
The landscape of artificial intelligence interaction is undergoing a fundamental transformation, moving beyond the art of crafting effective prompts for chatbots to an architectural discipline known as context engineering. This evolution, driven by the increasing sophistication of agentic AI systems, signals a new frontier in building robust, reliable, and scalable autonomous agents. As AI systems gain the ability to perform multi-step tasks, interact with tools, and make independent decisions, the traditional methods of prompting—focused on eliciting a single, good response—are proving insufficient. Leading research institutions and AI development teams, notably Anthropic and Google, are championing this shift, recognizing that designing how an AI system "thinks" across an extended sequence of actions is paramount.
The Emergence of Agentic AI and Prompting’s Limitations
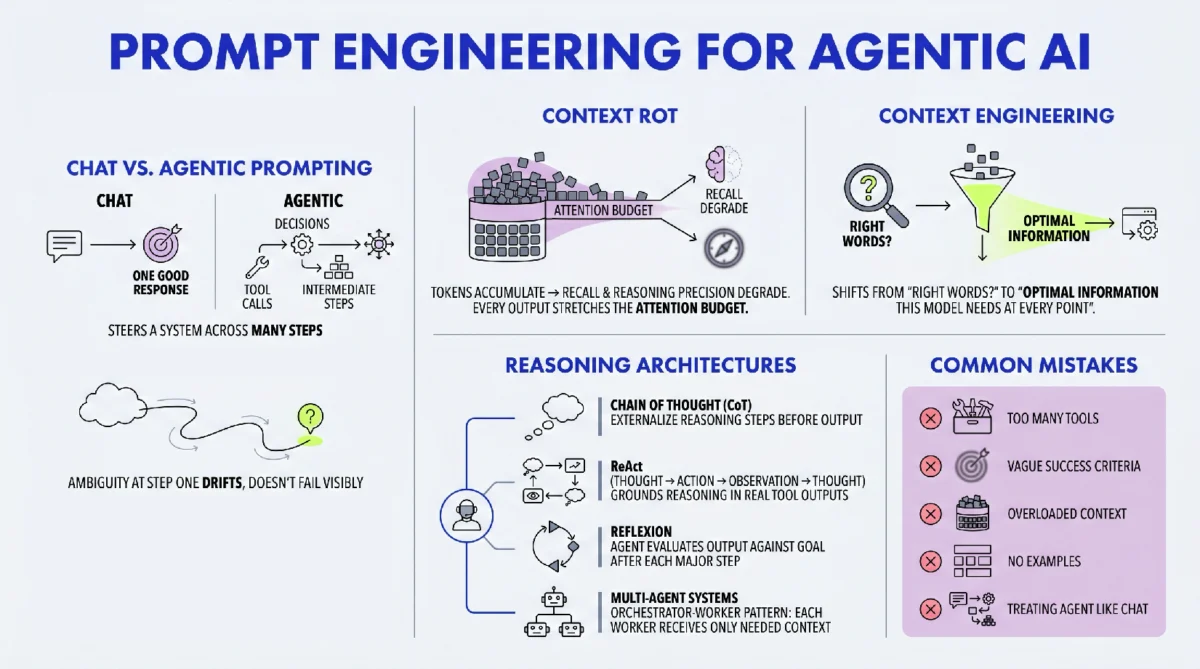
For years, AI practitioners honed their skills in prompt engineering, mastering techniques to phrase questions, provide clear instructions, and offer context within a single conversational turn. This knowledge remains invaluable for interacting with conventional large language models (LLMs) in a chat-based interface. However, the advent of agentic AI introduces a new paradigm. Unlike chatbots, which respond to direct queries, agents are designed to pursue goals autonomously, constructing plans, executing them across multiple steps, leveraging external tools, generating intermediate outputs, and recovering from errors, all without constant human oversight.
The core challenge in this agentic landscape lies in the distributed nature of prompt effects. A seemingly minor ambiguity in an initial instruction to an agent can lead to significant drift over several steps, resulting in an outcome far removed from the user’s original intent. By the time such a discrepancy becomes apparent, the system may have consumed considerable computational resources, time, and API calls. This stands in stark contrast to chatbot interactions, where feedback loops are immediate, and errors can be corrected on the fly.
