
Amazon Web Services (AWS) today announced the general availability of custom Nova model support in Amazon SageMaker Inference, marking a significant advancement in empowering enterprises to deploy and scale their specialized AI models with unprecedented control, flexibility, and cost efficiency. This new offering extends the capabilities previously introduced for Amazon Nova customization in Amazon SageMaker AI at the AWS NY Summit 2025, directly addressing customer demand for the same level of granular control over proprietary Nova models as they enjoy with open-weights models within SageMaker Inference. The update empowers organizations to fine-tune and deploy Nova Micro, Nova Lite, and Nova 2 Lite models, integrating advanced reasoning capabilities into their critical business operations.
Unlocking Enterprise AI: A New Era of Customization
The landscape of artificial intelligence is rapidly evolving, with enterprises increasingly recognizing the transformative potential of large language models (LLMs). However, generic, off-the-shelf models often fall short in addressing the nuanced, domain-specific requirements of various industries. This gap has fueled a growing demand for customization, allowing businesses to adapt powerful foundation models to their unique datasets, operational workflows, and specific use cases. Amazon Nova, AWS’s proprietary family of AI models, represents a foundational layer for many such enterprise applications. The initial launch of Nova customization focused on the training aspect, providing the tools necessary to adapt these models. Today’s announcement closes the loop, offering a robust, production-grade inference service that supports these highly tailored models.
The move by AWS reflects a broader industry trend towards democratizing advanced AI capabilities, making them accessible and practical for a wider array of businesses. By providing managed inference services, AWS aims to lower the operational burden of deploying and scaling complex AI models, allowing organizations to focus on innovation rather than infrastructure management. This is particularly crucial for LLMs, which demand significant computational resources for both training and inference. The ability to customize models like Nova and then deploy them seamlessly within a managed environment like SageMaker Inference is a critical enabler for accelerating AI adoption across diverse sectors, from financial services and healthcare to manufacturing and retail.
A Phased Rollout: The Journey to Full Customization
The general availability of custom Nova model support in SageMaker Inference is the culmination of a strategic, phased approach by AWS to build out a comprehensive ecosystem for enterprise-grade AI. The journey began at the AWS NY Summit 2025, where AWS first unveiled Amazon Nova customization in Amazon SageMaker AI. This initial announcement focused on empowering developers and data scientists to fine-tune Nova models, enabling them to imbue these powerful models with specialized knowledge and behaviors relevant to their specific business contexts. This was a foundational step, recognizing that effective AI often requires more than just a powerful base model; it necessitates deep integration with an organization’s unique data and objectives.
Following this, AWS further enhanced its offerings at AWS re:Invent 2025 with the introduction of new serverless customization in Amazon SageMaker AI. This feature simplified the fine-tuning process for popular AI models, including Nova models, by abstracting away much of the underlying infrastructure complexity. With a few clicks, users could select a model, choose a customization technique, and handle model evaluation and deployment in a streamlined, serverless fashion. While revolutionary for ease of use, customers operating complex production environments expressed a continued desire for more granular control over the inference stage, particularly regarding resource allocation and optimization.

Today’s announcement directly addresses this feedback, providing the general availability of custom Nova model support in Amazon SageMaker Inference. This represents the final, critical piece of the puzzle, offering a production-grade, configurable, and cost-efficient managed inference service. It allows enterprises to move beyond the training and fine-tuning phases directly into scalable, real-world deployment. The chronology illustrates AWS’s methodical approach: first, enabling the creation of custom Nova models, then simplifying that creation process, and finally, delivering the robust deployment infrastructure required for production use cases. This progression ensures that organizations have a complete, integrated workflow from model development to high-scale inference.
Enhanced Control and Cost Efficiency for Production Workloads
A primary driver behind this new offering is the demand for greater control and flexibility in custom model inference, mirroring the capabilities available for open-weights models. Enterprises running production AI workloads require precise management over instance types, auto-scaling policies, context length, and concurrency settings to optimize for performance, reliability, and cost. SageMaker Inference for custom Nova models delivers on these critical requirements.
