
On March 14, 2006, a seemingly modest announcement on the AWS "What’s New" page introduced Amazon Simple Storage Service (Amazon S3), a service that would quietly but profoundly reshape the landscape of digital infrastructure, laying the foundational blocks for the modern cloud computing era. Twenty years later, S3 stands as a colossal testament to scalable engineering, enduring reliability, and continuous innovation, serving as the backbone for countless applications, businesses, and the burgeoning fields of artificial intelligence and big data analytics.
The Dawn of a New Era: The Pre-S3 Landscape
Before the advent of Amazon S3, developers and businesses faced significant hurdles in managing digital data. Storing and retrieving information at scale demanded substantial upfront investments in hardware, including servers, storage arrays, and networking equipment. Companies were burdened with the "undifferentiated heavy lifting" of procuring, configuring, maintaining, and scaling physical storage infrastructure. This involved complex tasks such as data replication for durability, setting up disaster recovery plans, managing backup tapes, and constantly upgrading hardware to keep pace with growth.
The typical workflow involved provisioning dedicated file servers or network-attached storage (NAS) devices, which were expensive, prone to single points of failure, and notoriously difficult to scale elastically. Startups and small businesses found these barriers to entry prohibitive, limiting their ability to innovate and compete with larger enterprises that could afford vast IT departments. Data accessibility was often geographically constrained, and ensuring high availability and robust security across distributed systems was a monumental engineering challenge for even the most well-resourced organizations. This environment fostered a strong demand for a more agile, cost-effective, and scalable solution, a demand that S3 would soon meet with unprecedented simplicity.
The Quiet Launch and Revolutionary Philosophy
The initial announcement for Amazon S3 was succinct, a mere paragraph outlining its core promise: "Amazon S3 is storage for the Internet. It is designed to make web-scale computing easier for developers. Amazon S3 provides a simple web services interface that can be used to store and retrieve any amount of data, at any time, from anywhere on the web. It gives any developer access to the same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of web sites." Jeff Barr’s accompanying blog post, written hastily before a flight to a developer event, also reflected this understated introduction, devoid of code examples or grand demonstrations. Yet, within this simplicity lay a radical vision.
At its heart, S3 introduced two fundamental primitives: PUT to store an object and GET to retrieve it. This elegant simplicity masked an intricate, resilient architecture designed to abstract away the complexities of storage management. The real innovation was not just the technology but the philosophy behind it: to provide foundational "building blocks" that handle the heavy lifting of infrastructure, thereby freeing developers to concentrate on higher-level application logic and innovation. This concept would become a cornerstone of cloud computing, enabling a paradigm shift from CapEx-heavy infrastructure ownership to OpEx-driven utility services.
The Five Unchanging Fundamentals of S3
From its inception, Amazon S3 was guided by five core principles that remain central to its design and operation today:
- Security: Data protection is paramount, with security built-in by default through robust access controls, encryption options, and integration with AWS Identity and Access Management (IAM).
- Durability: S3 is engineered for 11 nines of durability (99.999999999%), meaning that for every 10,000,000 objects stored, there is an average annual loss of only one object. This is achieved through extensive data replication across multiple devices and Availability Zones.
- Availability: Designed with the assumption that failures are inevitable, S3 incorporates redundancy and fault tolerance at every layer to ensure high availability, making data accessible whenever needed.
- Performance: Optimized to handle virtually any amount of data without degradation, S3 provides consistent, high-speed access for a wide range of workloads, from static website hosting to large-scale data processing.
- Elasticity: The system automatically scales up and down in response to changing data volumes and request rates, requiring no manual intervention from users. This inherent elasticity eliminates the need for capacity planning and over-provisioning.
These fundamentals were not merely features; they were architectural commitments that allowed developers to build applications with unprecedented confidence, knowing that the underlying storage infrastructure was robust, secure, and infinitely scalable. This "just works" approach transformed how developers perceived and utilized storage, making it a utility rather than a constant operational burden.
Exponential Growth: From Petabytes to Exabytes
The evolution of S3 over two decades presents a compelling narrative of exponential growth and technological advancement. At its launch in 2006, S3 offered approximately one petabyte of total storage capacity, managed by around 400 storage nodes housed in 15 racks across three data centers. It was designed to store tens of billions of objects, with a maximum object size of 5 GB, and priced at 15 cents per gigabyte per month.
