
AWS has announced the launch of Amazon S3 Files, a groundbreaking new file system designed to seamlessly connect any AWS compute resource with Amazon Simple Storage Service (Amazon S3). This development marks a significant evolution in cloud storage, effectively dissolving the historical architectural chasm between highly scalable, cost-effective object storage and the interactive, hierarchical capabilities of traditional file systems. The introduction of S3 Files aims to simplify cloud architectures, eliminate data silos, and accelerate innovation across a spectrum of demanding workloads, from production applications to advanced machine learning models and emergent agentic AI systems.
A Decadal Divide Conquered: The Evolution of Cloud Storage
For over a decade, cloud architects and developers have grappled with the fundamental differences between object storage and file systems. Object storage, exemplified by Amazon S3, offers unparalleled scalability, durability, and cost-efficiency, treating data as immutable objects stored in a flat namespace. This model is ideal for vast data lakes, backups, and static content. In contrast, file systems provide a familiar hierarchical structure, enabling byte-range edits, random access, and concurrent modifications—essential for interactive applications, operating systems, and many traditional workloads. The challenge often lay in moving or synchronizing data between these distinct storage types, leading to architectural complexity, data duplication, and operational overhead.
The announcement of S3 Files directly addresses this long-standing dilemma. By transforming S3 buckets into fully-featured, high-performance file systems, AWS is now offering the first and only cloud object store with native file system access. This innovation means that organizations no longer have to choose between the robust economics and resilience of S3 and the interactive flexibility of a file system. Instead, S3 can now serve as a truly central hub for all organizational data, accessible directly from any AWS compute instance, container, or function.

Unlocking New Capabilities with High-Performance File System Access
Amazon S3 Files extends the capabilities of S3 by presenting S3 objects as files and directories, supporting all Network File System (NFS) v4.1+ operations. This includes the ability to create, read, update, and delete files, bringing a familiar POSIX-like interface directly to S3 data. This level of compatibility is crucial for legacy applications or tools that are hard-coded to interact with file systems.
A core technical innovation behind S3 Files is its intelligent tiered storage approach. As users interact with specific files and directories, associated file metadata and contents are automatically moved to a high-performance storage layer. This layer, leveraging the underlying technology of Amazon Elastic File System (Amazon EFS), delivers ultra-low latencies, typically around 1 millisecond, for active data. This ensures that frequently accessed data benefits from the responsiveness expected of a local file system.
However, S3 Files is also optimized for cost and performance across diverse access patterns. For files not requiring sub-millisecond latency, such as those involved in large sequential reads (common in data analytics or media processing), S3 Files intelligently serves data directly from Amazon S3. This maximizes throughput by avoiding unnecessary caching and ensures that the cost benefits of S3 are retained for appropriate workloads. Furthermore, for byte-range reads, only the requested bytes are transferred, minimizing data movement and associated costs, a critical feature for applications processing large files incrementally. The system also incorporates intelligent pre-fetching capabilities, anticipating data access needs to further optimize performance. Users retain fine-grained control over this caching behavior, deciding whether to load full file data or metadata only, tailoring the system to specific access patterns and budget constraints.
Seamless Integration Across the AWS Compute Ecosystem

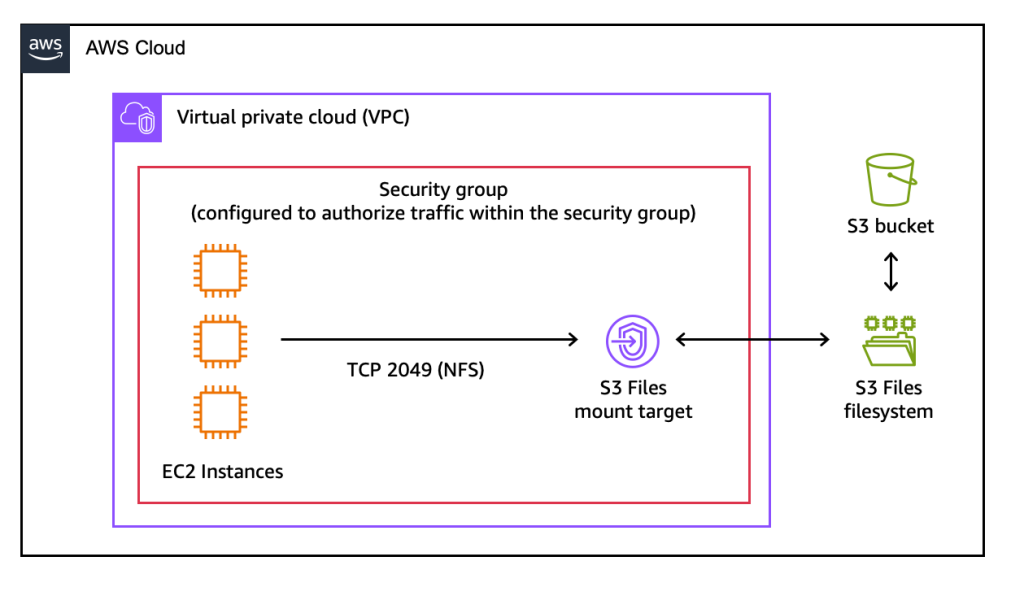
The versatility of S3 Files is underscored by its broad integration across the AWS compute landscape. It can be mounted as a native file system on Amazon Elastic Compute Cloud (Amazon EC2) instances, enabling traditional server-based applications to interact directly with S3 data. Containerized workloads running on Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS) can also leverage S3 Files, simplifying data management for microservices and scalable applications. Even ephemeral, event-driven AWS Lambda functions can access S3 data through this file system interface, broadening the scope of serverless architectures.
