
Traditional enterprise software, built on a foundation of rigid "If-Then" statements, struggles to adapt to the dynamic nature of modern business. This inherent brittleness, where a single change in business conditions can cause system failures, has historically been addressed through laborious manual data reconciliation and analysis, consuming thousands of human hours. The advent of AI-Native applications presents a paradigm shift, moving beyond "Software 1.0" with its fixed logic to "Software 2.0," characterized by learned logic. This is not merely about integrating AI as an add-on, such as a chatbot, but fundamentally rebuilding enterprise architecture around AI to enable unprecedented adaptability, efficiency, and intelligence.
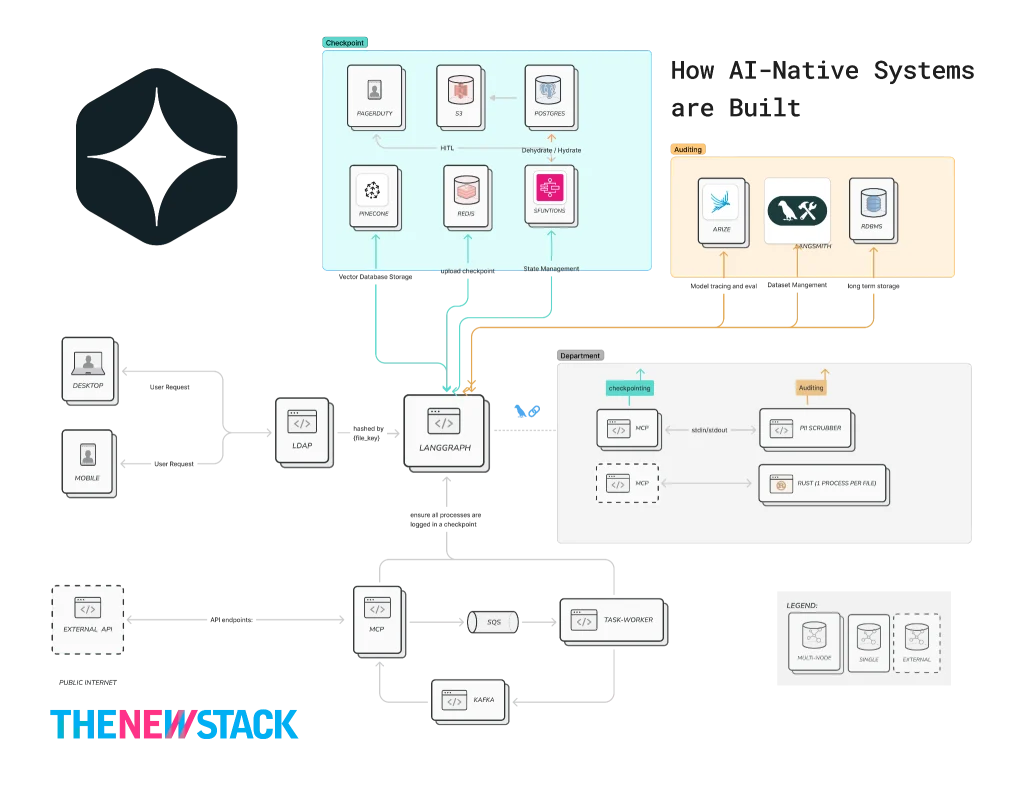
This transformation requires a sophisticated, layered approach to ensure that AI-Native applications can operate effectively without compromising critical aspects like compliance and security. The following architectural breakdown illustrates how organizations can navigate this complex transition, moving from brittle, deterministic systems to resilient, AI-driven platforms.
Layer 0: The Deterministic Shield (Governance & Identity): AIMS
The fundamental goal of this foundational layer is to establish a robust governance framework that ensures AI operations never violate corporate policies, irrespective of the Large Language Model’s (LLM) output. This "deterministic shield" acts as a critical safeguard, particularly when dealing with sensitive information.
