
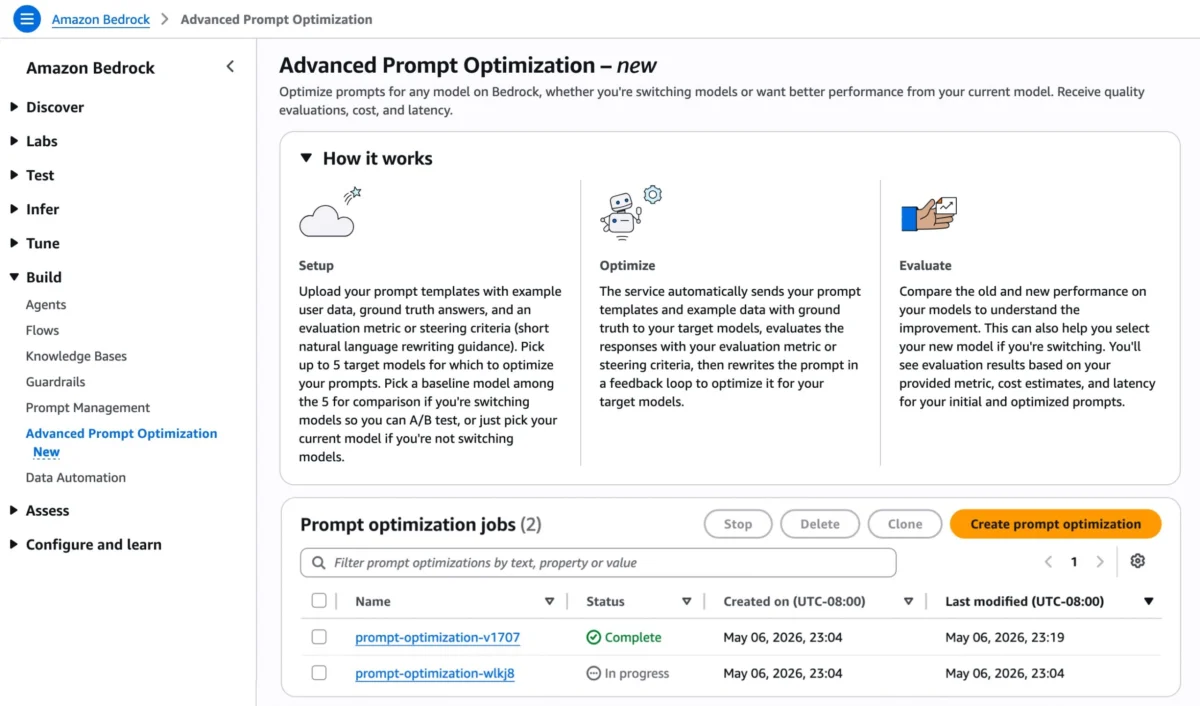
Seattle, Washington – Amazon Web Services (AWS) today announced the launch of Amazon Bedrock Advanced Prompt Optimization, a sophisticated new tool designed to empower developers and enterprises to refine and optimize their prompts for any foundational model available on Amazon Bedrock. This innovative service addresses a critical challenge in generative AI development by enabling simultaneous comparison of original and optimized prompts across up to five distinct models, facilitating seamless model migration and significant performance enhancements for existing deployments.
The introduction of Advanced Prompt Optimization marks a significant step forward in the ongoing evolution of generative AI, where the quality and effectiveness of "prompts"—the instructions given to large language models (LLMs) and other foundational models (FMs)—are paramount to achieving desired outputs. As the landscape of AI models becomes increasingly diverse and complex, the art and science of prompt engineering have emerged as a specialized discipline. However, manual prompt tuning is often time-consuming, subjective, and difficult to scale, leading to suboptimal performance, increased costs, and prolonged development cycles. AWS’s new offering directly tackles these pain points, providing a systematic, metric-driven approach to prompt refinement.
Background: The Evolving Landscape of Generative AI and Prompt Engineering

The rapid ascent of generative AI, powered by increasingly powerful foundational models, has revolutionized various industries, from content creation and software development to customer service and scientific research. Amazon Bedrock, launched by AWS, serves as a fully managed service that provides access to a selection of high-performing FMs from Amazon and leading AI startups, all via a single API. This platform has been instrumental in democratizing access to cutting-edge AI capabilities, allowing businesses to build and scale generative AI applications without managing underlying infrastructure.
