
The relentless pace of artificial intelligence development has accelerated with OpenAI’s latest announcement: the release of GPT-5.5 and GPT-5.5 Pro. This unveiling marks a significant stride in the evolution of large language models, with OpenAI claiming its new iterations represent its most capable and intuitive offerings to date. The launch follows closely on the heels of Anthropic’s recent release of Opus 4.7, positioning the AI landscape for a renewed period of intense competition and innovation.
GPT-5.5 will be accessible to all existing paying users of OpenAI’s services, including ChatGPT and Codex. In parallel, GPT-5.5 Pro is being rolled out to premium subscribers across Pro, Business, and Enterprise tiers, exclusively within ChatGPT. While an API release is anticipated soon, OpenAI has indicated that this will come with a higher pricing structure compared to previous models.
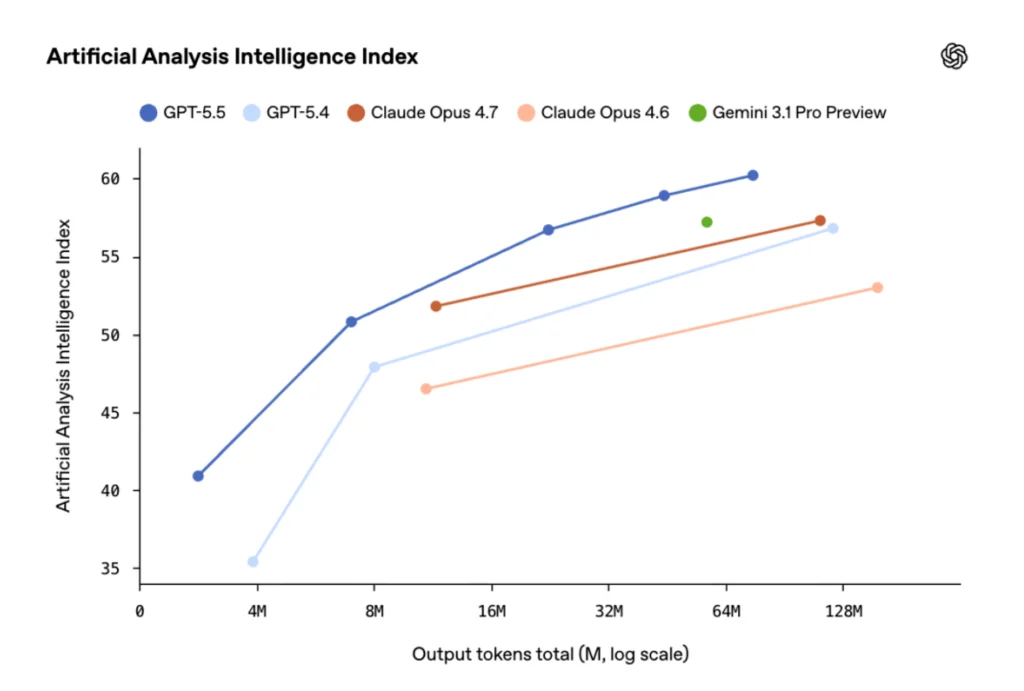
The competitive landscape has been particularly dynamic in recent weeks. Just a week prior to OpenAI’s announcement, Anthropic introduced Opus 4.7, a model that has garnered considerable attention. However, preliminary benchmark data shared by OpenAI suggests that GPT-5.5 and its Pro variant surpass Opus 4.7 across a broad spectrum of industry-standard performance evaluations. This suggests a potential shift in the leadership among leading AI developers, at least based on the metrics provided.

During a press briefing preceding the official launch, Greg Brockman, President and co-founder of OpenAI, characterized GPT-5.5 as ushering in "a new class of intelligence." He elaborated, stating, "It’s a big step towards more agentic and intuitive computing." This framing suggests a focus not just on raw processing power or knowledge recall, but on the model’s ability to act more autonomously and understand user intent with greater nuance.
Brockman further emphasized the model’s enhanced capacity for operating with minimal explicit instruction. "It’s just like, way more intuitive to use," he remarked. "It can look at an unclear problem and figure out just what needs to happen next. It really, to me, feels like it’s setting the foundation for how we’re going to use computers, how we’re going to do computer work, going forward – for how agentic computing at scale will work." This points towards a future where AI assistants are less about executing direct commands and more about proactively assisting users in complex tasks, anticipating needs, and navigating ambiguity.
A key claim from OpenAI is that despite these advancements, GPT-5.5 does not exhibit increased latency compared to its predecessor, GPT-5.4. Moreover, it reportedly utilizes fewer tokens for equivalent tasks, leading to greater efficiency. "It’s a faster, sharper thinker for fewer tokens, compared to something like [GPT] 5.4, so this means that there’s just more frontier AI available for businesses and for consumers, which is part of our goal," Brockman stated, a comment that could be interpreted as a subtle nod to the capacity constraints some competitors have faced. OpenAI asserts that GPT-5.5 delivers state-of-the-art intelligence "at half the cost of competitive frontier coding models," a significant value proposition for developers and businesses.
Enhanced Coding and Computational Dexterity
The improved coding capabilities of GPT-5.5 are a central theme in OpenAI’s release. Mia Glaese, OpenAI’s VP of Research, highlighted the model’s significantly enhanced performance in "senior engineering work in Codex." An anecdote shared by Glaese illustrated this point: an early tester provided GPT-5.5 with a poorly structured codebase and requested it be refactored into a "nice codebase." The output was reportedly akin to what a seasoned senior engineer would produce, demonstrating a sophisticated understanding of code quality, maintainability, and best practices.

