
The global semiconductor landscape is currently undergoing a foundational shift as the rapid proliferation of artificial intelligence (AI) demands a departure from traditional, general-purpose processing models. For over five decades, the central processing unit (CPU) served as the undisputed workhorse of the computing world. However, the emergence of complex AI workloads, particularly the shift toward "agentic AI" and large language models (LLMs), has exposed the limitations of single-processor architectures. Today, the industry is witnessing an explosion of specialized co-processors, neural processing units (NPUs), and heterogeneous systems-on-chip (SoCs) designed to handle the massive data movement and mathematical intensity of modern machine learning. While the theoretical benefits of these specialized architectures are clear, the practical challenges of coordination, data bottlenecks, and software programmability are creating a high-stakes environment for hardware designers.
The Historical Context of Specialized Processing
The concept of a co-processor is not a modern invention but a recurring theme in the history of computing. As early as the late 1970s, it was recognized that certain mathematical tasks were too taxing for a general-purpose CPU. The Intel 8086, for instance, relied on the 8087 floating-point co-processor to handle complex arithmetic. This pattern repeated in the 1990s with the rise of digital signal processors (DSPs). As cellular technology and audio processing became ubiquitous, the DSP emerged as a necessary secondary processor, optimized for the Fourier transforms and data streams required for signal modulation and error correction.
The subsequent decade saw the rise of the graphics processing unit (GPU). Initially driven by the demands of computer-aided design (CAD) and the burgeoning commercial gaming market, GPUs eventually became the catalyst for the modern AI revolution. By transitioning from rule-based systems to model-based deep learning, the GPU proved that massively parallel architectures could handle workloads that would leave a traditional CPU "choking" on data.
According to Steve Roddy, Chief Marketing Officer at Quadric, this evolution follows a predictable pattern: power and performance requirements motivate the creation of new processor categories, but full programmability determines which ones actually survive in the market. "Architects only introduce specialization when the CPU becomes inefficient," Roddy notes, highlighting that if a workload can run within power limits on a CPU, it generally remains there to avoid the complexity of offloading.
The Rise of Agentic AI and the NPU Evolution
In the current decade, the focus has shifted toward the Neural Processing Unit (NPU). Initially conceived as fixed-function hardware blocks designed for simple matrix multiplications—such as those found in convolutional neural networks (CNNs)—NPUs are now being forced to evolve. The shift from simple inference to "agentic" workloads represents a significant turning point. Agentic AI involves long-running reasoning loops, tool use, and complex memory access patterns that require more than just raw compute power.
William Wang, CEO of ChipAgents, argues that the challenge is shifting from building faster compute blocks to balancing general-purpose programmability with ASIC-level efficiency. As AI models like Llama and Claude introduce new operators and activation functions, fixed-function NPUs risk becoming obsolete before they even hit the market. If the hardware is not flexible enough to run a newly developed layer or operator, the entire system fails to deliver on its performance promises.
To combat this, modern NPUs are becoming more heterogeneous themselves. Gordon Cooper, principal product manager at Synopsys, describes the contemporary NPU as a collection of scalar processors, vector processors, and specialized math engines. In this hierarchy, the CPU remains the "host" or coordinator, managing the high-level control flow while offloading the heavy mathematical lifting to the NPU.
Technical Architectures and Data Movement Bottlenecks
One of the most critical realizations in modern chip design is that "peak TOPS" (Tera Operations Per Second) is often a vanity metric. Simon Davidmann, an AI and EDA researcher at the University of Southampton, emphasizes that the winning co-processor is not necessarily the fastest, but the one that wastes the least energy moving data. Data movement has become the primary bottleneck in AI performance, particularly with LLMs that possess billions of parameters.
Industry experts categorize current co-processing architectures into three primary types:
- Tightly Coupled Units: These benefit from low latency and shared memory, making them ideal for latency-sensitive workloads. However, they struggle to scale due to memory contention and coherence overhead.
- Loosely Coupled Accelerators: Often implemented as chiplets, these allow for modular scaling and specialization (e.g., separate dies for training vs. inference). The downside is higher latency and significant coordination complexity.
- Fabric-Based Distributed Systems: These strike a balance by enabling dynamic resource sharing across a fabric but place immense demands on the interconnect and system-level software.
Andy Nightingale, VP of product management at Arteris, warns that while standards like UCIe (Universal Chiplet Interconnect Express) and CXL (Compute Express Link) address physical protocol compatibility, they do not solve system-level behavioral integration. Differences in traffic management and quality of service (QoS) across different vendors can lead to unpredictable performance, making a consistent interconnect layer essential for reliability.