The Problem of "Context Rot" and the Rise of Context Engineering
A critical factor compounding the complexity of agentic prompting is the phenomenon known as "context rot." As an agent progresses through a multi-step task, its context window—the operational memory containing all prior interactions, tool call results, and intermediate outputs—inevitably expands. Research, including studies by Chroma and Anthropic, demonstrates that as the number of tokens in this context window grows, an LLM’s ability to accurately recall and reason over that information diminishes. Constraints clearly stated at the outset of a long task can be lost or deprioritized by the middle, leading to erratic or inconsistent behavior.
It is in response to these fundamental challenges that Anthropic’s engineering team formally introduced the concept of context engineering. Their framing succinctly captures the paradigm shift: while prompt engineering asks, "What are the right words?", context engineering elevates the inquiry to, "What is the optimal set of information this model should have at every point during execution?" This architectural perspective emphasizes deliberate design over iterative phrasing, aiming to build agents that exhibit reliable behavior at scale.
Foundational Pillars of Effective Agent Design
Based on foundational frameworks, such as Lilian Weng’s comprehensive analysis of LLM-powered agents and Anthropic’s practical guidance, a robust agent relies on four meticulously designed categories of context:
-
The System Prompt: Setting the Agent’s Mandate:
The system prompt serves as the agent’s enduring charter, defining its role, available tools, critical constraints, and expected output format for the entire task lifecycle. It is the most influential piece of text in an agent’s architecture, yet it is prone to two primary failure modes: over-specification and under-specification. Over-specification leads to brittle prompts laden with explicit, if-else logic, which falter when unforeseen edge cases arise. Conversely, under-specification results in vague goals that assume shared context the model lacks. The optimal approach, termed the "right altitude" by Anthropic, balances specificity with flexibility. A strong system prompt delineates a clear role (e.g., "research assistant for a B2B SaaS product team"), behavioral heuristics (e.g., "prioritize primary sources," "flag outdated information"), and output structure (e.g., "structured report with Executive Summary, Findings, Sources"), allowing the agent judgment within defined boundaries rather than dictating every action. -
Optimizing Tool Integration: Precision and Purpose:
Each tool integrated into an agent’s capabilities represents a decision point and a token cost. Bloated or ambiguously described tool sets are a common source of failure in production agents, as the model struggles to reliably select the appropriate tool. Experts advise that every tool should possess a singular, clear purpose, accompanied by a description that leaves no room for ambiguity, and parameters that are self-explanatory. For instance, a "web_search" tool’s description should not only state its function but also specify when to use it (e.g., "for current information not in training data") and when not to (e.g., "do NOT use to retrieve documents already provided"). This precise boundary definition prevents inefficient tool usage and token waste. -
Leveraging Examples: In-Context Learning for Behavior Shaping:
Empirical research consistently highlights the superiority of concrete examples over abstract instruction lists for shaping agent behavior. Few-shot prompting, where the model is presented with two or three input-output pairs, activates in-context learning. For agents, these examples go beyond demonstrating the "right answer"; they illustrate the expected reasoning format, decision style, and output structure. A powerful example for an agent will show its thinking process, including how it might clarify an ambiguous request before proceeding, rather than just the final result. This teaches the agent to internalize the desired problem-solving approach. -
Managing Message History and Context State: The Just-in-Time Approach:
The accumulated message history—comprising prior turns, tool call results, and intermediate outputs—is both essential for continuity and the primary source of context rot. Dumping all information into the context window, while intuitive, effectively "dumbs down" the agent as tasks grow longer. The transformer’s attention mechanism operates on an "attention budget," where every token competes for focus. Overloading this budget reduces the model’s precision in information retrieval and long-range reasoning. The sophisticated solution is "just-in-time context." Instead of pre-loading all potentially relevant data, agents maintain lightweight references (e.g., file paths, URLs) and fetch specific information only at the moment it is needed for the current step. This strategy, exemplified by Anthropic’s Claude Code, keeps the active context lean, preserving the agent’s attention budget for critical reasoning.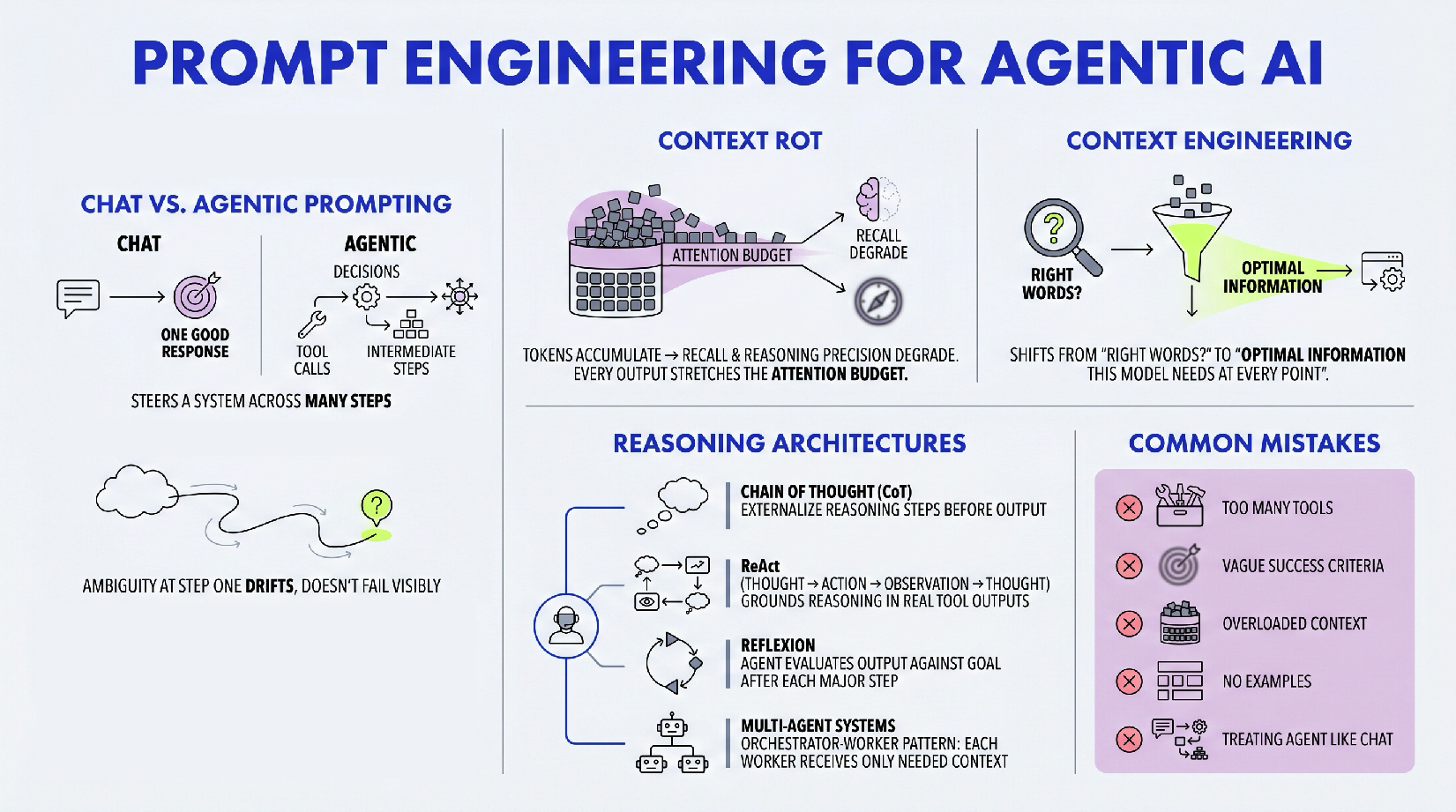
Architectural Innovations for Robust Agent Reasoning
Beyond context management, the internal reasoning structure of an agent significantly impacts its performance. Pioneering research from Google’s team in 2022 demonstrated that even without model upgrades, providing a structured way to reason could dramatically improve success rates, such as transforming a 4% success rate to 74% on Game of 24 puzzles.