Governance in this context must be model-agnostic. This means that the rules governing data handling, such as Personally Identifiable Information (PII) policies, should remain consistent even if the underlying AI model is switched from one provider to another, for instance, from Claude to Gemini. Achieving this model-agnostic governance is facilitated by implementing "Pre-Processing" and "Post-Processing" gateways. These gateways act as critical control points, ensuring that sensitive data is never exposed to third-party APIs during inbound requests and that the AI itself does not inadvertently leak confidential internal information in its outbound responses.
This layer is crucial for maintaining trust and security in AI-driven processes. By meticulously controlling data flow and enforcing policy adherence at the ingress and egress points of AI interactions, organizations can mitigate significant risks associated with AI adoption.
# The Inbound Gate
@app.post("/gateway/query")
async def inbound_shield(
request: UserRequest,
principal: Principal = Depends(verify_jwt)
):
user_id = principal.sub
user_role = await asyncio.to_thread(ldap.get_role, user_id)
clean_query = scrubber.redact(request.text)
trace_id = generate_otel_trace()
try:
await kafka.produce_and_flush(
"inbound_queries",
"trace_id": trace_id,
"query": clean_query,
"role": user_role,
,
timeout=5
)
except Exception as e:
logger.error("Kafka enqueue failed | trace=%s err=%s", trace_id, e)
raise HTTPException(status_code=503, detail="Queue unavailable")
return "status": "queued", "trace_id": trace_idThis code snippet exemplifies the inbound gateway’s functionality. It receives a user request, identifies the user and their role, redacts any sensitive information from the query, generates a trace ID for observability, and then queues the cleaned query for further processing. This proactive sanitization is fundamental to Layer 0’s objective.
Layer 1: The Orchestration Layer
The primary objective of Layer 1 is to evolve from a simple "Stateless Chat" interaction to a "Stateful Business Process." This is achieved through an orchestration layer that manages the complex flow of information and decision-making within AI-Native systems.
Unlike traditional applications where logic is hard-coded and inflexible, AI-Native systems leverage orchestration tools like LangChain. These tools enable the management of "chains of thought," allowing AI agents to perform multi-step reasoning and execute complex tasks.
A key component in optimizing AI inference costs and performance within this layer is the use of a Classifier, often powered by a Small Language Model (SLM). High-end LLMs, while powerful, can be expensive and slow. An SLM acts as an intelligent "Triage Nurse," analyzing incoming queries to determine their complexity. It can identify simple requests that can be handled by deterministic scripts, complex queries requiring generative AI, or those that necessitate human intervention. By routing simple tasks to more cost-effective compute resources, this triage mechanism can lead to significant savings, potentially up to 80% in inference costs.
To ensure auditability and maintain data integrity, a Custom Checkpointer is essential. Instead of relying solely on transient memory, this logic ensures that every interaction turn, every decision point, is durably persisted to a permanent database. This provides a granular record of the AI’s reasoning process, crucial for compliance and debugging.
import json
import os
from langgraph.checkpoint.base import BaseCheckpointSaver
class EnterpriseAuditSaver(BaseCheckpointSaver):
def put(self, config, checkpoint, metadata):
"""
Ensure every checkpoint write is durably persisted
BEFORE allowing graph progression (fail-closed for audit integrity).
"""
thread_id = config["configurable"]["thread_id"]
checkpoint_id = checkpoint["id"]
try:
s3.put_object(
Bucket=os.getenv("AUDIT_BUCKET"),
Key=f"thread_id/checkpoint_id.json",
Body=json.dumps(checkpoint, default=str),
ServerSideEncryption="aws:kms",
)
db.execute(
"""
INSERT INTO traces (thread_id, checkpoint_id, state_blob)
VALUES (%s, %s, %s)
""",
(thread_id, checkpoint_id, json.dumps(checkpoint, default=str))
)
except Exception as e:
logger.exception(
"Audit write failed | thread=%s checkpoint=%s error=%s",
thread_id,
checkpoint_id,
str(e)
)
raise
return super().put(config, checkpoint, metadata)
# Compile graph
# checkpointer = EnterpriseAuditSaver()
# app = workflow.compile(checkpointer=checkpointer)The EnterpriseAuditSaver class demonstrates a robust approach to checkpointing. It ensures that every state change is written to both S3 (for durable, encrypted storage) and a relational database (for queryable audit logs) before the AI’s process continues. This "fail-closed" mechanism guarantees that no audit data is lost, reinforcing the system’s reliability and compliance posture.
import os
COMPLEXITY_THRESHOLD = int(os.getenv("COMPLEXITY_THRESHOLD", "7"))
CONFIDENCE_THRESHOLD = float(os.getenv("CONFIDENCE_THRESHOLD", "0.95"))
MODEL_REGISTRY =
"high": "claude-sonnet-4-5",
"low": "gpt-4o-mini"
def estimate_confidence(response):
"""
Confidence must be derived, not assumed.