This extensive integration is particularly beneficial for shared, interactive workloads that involve data mutation. For instance, agentic AI systems, which often rely on file-based Python libraries and command-line tools, can now collaborate through shared file systems backed by S3, eliminating the need for complex data synchronization mechanisms. Similarly, machine learning training pipelines, which frequently process and modify large datasets, can use S3 Files to provide concurrent access from multiple compute resources with NFS close-to-open consistency. This consistency model ensures that data changes are reliably propagated and visible across all connected compute instances, making it ideal for collaborative data processing.
Practical Implementation and Operational Simplicity
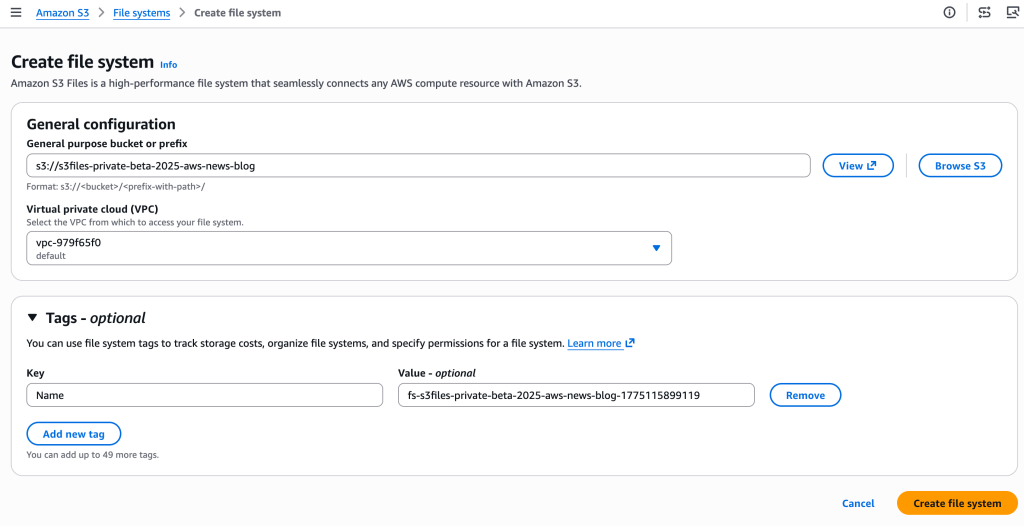
Getting started with Amazon S3 Files is designed to be straightforward. The AWS Management Console provides a user-friendly interface to create an S3 file system by simply specifying an existing S3 bucket. The console automatically provisions the necessary network endpoints (mount targets) within the user’s Virtual Private Cloud (VPC), allowing EC2 instances or other compute resources to access the file system. For automation and infrastructure-as-code deployments, the AWS Command Line Interface (CLI) and APIs offer equivalent functionality.
Once created, mounting the S3 file system on an EC2 instance, for example, is as simple as executing a standard mount command. Users can then interact with their S3 data using familiar file system commands (ls, cp, echo, rm), with changes automatically reflected back in the S3 bucket. Updates made via the file system are exported as new objects or new versions of existing objects in S3 within minutes, ensuring data durability and versioning. Conversely, changes made directly to objects in the S3 bucket become visible in the mounted file system within seconds to a minute, maintaining a high degree of synchronization. This bidirectional synchronization is a critical component, ensuring data consistency regardless of the access method.
Differentiating AWS File Services: S3 Files, EFS, and FSx
The introduction of S3 Files adds a new dimension to AWS’s already comprehensive suite of file storage services. Understanding the optimal use case for each service is crucial for architects.