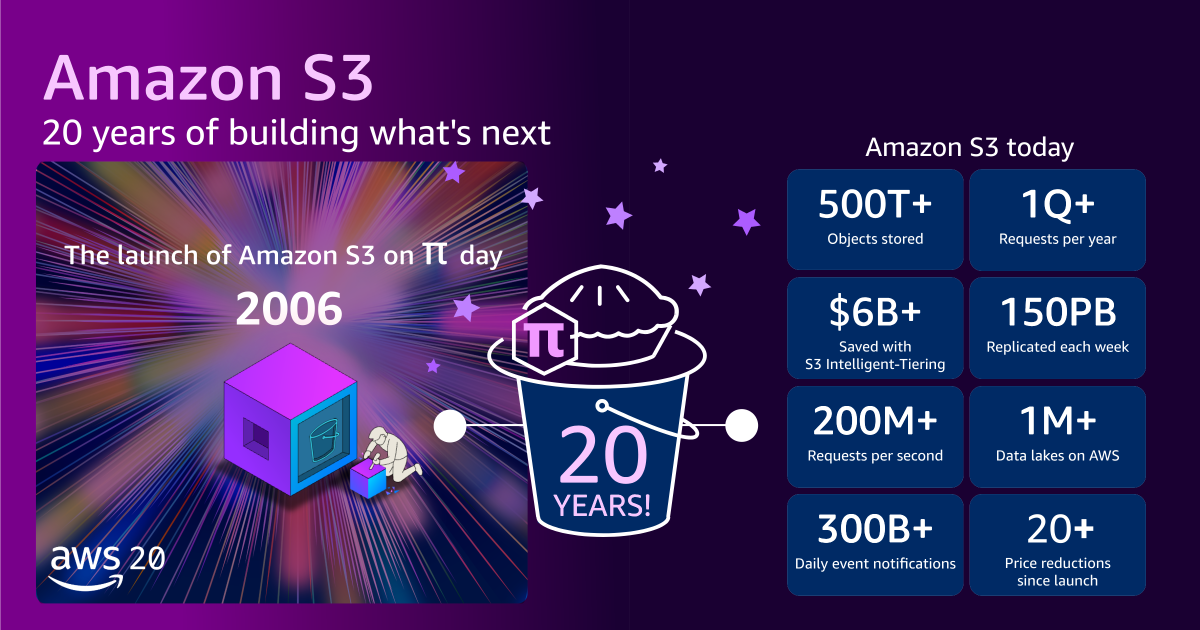
Fast forward to its 20th anniversary, and the scale is almost incomprehensible. Today, Amazon S3 stores more than 500 trillion objects, serving over 200 million requests per second globally across hundreds of exabytes of data. This vast infrastructure is distributed across 123 Availability Zones in 39 AWS Regions, catering to millions of customers worldwide. The maximum object size has dramatically increased from 5 GB to 50 TB, a staggering 10,000-fold expansion, accommodating massive datasets required by modern applications. To put its physical scale into perspective, if all the tens of millions of hard drives comprising S3 were stacked, they would reach the International Space Station and nearly back again.
This monumental growth has been accompanied by a significant reduction in cost. The initial price of 15 cents per gigabyte has plummeted by approximately 85%, with current pricing slightly over 2 cents per gigabyte. Furthermore, AWS has introduced various storage classes and features like Amazon S3 Intelligent-Tiering, which automatically moves data between access tiers based on usage patterns, allowing customers to optimize costs further. This intelligent tiering alone has collectively saved customers over $6 billion in storage costs compared to using standard S3. This continuous price reduction and optimization reflect AWS’s commitment to passing on economies of scale to its customers, democratizing access to enterprise-grade storage.
Industry Standard and Enduring Compatibility
Perhaps one of S3’s most impactful contributions has been the establishment of its API as a de facto industry standard for object storage. Its simple, RESTful interface quickly gained traction, and over time, numerous other vendors and cloud providers have adopted or created S3-compatible storage tools and systems. This widespread adoption means that skills and tools developed for S3 are highly transferable across the broader storage landscape, fostering an open ecosystem and reducing vendor lock-in concerns for developers. The S3 API has become synonymous with scalable, resilient cloud storage, influencing countless architectural designs and software development practices.
A truly remarkable feat of engineering and product management is S3’s unwavering commitment to backward compatibility. Code written for S3 in 2006 continues to function seamlessly today, without modification. This means that data stored two decades ago remains accessible, having transparently traversed multiple generations of underlying infrastructure, disks, and storage systems. While the internal code handling requests has been entirely rewritten and optimized countless times, the external API contract has been meticulously maintained. This commitment to stability and compatibility allows customers to innovate without fear of breaking existing applications, a critical factor in building trust and fostering long-term adoption.