One of the most significant benefits is the reduction in inference cost through optimized GPU utilization. The service now supports Amazon Elastic Compute Cloud (Amazon EC2) G5 and G6 instances, which are specifically designed with NVIDIA GPUs optimized for machine learning inference. These newer generation instances often offer a more favorable price-performance ratio for inference tasks compared to the P5 instances, which are typically geared towards heavy training workloads. For example, G5 instances, powered by NVIDIA A10G Tensor Core GPUs, provide excellent cost-effectiveness for a wide range of AI inference workloads, while G6 instances, featuring NVIDIA L4 GPUs, further push the boundaries of performance efficiency. By leveraging these optimized instances, businesses can achieve substantial cost savings, potentially reducing inference expenses by 20-40% or more depending on the workload characteristics, compared to less specialized hardware. This economic advantage is crucial for scaling AI initiatives, as inference costs can quickly accumulate, especially with high-volume usage.
Dynamic auto-scaling based on 5-minute usage patterns is another key feature designed for production efficiency. Traditional auto-scaling mechanisms might react slower, leading to either over-provisioning (and wasted costs during low demand) or under-provisioning (and performance bottlenecks during demand spikes). SageMaker Inference’s ability to scale based on granular 5-minute usage patterns allows for much more responsive and efficient resource allocation. This ensures that compute resources are precisely matched to the incoming request load, minimizing idle capacity while maintaining low latency and high availability. For businesses with fluctuating AI inference demands, this intelligent auto-scaling translates directly into significant cost savings and improved user experience.
Furthermore, the service offers configurable inference parameters, allowing advanced control over critical aspects such as context length, concurrency, and batch size.
- Context length refers to the maximum input size a model can process, directly impacting the complexity and detail of queries an AI can handle. Configuring this allows users to balance between computational cost and the depth of information processing required for their specific use cases.
- Concurrency dictates how many requests an instance can process simultaneously. Optimizing concurrency is vital for maximizing throughput and minimizing latency, especially in high-traffic applications.
- Batch size determines how many inference requests are processed together. Larger batch sizes can improve GPU utilization and throughput but may increase latency.
These parameters enable developers and MLOps engineers to finely tune the latency-cost-accuracy tradeoff for their specific workloads, ensuring that their customized Nova models perform optimally under various operational constraints. This level of configurability is paramount for deploying AI models in diverse enterprise environments where requirements can vary dramatically.

From Training to Deployment: A Seamless Workflow
The general availability of SageMaker Inference for custom Nova models completes an end-to-end customization journey. This journey begins with the training of Nova Micro, Nova Lite, and Nova 2 Lite models, all equipped with advanced reasoning capabilities. Customers can leverage Amazon SageMaker Training Jobs for robust, scalable model training, or opt for Amazon HyperPod for distributed training of large models, which offers even greater efficiency for complex, multi-GPU training workloads.
The supported Nova models—Micro, Lite, and 2 Lite—cater to different performance and resource requirements, allowing enterprises to choose the model size best suited for their specific application. The emphasis on "reasoning capabilities" highlights the models’ capacity to go beyond simple pattern recognition, enabling them to understand context, draw inferences, and engage in more complex problem-solving. This is particularly valuable for enterprise applications requiring nuanced decision support, sophisticated data analysis, or intelligent automation.
Customization techniques supported include:
- Continued pre-training: Extending the model’s knowledge base with proprietary data before fine-tuning, allowing it to learn domain-specific vocabulary and concepts.
- Supervised fine-tuning (SFT): Training the model on labeled datasets to teach it specific tasks or behaviors, such as answering questions in a particular style or summarizing documents.
- Reinforcement fine-tuning (RFT): Using reinforcement learning to further refine the model’s outputs based on human feedback or specific metrics, ensuring alignment with desired outcomes and safety guidelines.
These powerful techniques, combined with SageMaker’s managed training infrastructure, enable organizations to create highly specialized Nova models that are deeply integrated with their business logic and data. The seamless transition from these advanced training environments to SageMaker Inference for deployment drastically reduces the complexity and time-to-market for custom AI solutions.
Deployment Pathways: Studio and SDK
AWS offers flexible deployment pathways for customized Nova models, catering to different user preferences and operational requirements.