-
Amazon S3 Files: This service is best suited for workloads that require interactive, shared access to data primarily residing in Amazon S3, through a high-performance file system interface. It excels in scenarios where multiple compute resources—such as production applications, agentic AI agents leveraging Python libraries and CLI tools, or ML training pipelines—need to collaboratively read, write, and mutate data. Its key advantages are shared access across compute clusters without data duplication, sub-millisecond latency for active data, and automatic synchronization with the S3 bucket. It is particularly valuable for hybrid object/file access patterns, where the underlying data source is S3.
-
Amazon Elastic File System (EFS): EFS provides a simple, scalable, elastic, shared file system for Linux workloads, typically used for general-purpose file storage, lift-and-shift migrations of Linux-based applications, web serving, content management, and development environments. Unlike S3 Files, EFS provides consistent low-latency access for all data within the file system, not just active data. It’s fully managed and automatically scales to petabytes, growing and shrinking as files are added and removed, without provisioning storage capacity. EFS is ideal when a pure, high-performance NFS file system is required without the direct integration and object semantics of S3.
-
Amazon FSx: Amazon FSx offers fully managed third-party file systems with native compatibility and feature sets. It is designed for workloads requiring specific file system capabilities that are not available in EFS or S3 Files.
- Amazon FSx for Windows File Server is optimized for Windows-based applications, providing full support for the SMB protocol, Active Directory integration, and familiar Windows features. It is often used for lift-and-shift of Windows applications and user home directories.
- Amazon FSx for Lustre is a high-performance file system optimized for compute-intensive workloads like high-performance computing (HPC), machine learning, financial simulations, and electronic design automation. It delivers very high throughput and low latency for large datasets.
- Amazon FSx for NetApp ONTAP provides the familiar features and operational experience of NetApp ONTAP file systems, including advanced data management capabilities like snapshots, replication, and data deduplication, appealing to enterprises with existing ONTAP expertise.
- Amazon FSx for OpenZFS offers high-performance, open-source-based file storage with ZFS features like data compression, snapshots, and cloning, suitable for general-purpose NAS and high-performance applications.
FSx services are chosen when applications require specific file system semantics, protocols, or advanced data management features.
Market Implications and Broader Impact
The introduction of Amazon S3 Files is poised to have significant implications across the cloud computing landscape. For customers, it offers a tangible simplification of cloud architectures. By enabling S3 to serve as a unified data repository accessible via both object and file interfaces, it eliminates the need for complex data movement pipelines, specialized gateways, or application-level workarounds that were previously required to bridge the gap between object and file storage. This reduction in architectural complexity translates directly into lower operational costs and faster development cycles.
Industry analysts suggest that this move strategically strengthens AWS’s position in the evolving cloud storage market, particularly as data-intensive workloads like AI and machine learning continue to proliferate. The ability to seamlessly integrate the cost-effectiveness and scalability of S3 with the interactive performance of a file system is a powerful proposition for organizations building the next generation of intelligent applications. It also provides a robust answer to similar offerings from competing cloud providers, ensuring AWS maintains its competitive edge in diverse enterprise scenarios.
Moreover, S3 Files could accelerate the adoption of hybrid cloud strategies. Enterprises with significant on-premises investments in file-based applications can now more easily integrate their workflows with cloud-based S3 data, without extensive re-architecting. This facilitates smoother migrations and enables new hybrid operational models where data can be processed on-premises and then archived or accessed in S3 via a familiar file interface.
From a data governance and compliance perspective, centralizing data in S3 via S3 Files offers benefits. S3’s robust security features, data encryption, access controls, and compliance certifications automatically extend to data accessed through the file system interface. This simplifies adherence to regulatory requirements and strengthens overall data security posture.
Pricing and Availability
Amazon S3 Files is available immediately in all commercial AWS Regions, providing global accessibility for customers. The pricing model is designed to be transparent and consumption-based, aligning with AWS’s pay-as-you-go philosophy. Customers incur costs for the portion of data stored in their S3 file system’s high-performance storage layer, for small file read and all write operations performed against the file system, and for S3 requests associated with data synchronization between the file system and the underlying S3 bucket. Detailed pricing information, including specific rates for storage, operations, and data transfer, is available on the Amazon S3 pricing page, allowing organizations to accurately forecast and optimize their cloud storage expenditures.
In conclusion, Amazon S3 Files represents a pivotal advancement in cloud storage. By offering fully-featured, high-performance file system access to Amazon S3 data, AWS is enabling organizations to simplify their cloud architectures, eliminate data silos, and foster greater innovation. Whether supporting existing production tools, powering next-generation agentic AI systems, or streamlining machine learning data pipelines, S3 Files empowers customers to leverage the unparalleled durability and cost benefits of Amazon S3, coupled with the interactive capabilities of a traditional file system, creating a truly unified and versatile data platform. This strategic offering underscores AWS’s commitment to continually evolving its services to meet the increasingly complex demands of modern cloud workloads.