The Engineering Prowess Behind the Scale
Achieving and sustaining S3’s immense scale and reliability is a testament to continuous, cutting-edge engineering. Insights into this intricate process, often shared by AWS leaders like Mai-Lan Tomsen Bukovec, VP of Data and Analytics at AWS, highlight several key innovations:
- Lossless Durability via Microservices: At the core of S3’s 11 nines durability is a sophisticated system of microservices. These "auditor services" constantly inspect every byte across the entire fleet, vigilantly monitoring for any signs of data degradation. Upon detection, they automatically trigger repair systems, ensuring that data is re-replicated and integrity is maintained. The system is fundamentally designed to be lossless, meaning objects are not merely highly durable but are actively protected from loss.
- Formal Methods and Automated Reasoning: To guarantee correctness at such an unprecedented scale, S3 engineers employ formal methods and automated reasoning in production environments. This involves using mathematical proofs to verify the behavior of critical subsystems. For instance, when new code is introduced to the index subsystem, automated proofs rigorously confirm that consistency has not regressed. This same rigorous approach is applied to complex operations like cross-Region replication and for validating the correctness of access policies, providing an unparalleled level of assurance.
- Rust for Performance and Safety: Over the past eight years, AWS has progressively rewritten performance-critical code in the S3 request path using Rust. Components responsible for blob movement and disk storage have been re-engineered in Rust, with ongoing work across other critical parts. Beyond raw performance gains, Rust’s strong type system and memory safety guarantees eliminate entire classes of bugs at compile time. This is an indispensable property when operating a system with S3’s scale, correctness requirements, and the need for zero downtime.
- "Scale is to your advantage" Philosophy: S3’s design embodies a unique philosophy where increased scale inherently improves the service’s attributes for all users. The larger S3 grows, the more de-correlated individual workloads become across the vast infrastructure. This de-correlation enhances overall reliability and availability, as localized failures have a diminishing impact on the global service. This counter-intuitive design principle ensures that growth translates directly into a more robust and efficient system for every customer.
Broader Impact and Future Vision
The implications of S3’s two-decade journey extend far beyond mere data storage. It has profoundly impacted the entire cloud computing ecosystem, enabling the rapid growth of Software-as-a-Service (SaaS) applications, the rise of big data analytics, and the proliferation of serverless architectures. By abstracting away infrastructure complexities, S3 lowered the barrier to entry for innovation, allowing startups to compete on par with established enterprises and fostering an explosion of digital services. Industry analysts frequently cite S3 as a prime example of a foundational cloud service that democratized access to powerful computing resources, fueling economic growth and digital transformation across sectors. Developers worldwide have consistently praised its simplicity, robustness, and reliability, integrating it into virtually every modern application stack.
Looking forward, AWS envisions S3 as more than just a storage service; it is positioned to become the universal foundation for all data and AI workloads. This vision is predicated on a simple yet powerful premise: customers should store any type of data once in S3 and then work with it directly, without the need to move data between specialized, often expensive, systems. This approach dramatically reduces costs, eliminates operational complexity, and removes the need for multiple copies of the same data, which can introduce inconsistencies and security risks.
Recent innovations exemplify this strategic direction:
- S3 Select: Allows applications to retrieve only a subset of data from an object by using simple SQL expressions, significantly reducing data transfer costs and improving query performance.
- S3 Glacier and Deep Archive: Provides extremely low-cost storage for archival data, making it economically feasible to store vast historical datasets that were previously too expensive to retain.
- S3 Object Lambda: Enables developers to add their own code to process data as it is retrieved from S3, allowing for on-the-fly data transformation, redaction, or watermarking without altering the original object.
- Integration with Data Lakes and Analytics: S3 serves as the primary storage layer for data lakes, seamlessly integrating with services like Amazon Athena, Amazon Redshift Spectrum, and Amazon EMR, enabling powerful analytics directly on S3 data.
- Machine Learning Integrations: With the rise of AI, S3 has become the de facto repository for training datasets and machine learning model artifacts, integrating tightly with services like Amazon SageMaker.
Each of these capabilities operates within S3’s cost structure, making it economically viable to handle diverse data types and complex workloads that traditionally required expensive databases or specialized systems. From its humble beginnings as a 1-petabyte storage utility priced at 15 cents per gigabyte, to its current status as a hundreds-of-exabytes foundation for AI and analytics, priced at just 2 cents per gigabyte, S3 has consistently delivered on its promise. Through it all, the five fundamentals—security, durability, availability, performance, and elasticity—have remained steadfast, ensuring that code written in 2006 still functions perfectly today. As Amazon S3 embarks on its third decade, it continues to define the future of data, promising even greater innovation and impact for the digital world.