The Arm Approach: The Resurgence of the CPU
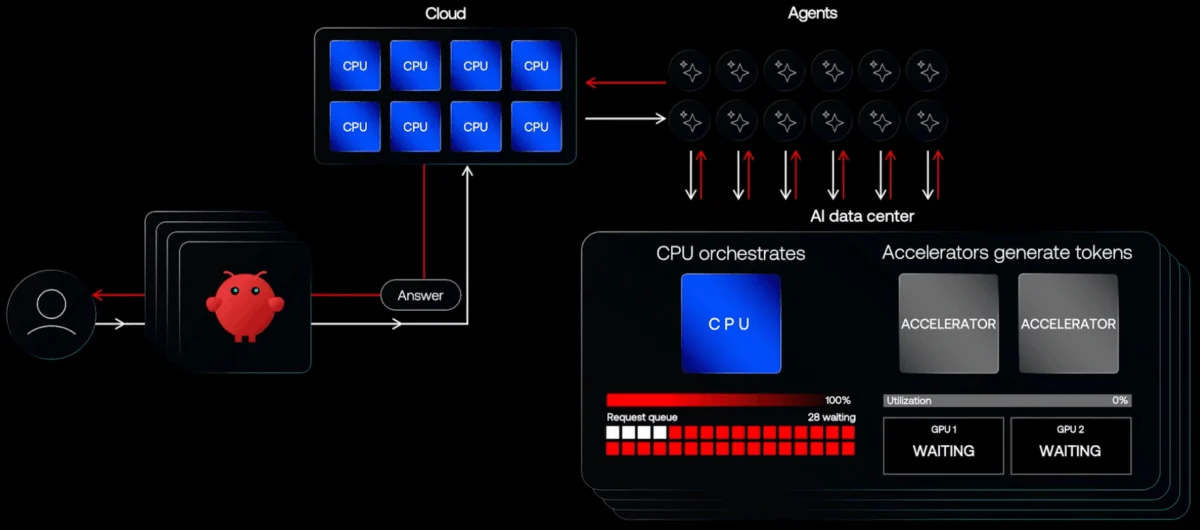
While much of the industry has focused on offloading tasks to accelerators, Arm is taking a contrarian approach by doubling down on the CPU. Rene Haas, Arm’s CEO, points out that agentic AI is inherently CPU-bound. As agents interact with software components and reason through loops, the control logic resides in the CPU.
Haas notes that the data center is currently "choking" because expensive accelerators generate tokens that must be sent back through the cloud, creating a massive bottleneck. By ramping up the performance-per-watt of the CPU itself, Arm aims to handle more of the AI logic locally, reducing the friction of switching between a host and a co-processor. This perspective suggests that the NPU and CPU are not just partners but are increasingly overlapping in their functional domains.
The Role of RISC-V and Photonic Innovation
The open-source RISC-V architecture is providing a new paradigm for this convergence. Dave Kelf, CEO of Breker Verification Systems, suggests that RISC-V is uniquely qualified for specialized accelerators because it allows designers to integrate processing elements directly into the accelerator. This eliminates the overhead of control and data transfer between separate units. By placing small RISC-V cores closer to MAC (multiply-accumulate) arrays, developers can segment workloads more effectively, allowing for "future-proof" flexibility in low-power AI devices.
Beyond traditional silicon, the industry is also exploring photonic AI accelerators. Jan van Hese of Keysight Technologies highlights that while photonic systems are difficult to design, they offer the potential for extreme speed and significantly lower power consumption by using light rather than electricity for computations. These alternative architectures represent the "bleeding edge" of the effort to bypass the thermal and electrical limits of modern semiconductors.
The Future-Proofing Dilemma
Perhaps the greatest challenge facing hardware architects today is the "time-to-market" vs. "rate-of-innovation" gap. It typically takes a year to design a chip and another year to integrate it into a product. In the world of AI, where new models and datatypes emerge every few months, a chip risks being outdated by the time it reaches the consumer.
Amol Borkar of Cadence notes that while tightly coupled hardware provides maximum efficiency for today’s workloads, any change in the model specification can leave the hardware in "bad shape." Consequently, designers are forced to include a "flexibility tax"—extra area and power devoted to programmable elements that ensure the chip can handle future, unknown operators.
The industry is also moving toward a "shift-left" design cycle. This involves simultaneous co-design at the IC, package, and system levels. By using system-level simulations early in the process, engineers can model how two dies communicating via UCIe will behave under real-world workloads, rather than waiting for physical prototypes.
Implications for the Global Semiconductor Market
The shift toward heterogeneous co-processing has profound implications for the global economy and the tech industry. First, it is driving a massive increase in design complexity, which favors large EDA (Electronic Design Automation) firms and IP providers who can offer pre-verified blocks. Second, it is decentralizing the power of the CPU, allowing specialized players in the NPU and interconnect space to gain significant market share.
Furthermore, the transition from fixed-function accelerators to fully programmable, independent AI processors is likely to simplify chiplet-based scaling. As Quadric’s Steve Roddy points out, history shows that real scaling only occurs when specialized engines decouple from the CPU and become fully programmable, much like the transition seen in the GPU market decades ago.
In conclusion, the "co-processor" is no longer just a sidekick to the CPU; it is the center of a new architectural universe. Whether the industry settles on a CPU-heavy model, a distributed chiplet ecosystem, or a RISC-V-driven integrated approach, the goal remains the same: minimizing data movement while maximizing the ability to adapt to an AI landscape that is changing faster than the silicon it runs on. The companies that successfully balance this "software friction" with hardware efficiency will define the next era of computing.