In terms of quantitative performance, GPT-5.5 achieved scores of 82.7% on Terminal-Bench 2.0, a benchmark designed to assess a model’s proficiency in handling command-line workflows relevant to developers. Furthermore, on SWE-Bench Pro, which evaluates a model’s ability to resolve real-world issues found in GitHub repositories, GPT-5.5 scored 58.6%. While specific SWE-Bench Pro scores for Anthropic’s Opus 4.7 were not directly provided for comparison in the original source, a separate benchmark indicated Opus 4.7 reached 64.3% in that area, suggesting a slight advantage for Opus in this particular metric. However, on Terminal-Bench 2.0, GPT-5.5’s score of 82.7% significantly outpaced Opus 4.7’s 69.4%. OpenAI has not yet released coding benchmark results for GPT-5.5 Pro.
Beyond coding, the model’s capabilities in general computer use have also seen a substantial upgrade. Mark Chen, OpenAI’s Chief Research Officer, emphasized this evolution, stating, "With Codex’s computer-use capabilities, we’re really starting to feel like we have a model which approaches computer use with the same kind of dexterity and accuracy as it does with manipulating code." This indicates a move towards AI systems that can interact with and manage operating systems and applications with a level of sophistication previously confined to specialized tools.
On the OSWorld-Verified test, which simulates common operating system tasks, GPT-5.5 achieved a score of 78.7%, placing it slightly ahead of Opus 4.7’s 78%. While these scores are remarkably close, they underscore the incremental yet significant improvements being made in AI’s ability to navigate and interact with digital environments.
Academic and Mathematical Prowess
While models like Opus 4.7 and even Google’s Gemini 3.1 Pro have demonstrated strong performance in certain academic benchmarks, GPT-5.5 appears to be making substantial gains in others. Notably, GPT-5.5 has reportedly outperformed both Opus and Gemini on mathematics benchmarks, including FrontierMath Tier 1-3 and Tier 4. This suggests a more balanced development across different cognitive domains, addressing areas where previous models might have shown comparative weaknesses.

Development Methodology and Product Evolution
A recurring theme in OpenAI’s product development is the use of their own models in the creation process. For the GPT-5.5 release, OpenAI reiterated that both GPT-5.5 and Codex were instrumental in building this latest iteration. This self-referential development approach is a testament to the company’s confidence in its own technology and its potential to accelerate further innovation.
Greg Brockman also offered insight into OpenAI’s broader product strategy, emphasizing that the AI model itself is becoming only one component of a larger, integrated product. "So we at OpenAI, we want to bring agentic capabilities to all people who are trying to get their work done with their computer, not just as software engineers," he explained. "And one thing to understand is that the model itself is no longer the whole product, right? You can think of it as the brain, but also building the body in terms of the applications we ship, the agentic harnesses – that’s something we’re advancing as well." This indicates a strategic shift towards developing comprehensive AI solutions that encompass not only the core intelligence but also the user interfaces, tools, and frameworks necessary for practical application.
Addressing Cybersecurity Concerns in the Era of Mythos
In light of recent discussions surrounding Anthropic’s Mythos model and its advanced cybersecurity capabilities, OpenAI addressed its approach to mitigating potential risks associated with powerful AI. The company stated its belief that the most responsible path forward for models possessing sophisticated cybersecurity functions is to "make sure [the models] can be put to use for accelerating cyber defense and strengthening the ecosystem." This perspective positions AI as a tool for enhancing, rather than undermining, digital security.
OpenAI claims to be implementing "industry-leading safeguards" and plans to broaden access to AI capabilities that can accelerate cyber defense at all levels of the digital infrastructure. On the CyberGym benchmark, a test related to cybersecurity, GPT-5.5 achieved a score of 81.8%. While this is slightly below Mythos’s reported score of 83.1%, it demonstrates OpenAI’s continued focus on developing robust security features and ethical deployment strategies.

Availability and Pricing Structure
GPT-5.5 is now available to all paying users within ChatGPT and Codex. GPT-5.5 Pro is exclusively accessible to Pro, Business, and Enterprise users in ChatGPT. A "Thinking mode" for GPT-5.5 will also be offered to all paying subscribers.
For users requiring expedited processing in Codex, OpenAI is introducing a "Fast mode" for GPT-5.5. This mode will offer a 400,000-token context window and will be 1.5 times faster, though it will come at a 2.5 times higher cost.
In the API, GPT-5.5 will be priced at $5 per 1 million input tokens and $30 per 1 million output tokens, featuring a substantial 1 million token context window. This represents a doubling of the price compared to GPT-5.4. It’s worth noting that GPT-5.4 had a tiered pricing structure, with prompts under 272,000 tokens charged at a standard rate, and larger prompts incurring a higher cost.
OpenAI acknowledges the price increase for GPT-5.5 in its official announcement, stating, "While GPT-5.5 is priced higher than GPT-5.4, it is both more intelligent and much more token efficient. In Codex, we have carefully tuned the experience so GPT-5.5 delivers better results with fewer tokens than GPT-5.4 for most users, while continuing to offer generous usage across subscription levels."

For GPT-5.5 Pro, the pricing remains consistent with GPT-5.4, set at $30 per 1 million input tokens and $180 per 1 million output tokens. This tiered pricing strategy reflects the different levels of performance and access offered across OpenAI’s product suite, catering to a range of user needs from individual developers to large enterprises. The introduction of these advanced models signifies a continuous push in the AI race, promising greater capabilities and new avenues for innovation across various sectors.