However, simply having access to powerful models is not enough. The efficacy of these models heavily depends on the precision and clarity of the prompts they receive. Poorly crafted prompts can lead to irrelevant, inaccurate, or hallucinated responses, diminishing the value of the AI application. This has given rise to prompt engineering—the process of designing and refining prompts to elicit optimal responses. Early prompt engineering often involved trial-and-error, an iterative process where developers manually tweaked prompts and observed model outputs. While effective for simple tasks, this approach quickly becomes unwieldy for complex applications, multi-modal inputs, or scenarios requiring fine-tuned performance across different models.
Challenges compounded when organizations sought to migrate between models—perhaps due to cost considerations, performance requirements, or the availability of newer, more capable FMs. Prompts optimized for one model might perform poorly on another, necessitating a complete re-engineering effort. Furthermore, quantifying the "goodness" of a prompt’s output, beyond subjective human judgment, has been a persistent hurdle, particularly for nuanced tasks or those requiring adherence to specific metrics like accuracy, relevance, or factual correctness. The Advanced Prompt Optimization feature directly addresses these challenges by automating and objectifying the prompt refinement process.
Key Features and Functionality: A Deep Dive into Optimization

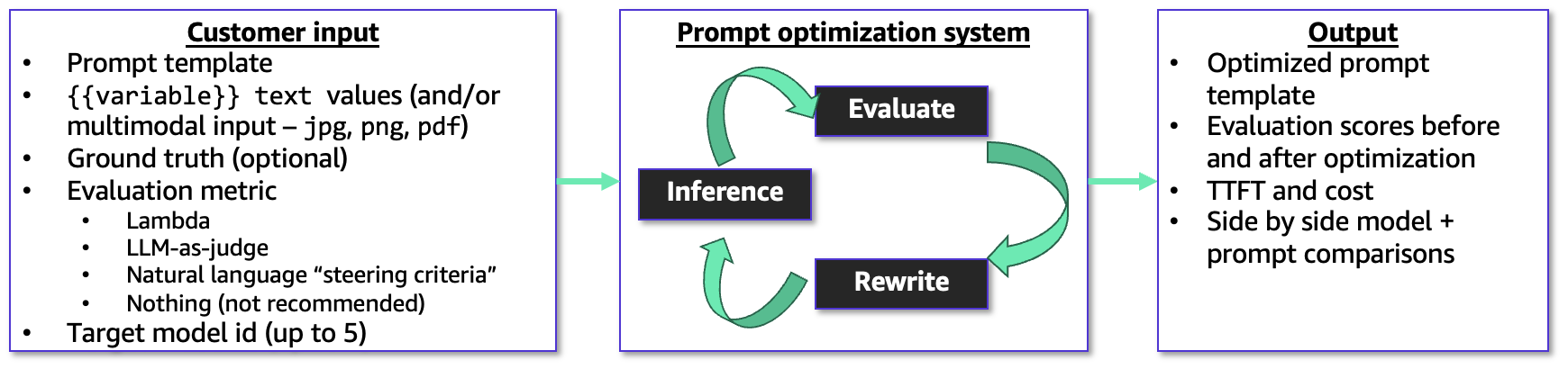
At its core, Amazon Bedrock Advanced Prompt Optimization operates on a metric-driven feedback loop, systematically enhancing prompt templates. The process begins with users providing a prompt template, coupled with example user inputs, desired ground truth answers, and a chosen evaluation metric. This structured input allows the optimizer to understand the task, the expected outcomes, and the criteria for success.
A significant innovation within this tool is its support for multimodal user inputs. Developers can now include files such as .png, .jpg, and .pdf within their prompt templates. This capability is crucial for optimizing prompts for complex tasks like document analysis, image interpretation, or multimodal content generation, where textual prompts alone are insufficient. For instance, a financial institution could optimize a prompt for extracting specific data points from diverse PDF reports, ensuring high accuracy across varying document layouts.
The evaluation process is highly flexible, allowing users to guide the optimization through several sophisticated methods:
- AWS Lambda Function: For highly customized and precise evaluation logic, users can provide an AWS Lambda function. This allows developers to implement their own Python-based scoring algorithms, enabling granular control over how model responses are judged against ground truth. This is particularly valuable for niche industry applications or proprietary performance metrics.
- LLM-as-a-Judge Rubric: Leveraging the capabilities of other LLMs, users can define a custom rubric in natural language. An LLM acts as an "evaluator," assessing the responses generated by the target model against the specified criteria. This method introduces a powerful, AI-driven form of qualitative assessment, converting subjective human judgment into a scalable, automated process.
- Natural Language Steering Criteria: For simpler or more general optimization goals, users can provide a short natural language description to guide the process. This method offers ease of use for quick iterations or for developers who prefer a less technical approach to defining evaluation parameters.