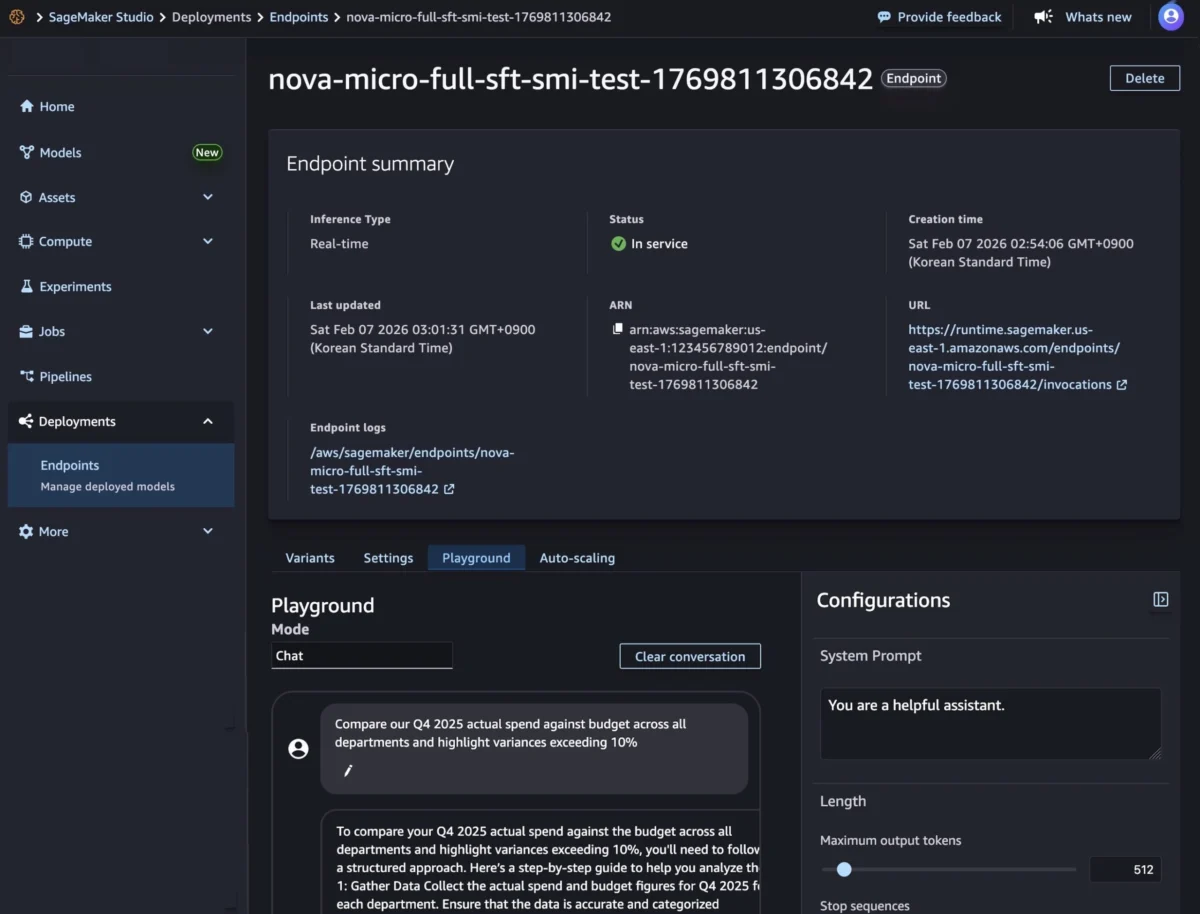
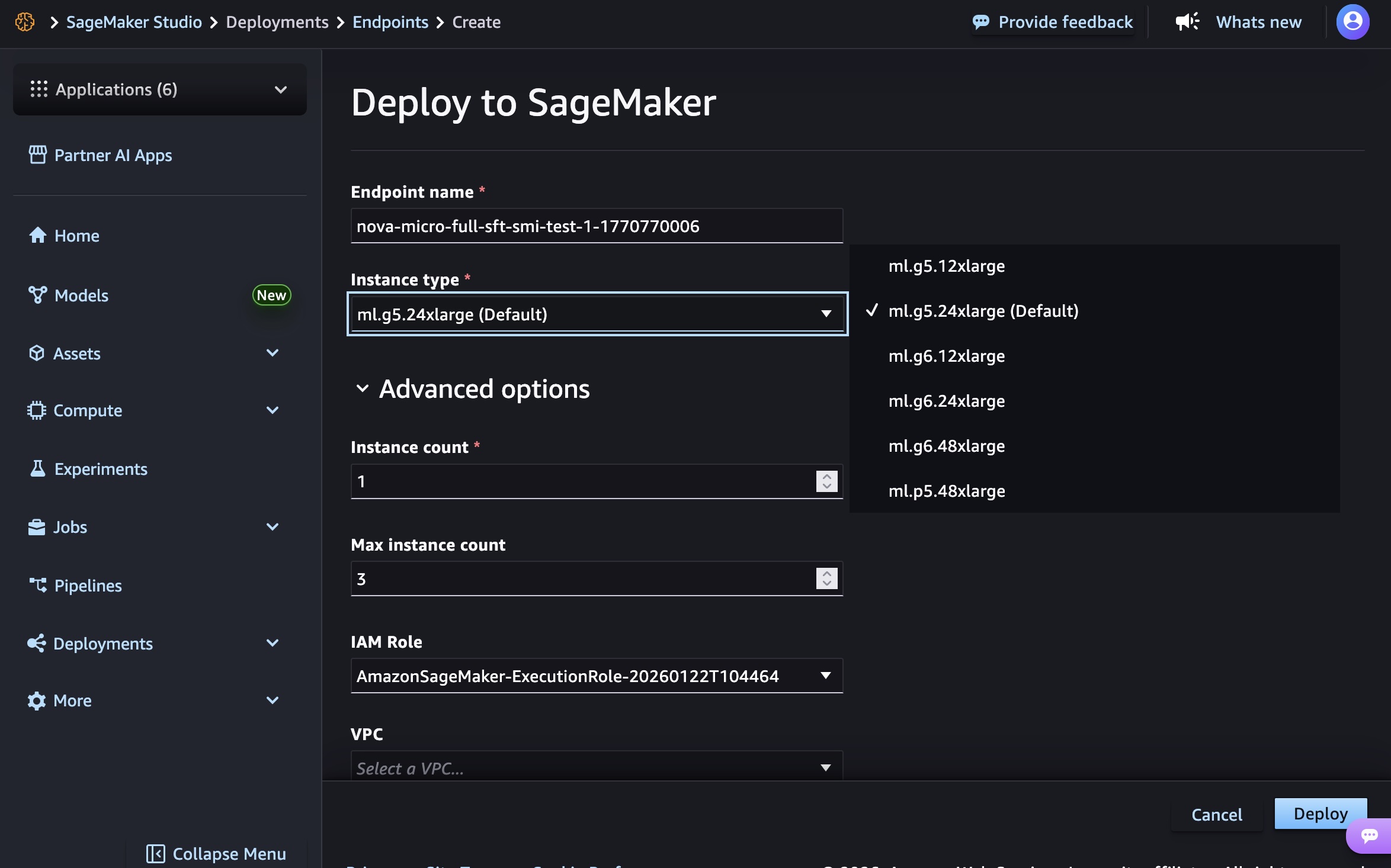
For users who prefer a graphical interface, SageMaker Studio provides an intuitive, click-through experience. As demonstrated, after a custom Nova model artifact has been trained and registered, users can navigate to the "Models" menu, select their trained Nova model, and initiate deployment. The process involves choosing the "Deploy" button, specifying "SageMaker AI," and selecting "Create new endpoint." Within this interface, users define the endpoint name, select the desired instance type (e.g., g5.12xlarge, g6.48xlarge, p5.48xlarge depending on the Nova model size), and configure advanced options such as initial and maximum instance counts, permissions, and networking settings. This streamlined approach makes model deployment accessible even to those with less extensive MLOps experience, fostering faster iteration and experimentation.