Options in production:
- logprob aggregation
- self-critique model
- external evaluator model
"""
return getattr(response, "logprob_score", 0.8)
def call_model(state: GraphState):
if state["complexity"] > COMPLEXITY_THRESHOLD:
model = MODEL_REGISTRY["high"]
else:
model = MODEL_REGISTRY["low"]
response = llm.invoke(state["prompt"], model=model)
confidence = estimate_confidence(response)
if confidence < CONFIDENCE_THRESHOLD:
return "trigger_dehydration"
return "finalize_result"
# Define graph
workflow = StateGraph(GraphState)
workflow.add_node("reasoning", call_model)
workflow.add_edge("reasoning", "tools")This Python code illustrates the dynamic model selection based on query complexity. It also incorporates a confidence estimation mechanism, allowing the system to re-evaluate or pause processing if the AI’s confidence in its output falls below a predefined threshold. This proactive error handling is a hallmark of intelligent AI systems.
Layer 2: The Persistence Spine
Layer 2 focuses on making the AI-Native system "asynchronous and durable," ensuring that no data is lost even in the event of system failures. This layer acts as the "Nervous System" of the AI architecture.
If an AI orchestrator container were to crash mid-process, the message or task state would remain intact within a persistent message queue, such as Kafka. Upon restart, the container would seamlessly resume processing from the exact point of interruption. This robust messaging infrastructure provides a guarantee of "Zero Data Loss," a critical requirement for enterprise-grade applications.

import json
import os
import re
import boto3
s3_client = boto3.client("s3")
THREAD_ID_PATTERN = re.compile(r"[A-Za-z0-9_-]1,64")
def _validate_thread_id(thread_id: str) -> str:
if not isinstance(thread_id, str) or not THREAD_ID_PATTERN.fullmatch(thread_id):
raise ValueError(f"Invalid thread_id: thread_id!r")
return thread_id
def dehydrate_to_s3(state, task_token, thread_id):
"""
Serializes the AI state and pauses execution.
Security:
- Validates thread_id to prevent path traversal / tenant escape
- Encrypts state at rest
"""
thread_id = _validate_thread_id(thread_id)
bucket = os.environ["AI_STATE_BUCKET"]
checkpoint_key = f"checkpoints/thread_id/state.json"
try:
s3_client.put_object(
Bucket=bucket,
Key=checkpoint_key,
Body=json.dumps(state, default=str),
ServerSideEncryption="aws:kms",
)
# db.update_metadata(thread_id, status="WAITING_FOR_HUMAN", #s3_ptr=checkpoint_key)
print(f"Pausing workflow. Task Token: task_token")
except Exception as e:
logger.exception("Dehydration failed | thread=%s err=%s", thread_id, e)
raise
return "status": "DEHYDRATED", "s3_ptr": checkpoint_keyThe dehydrate_to_s3 function exemplifies this persistence. When a process needs to be paused, perhaps awaiting human input, its current state is serialized and securely stored in S3. This "dehydration" process ensures that the AI’s context is preserved, allowing for seamless resumption later. The validation of thread_id is a crucial security measure to prevent unauthorized access or manipulation of data across different tenants or user sessions.
This "split" strategy, utilizing both S3 for object storage and a Relational Database Management System (RDBMS) for structured metadata, offers a powerful combination of scalability, cost-effectiveness, and data integrity. S3 excels at storing large, unstructured data blobs (like AI states or audit logs) cost-effectively, while RDBMS is ideal for managing transactional data, relationships, and complex queries.
