilities and limitations has highlighted the critical importance of trust and verification. Industry leaders and developers are increasingly focused on building more transparent and controllable AI systems. Features like RAG, custom agents, and explicit grounding mechanisms are direct responses to the demand for reliable AI outputs.
The evolution of AI from a general-purpose knowledge engine to a personalized, document-specific assistant marks a significant step towards practical and responsible AI integration. It empowers users to tailor AI to their precise needs, transforming it from a potentially unreliable oracle into a highly accurate, context-aware expert. As AI continues to advance, the emphasis will remain on developing tools that not only generate information efficiently but also do so with unwavering accuracy and verifiable integrity. The future of AI is not just about intelligence, but about intelligent, trustworthy assistance.
Images: Iván Linares
Further Reading: Xataka Móvil | Preguntarle a la IA fue el primer paso, y creíamos que tardaría en controlar el teléfono. Gemini acaba de demostrar lo contrario