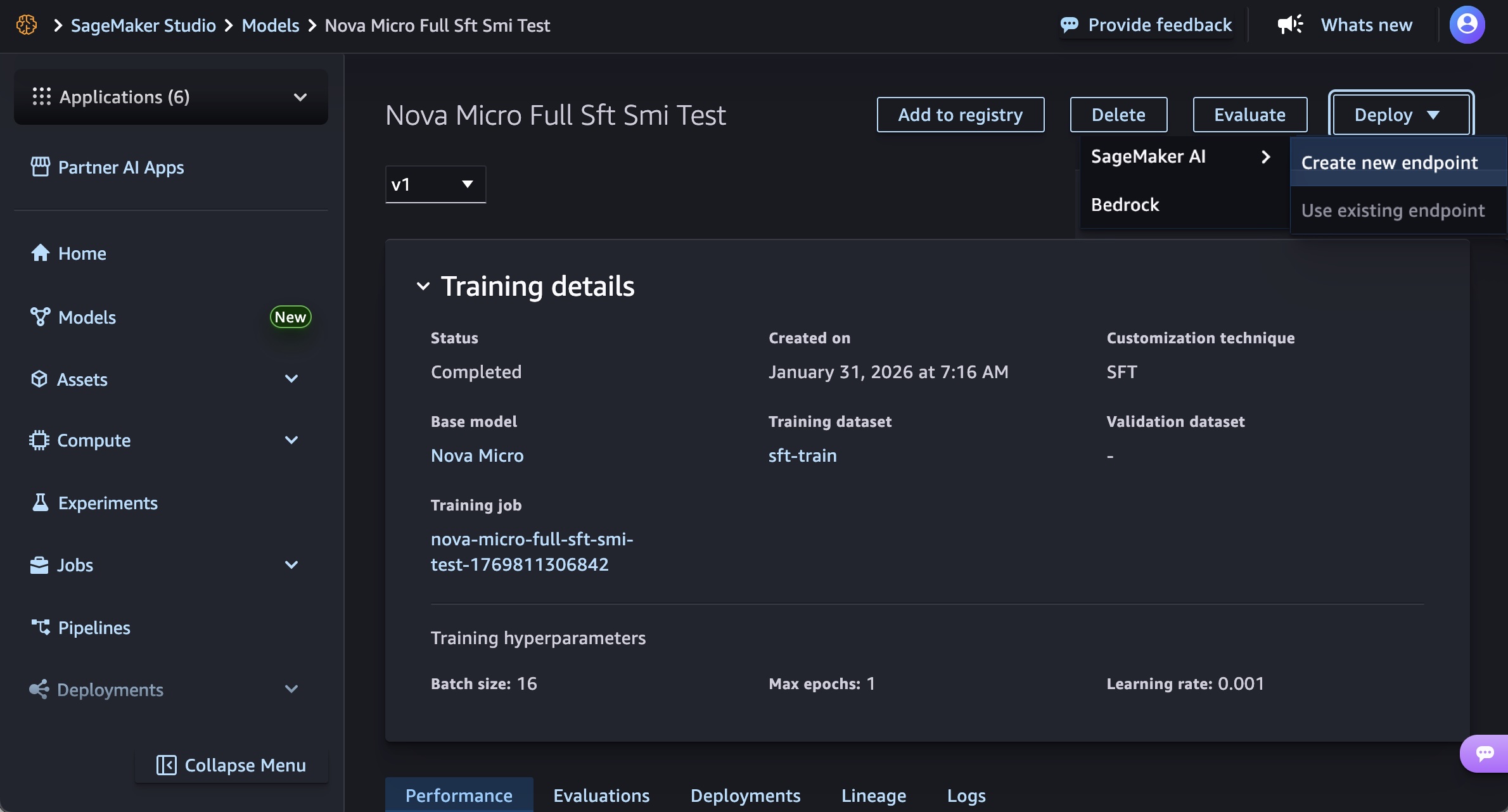
For developers and MLOps teams requiring programmatic control, automation, and integration into CI/CD pipelines, the SageMaker AI SDK offers a robust alternative. This method allows users to create SageMaker AI model objects that reference their Nova model artifacts, define endpoint configurations, and deploy real-time endpoints through code. The SDK provides granular control over all deployment parameters, from container images (which are region-specific and managed by AWS) to environment variables that dictate model behavior during inference (e.g., CONTEXT_LENGTH, MAX_CONCURRENCY, DEFAULT_TEMPERATURE). This programmatic approach is essential for large-scale deployments, managing multiple model versions, and implementing sophisticated deployment strategies.