-
Chain of Thought (CoT): Externalizing Internal Logic:
Chain of Thought prompting is a foundational architectural upgrade. Rather than directly generating an answer, the model is instructed to explicitly generate its reasoning steps first. The simple addition of phrases like "Let’s think step by step" has been shown to activate a deeper reasoning mode. This not only enhances accuracy but also makes the agent’s decision-making process transparent and auditable, a crucial feature for high-stakes applications. The effectiveness of CoT is amplified when the reasoning structure is tailored to the specific task, be it financial analysis, code debugging, or competitive research. -
ReAct (Reason + Act): Grounding Reasoning in Evidence:
ReAct (Reason + Act) is the predominant pattern for agents that interact with tools. It establishes an iterative loop: Thought → Action → Observation → Thought. The agent first reasons about its next move, then executes an action using a tool, observes the concrete result, and subsequently reasons again based on this new evidence. This cycle continues until the task is complete. ReAct is powerful because it compels the model to test its assumptions against real-world tool outputs, effectively preventing confident but hallucinatory answers by grounding reasoning in verifiable evidence. -
Reflexion: Enabling Agentic Self-Correction:
Reflexion extends the ReAct paradigm by introducing a self-correction mechanism. Upon completing a major task step or the entire task, the agent evaluates its own output against the initial goal, identifies any failures or gaps, and then generates a revised plan before proceeding. This technique allows agents to catch and correct their own mistakes without requiring human intervention at every turn. While it adds some latency, Reflexion is invaluable for tasks where quality and completeness are paramount, such as report generation or complex analysis, significantly reducing the incidence of incomplete or inconsistent outputs.
Context Engineering in Practice: Actionable Strategies
Translating these theoretical principles into practical agent development involves adopting specific habits:
- Maintain "Right Altitude" System Prompts: Avoid both overly prescriptive flowcharts and vague mission statements. Focus on clear roles, behavioral principles, and output expectations. When tempted to write "if X, do Y," reframe it as a guiding principle like "Prioritize accuracy over speed."
- Prioritize Outcome Prompts Over Procedure Lists: Instead of dictating a step-by-step procedure (which can be fragile when reality deviates), tell the agent what the finished product should look like. An outcome-oriented prompt allows the agent to adapt its internal process when faced with unexpected data structures or intermediate results.
- Embrace Just-in-Time Context: Resist the urge to pre-load all potential data. Design agents to maintain lightweight references (e.g., file paths) and retrieve specific information using targeted tool queries only when it’s directly relevant to the current step. This preserves the attention budget and improves long-task performance.
- Implement Dynamic Persona Priming: For agents serving diverse user groups, inject context-specific persona information at runtime. This allows a single agent architecture to adapt its tone, depth, and communication style (e.g., for technical vs. non-technical users) without requiring separate agents or prompt files.
Prompting Multi-Agent Systems: Orchestration and Minimal Shared Context
For highly complex tasks requiring parallel workstreams, specialized domain knowledge, or built-in checks and balances, multi-agent systems are proving increasingly effective. The dominant architectural pattern involves an orchestrator agent that receives the overarching goal, decomposes it into subtasks, delegates these to specialized worker agents, and finally synthesizes their results.
The key to prompting such systems lies in designing clear handoffs and adhering to the principle of "minimal shared context." Each worker agent needs to know precisely its responsibilities, expected inputs, and required outputs, but it does not need to understand the full system architecture, the user’s history, or the activities of other agents. This compartmentalization keeps individual agent contexts lean, minimizes cross-contamination, and simplifies debugging. For instance, a research orchestrator might delegate a search query to a "search_agent" and analysis to an "analysis_agent," each operating with its own specialized prompt and tools, isolated from the broader task context.
The Path Forward: From Phrasing to Architecture
The transition from prompt engineering for chatbots to context engineering for agentic AI represents a maturation of the field. It is no longer merely about finding the "right words" but about architecting a reliable, self-managing system. The teams currently achieving significant breakthroughs with agentic AI are those that have embraced this shift, focusing on what information a model needs at every execution step to behave predictably and consistently.
This paradigm shift necessitates a new skill set for AI builders, moving from linguistic finesse to a deeper understanding of system design, context management, and reasoning architectures. Starting with a precisely calibrated system prompt, providing unambiguous tools, demonstrating reasoning styles with few-shot examples, and adopting just-in-time context management are the habits that will drive the next generation of robust and scalable autonomous AI. As the field progresses, resources like Anthropic’s "Effective Context Engineering for AI Agents" and the "Prompt Engineering Guide’s agents section" offer invaluable practical and technical depth for practitioners navigating this exciting and challenging new domain. The future of AI reliability and autonomy hinges on mastering context engineering.