Once configured, the prompt optimizer iteratively rewrites and tests the prompt template. It feeds the revised prompts and example data to the selected inference models, evaluates their responses using the specified metric, and then uses these evaluation scores to further refine the prompt. This continuous feedback loop ensures that the prompts are progressively optimized towards the desired performance benchmarks. The output of the optimization job includes both the original and the final optimized prompt templates, along with detailed evaluation scores, estimated costs per inference, and latency metrics for each model. This comprehensive data allows developers to make informed decisions about which optimized prompt and model combination best suits their needs.
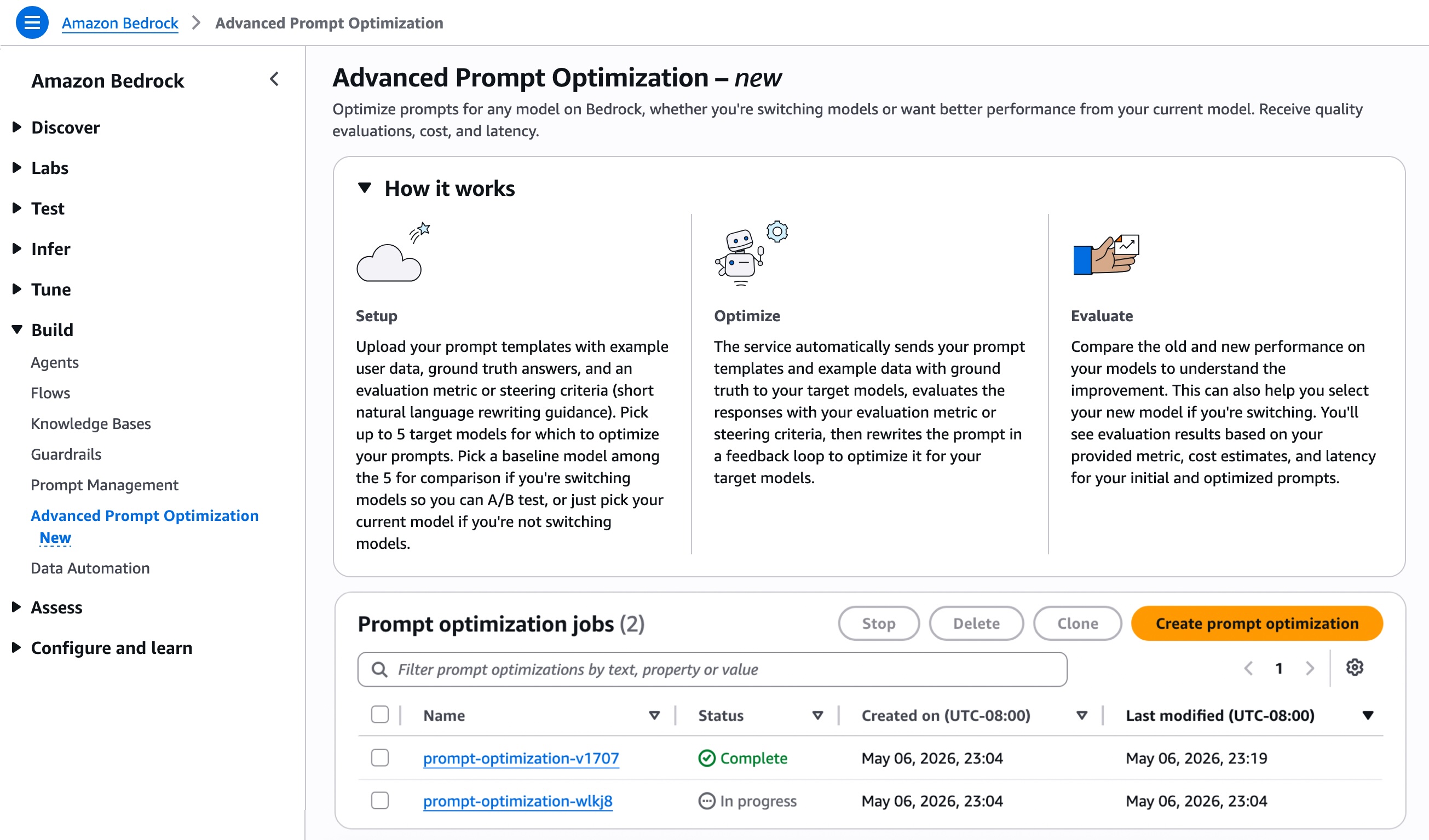
Practical Application: Bedrock Advanced Prompt Optimization in Action
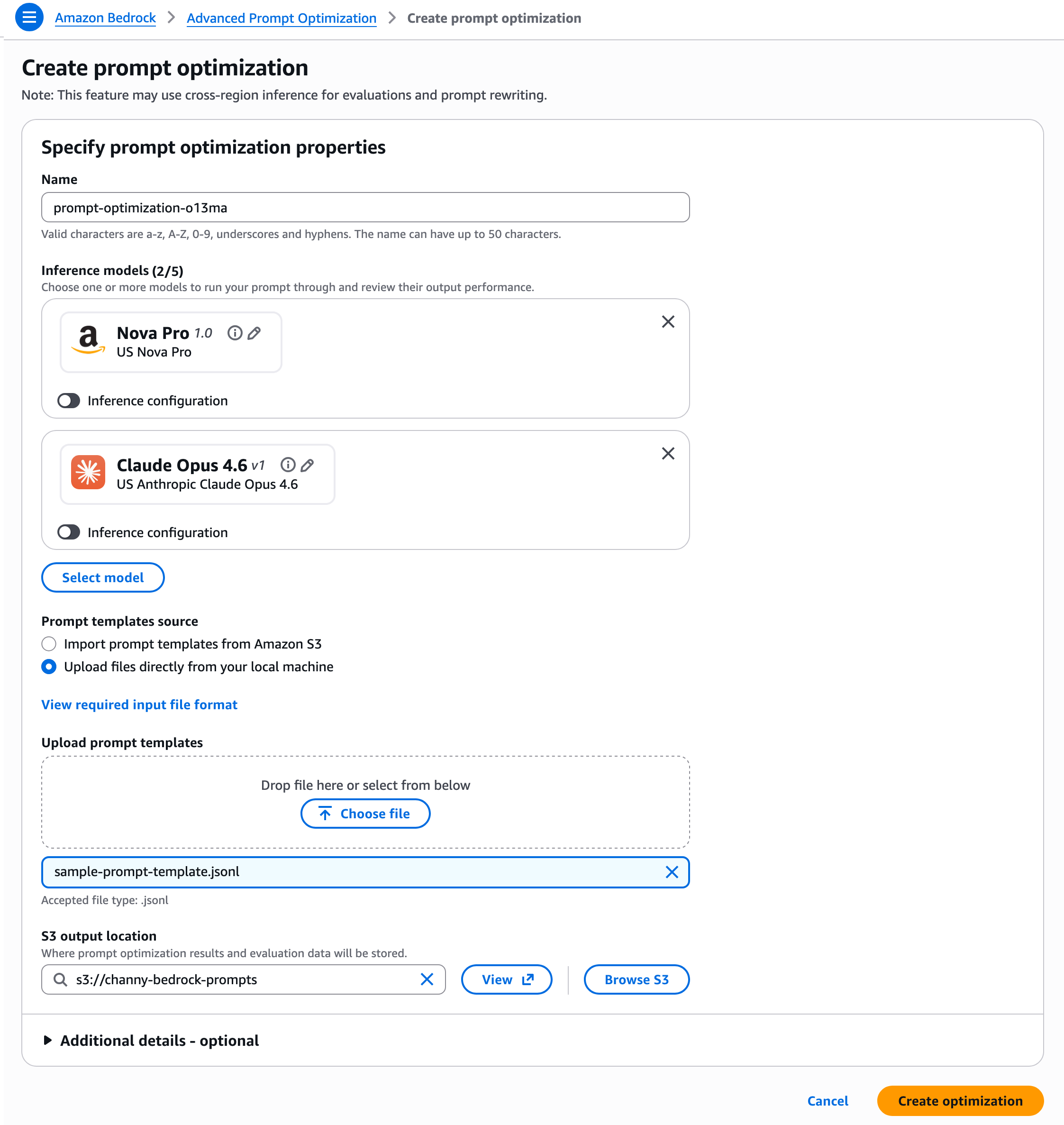
The user experience for initiating a prompt optimization job is designed for intuitiveness. Within the Amazon Bedrock console, users navigate to the "Advanced Prompt Optimization" page and select "Create prompt optimization." Here, they can choose up to five inference models for which to optimize their prompts. This multi-model comparison feature is a cornerstone of the service, addressing key use cases:
- Model Migration: Organizations looking to switch from one foundational model to another (e.g., due to cost efficiency, improved performance, or specific feature sets) can select their current model as a baseline and up to four potential new models. The optimization process will then identify the prompt variations that perform best across the target models, significantly reducing the effort and risk associated with migration.
- Performance Enhancement: For users who wish to improve the performance of their existing model, they can select only their current model. The tool will then provide "before and after" optimization results, showcasing the gains achieved in specific metrics like accuracy, relevance, or response coherence.