At launch, specific instance types are supported for different Nova models to ensure optimal performance and cost efficiency:
- Nova Micro model:
g5.12xlarge,g5.24xlarge,g5.48xlarge,g6.12xlarge,g6.24xlarge,g6.48xlarge, andp5.48xlarge. - Nova Lite model:
g5.48xlarge,g6.48xlarge, andp5.48xlarge. - Nova 2 Lite model:
p5.48xlarge.
Once an endpoint is in an "InService" state, it is ready for real-time inference. Users can test the model directly within the SageMaker Studio Playground, using a chat interface to input prompts and observe responses. The SDK also facilitates invocation, supporting both synchronous endpoints for real-time inference (with streaming and non-streaming modes) and asynchronous endpoints for batch processing. This versatility ensures that customized Nova models can be integrated into a wide range of applications, from interactive chatbots to large-scale data analysis pipelines.
Strategic Availability and Economic Implications
The initial general availability of Amazon SageMaker Inference for custom Nova models is in the US East (N. Virginia) and US West (Oregon) AWS Regions. This strategic rollout prioritizes regions with high customer density and established AWS infrastructure, often serving as launchpads for new services before broader global expansion. These regions are central to many enterprises’ cloud strategies, ensuring that a significant portion of the AWS customer base can immediately benefit from the new capabilities. AWS has indicated a future roadmap for expanding regional availability, which will be accessible via the AWS Capabilities by Region page.
Economically, the new offering adheres to AWS’s commitment to flexible, transparent pricing. Customers pay only for the compute instances they use, with per-hour billing and no minimum commitments. This pay-as-you-go model is highly advantageous for enterprises, especially those experimenting with AI or managing workloads with fluctuating demands. It eliminates the need for large upfront investments in hardware and reduces the financial risk associated with deploying advanced AI models. The cost efficiencies gained through optimized GPU utilization on G5 and G6 instances, combined with intelligent auto-scaling, are expected to significantly lower the total cost of ownership for AI initiatives, making sophisticated custom Nova models more accessible to a broader range of businesses.
Industry Reactions and Future Outlook
The general availability of custom Nova model support in Amazon SageMaker Inference is expected to be met with strong positive reactions from the enterprise AI community. Customers have consistently vocalized their need for greater control and cost-effectiveness in deploying customized LLMs. This announcement directly addresses those concerns, solidifying AWS’s position as a leader in providing comprehensive, end-to-end solutions for machine learning.
Industry analysts anticipate that this move will further accelerate the adoption of specialized AI models within enterprises. The combination of AWS’s powerful Nova models, robust SageMaker training infrastructure, and now, highly configurable and cost-efficient inference capabilities, creates a compelling ecosystem for businesses looking to gain a competitive edge through AI. This enables organizations to move beyond generic AI applications towards highly differentiated, domain-specific solutions that leverage their unique data assets.
An inferred statement from an AWS executive might highlight the company’s commitment: "This launch underscores our unwavering commitment to empowering enterprises with the most flexible, cost-effective, and powerful tools to deploy customized AI solutions at scale. By bringing enhanced control and efficiency to Nova model inference, we are enabling our customers to unlock new levels of innovation and derive greater value from their proprietary data."
Looking ahead, the trend towards highly specialized and cost-optimized AI inference is likely to continue. AWS is expected to further enhance SageMaker Inference with support for more instance types, additional optimization techniques, and broader regional availability. The focus will remain on simplifying the MLOps lifecycle, from data preparation and model training to deployment and monitoring, ensuring that businesses of all sizes can effectively leverage the transformative power of artificial intelligence. This continuous evolution will be critical for enterprises seeking to embed advanced AI capabilities deeply into their core operations, driving efficiency, innovation, and competitive advantage in an increasingly AI-driven world.
Customers are encouraged to explore these new capabilities within the Amazon SageMaker AI console and provide feedback through AWS re:Post for SageMaker or their usual AWS Support contacts, contributing to the ongoing evolution of the service.