Input prompt templates are expected in JSONL format, containing the template itself, example user data, optional ground truth answers, and the chosen evaluation guidance. The service supports direct file uploads or imports from Amazon Simple Storage Service (Amazon S3), with S3 also serving as the output location for optimization results and evaluation data.
This structured approach ensures that the optimization process is repeatable, transparent, and data-driven. Developers no longer need to guess which prompt variation is best; they receive empirically validated results, complete with cost and latency considerations, enabling them to balance performance with operational efficiency.
Addressing Broader Implications and Strategic Impact
The launch of Amazon Bedrock Advanced Prompt Optimization carries significant implications for the broader AI development ecosystem and AWS’s strategic positioning:
- Democratization of Advanced Prompt Engineering: By automating and simplifying the prompt optimization process, AWS is making advanced prompt engineering accessible to a wider range of developers, including those without deep expertise in machine learning. This lowers the barrier to entry for building high-quality generative AI applications.
- Cost Efficiency and Operational Savings: Optimized prompts can lead to more concise and accurate model responses, potentially reducing the number of tokens processed per inference. Over time, across large-scale deployments, this translates into substantial cost savings on model inference, a critical factor for businesses leveraging generative AI. The tool provides cost estimates directly, enabling proactive budget management.
- Accelerated Development Cycles: The automated feedback loop dramatically reduces the time and effort traditionally spent on manual prompt tuning. This allows developers to iterate faster, bring AI applications to market quicker, and respond more agilely to evolving business requirements.
- Enhanced Model Interoperability and Flexibility: The ability to optimize prompts across multiple models simultaneously fosters greater flexibility and reduces vendor lock-in. Developers can confidently experiment with different FMs on Bedrock, knowing they have a tool to ensure optimal performance regardless of the underlying model choice. This encourages innovation and allows businesses to select the best model for a specific task based on a holistic view of performance, cost, and latency.
- Improved AI Application Quality: By systematically improving prompt quality, the tool directly contributes to higher quality, more reliable, and more relevant outputs from generative AI models. This is crucial for building trust in AI applications, particularly in sensitive domains where accuracy and factual correctness are paramount.
- Strengthening MLOps for Generative AI: This feature integrates advanced prompt engineering into a more mature MLOps (Machine Learning Operations) pipeline for generative AI. It moves beyond isolated model training and deployment to encompass the entire lifecycle, including robust evaluation and continuous optimization of inputs, which is essential for maintaining and improving AI system performance in production environments.
An AWS spokesperson, speaking on the strategic importance of this launch, highlighted, "Our customers are rapidly deploying generative AI across a vast array of use cases, and they consistently tell us that prompt engineering is a critical bottleneck. With Advanced Prompt Optimization, we’re providing a powerful, data-driven solution that not only helps them achieve superior model performance but also significantly reduces the complexity and cost associated with building and maintaining these sophisticated applications. This is about empowering every developer to unlock the full potential of foundational models on Bedrock."
Industry analysts are expected to view this as a strategic move by AWS to further differentiate Amazon Bedrock in a competitive market. "The automation of prompt optimization is not just a convenience; it’s a necessity for enterprises scaling their generative AI initiatives," noted one unnamed AI industry observer. "AWS is addressing a foundational challenge, moving beyond simply offering access to models to providing tools that ensure those models are used effectively and efficiently across diverse business needs."
Availability and Pricing
Amazon Bedrock Advanced Prompt Optimization is immediately available in several key AWS regions globally, including US East (N. Virginia, Ohio), US West (Oregon), Asia Pacific (Mumbai, Seoul, Singapore, Sydney, Tokyo), Canada (Central), Europe (Frankfurt, Ireland, London, Zurich), and South America (São Paulo). This broad regional availability ensures that a wide array of AWS customers can leverage the new capabilities.
Pricing for the service is based on the Bedrock model-inference tokens consumed during the optimization process, charged at the same per-token rates as regular Bedrock inference. This transparent pricing model allows organizations to estimate costs effectively and integrate prompt optimization into their overall AI budget planning without encountering unexpected fees.
Developers and organizations are encouraged to explore the advanced prompt optimization feature via the Amazon Bedrock console or through the CreateAdvancedPromptOptimizationJob API. Comprehensive documentation is available in the advanced prompt optimization in Bedrock guide, and sample codes are provided in the AWS Samples GitHub repository, offering practical examples to help users get started quickly. AWS also invites feedback through AWS re:Post for Amazon Bedrock and standard AWS Support channels, emphasizing a commitment to continuous improvement based on user experience. This iterative approach to product development mirrors the very optimization principles embedded in their new offering, promising a future where generative AI applications are not only powerful but also precisely tuned and highly efficient.