When human interaction is required, such as a "Click Approve" from a Human-In-The-Loop (HITL) interface, a dedicated Lambda function is triggered. This function, responsible for "Rehydration," retrieves the saved AI state from S3, incorporates the human input, and then signals the AI process to resume.
import json
import os
import re
import boto3
s3_client = boto3.client("s3")
sfn_client = boto3.client("stepfunctions")
THREAD_ID_PATTERN = re.compile(r"[A-Za-z0-9_-]1,64")
def _validate_thread_id(thread_id: str) -> str:
if not isinstance(thread_id, str) or not THREAD_ID_PATTERN.fullmatch(thread_id):
raise ValueError(f"Invalid thread_id: thread_id!r")
return thread_id
def rehydrate_and_resume(event, context):
"""
Triggered by Human UI (via authenticated API).
Security:
- Validates inputs
- Authorizes approver
- Prevents token replay
- Uses encrypted state
"""
try:
task_token = event["task_token"]
human_input = event["human_decision"]
thread_id = _validate_thread_id(event["thread_id"])
approver_id = event["approver_id"]
except KeyError as e:
return "statusCode": 400, "body": f"Missing field: e"
except ValueError as e:
return "statusCode": 400, "body": str(e)
if not authz.can_approve(approver_id, thread_id):
logger.warning(
"Unauthorized approval attempt | approver=%s thread=%s",
approver_id,
thread_id,
)
return "statusCode": 403, "body": "Not authorized"
if not token_store.matches(thread_id, task_token):
return "statusCode": 409, "body": "Stale or invalid task token"
bucket = os.environ["AI_STATE_BUCKET"]
key = f"checkpoints/thread_id/state.json"
try:
# Retrieve the frozen state from S3
obj = s3_client.get_object(Bucket=bucket, Key=key)
frozen_state = json.loads(obj["Body"].read())
# Append human input and update status
frozen_state.setdefault("messages", []).append(
"role": "human", "content": human_input
)
frozen_state["status"] = "RESUMED"
frozen_state["approved_by"] = approver_id
# Invalidate the task token to prevent replay
token_store.invalidate(thread_id, task_token)
# Signal the Step Functions workflow to resume
sfn_client.send_task_success(
taskToken=task_token,
output=json.dumps(frozen_state, default=str),
)
except Exception as e:
logger.exception("Rehydration failed | thread=%s err=%s", thread_id, e)
return "statusCode": 500, "body": "Rehydration failed"
return "statusCode": 200, "body": "AI rehydrated and processing"This rehydrate_and_resume function highlights critical security measures: input validation, authorization checks for the approver, and token validation to prevent replay attacks. By securely managing the state and control flow, this layer ensures that the AI system can be paused, modified by human input, and resumed reliably, maintaining operational continuity and data integrity.
Layer 3: Auditing & Observability
The objective of Layer 3 is to transform the "black box" nature of AI decision-making into a transparent, auditable business metric. This layer provides the necessary tools and processes for understanding, monitoring, and verifying AI behavior.
While standard LangGraph checkpointers are designed for recovery, an audit-ready checkpointer goes further. It mirrors the AI’s state to durable storage (S3 or RDS) alongside rich metadata. This metadata includes crucial context such as who made a decision, when it was made, and why it was made, providing a comprehensive audit trail at every significant "super-step" of the AI’s execution.
from typing import Annotated, TypedDict, List
from operator import add
class AuditEntry(TypedDict):
node: str
thought: str
timestamp: str
metadata: dict
class AgentState(TypedDict):
# 'add' ensures we append to the history rather than overwriting
messages: Annotated[List[dict], add]
audit_log: Annotated[List[AuditEntry], add]
internal_monologue: List[str] # Current thought process
status: strThis AgentState definition shows how audit information is structured within the AI’s state. The audit_log field is specifically designed to capture detailed entries at each stage of the AI’s reasoning process, providing a granular history of its actions and thoughts.
The implementation of an "Observer" pattern within LangGraph allows dedicated nodes to report their "thoughts" and actions both before and after execution. This creates a detailed log of the AI’s internal processes, which can then be persisted for auditing and analysis.
import datetime
from langgraph.graph import StateGraph, START, END
def reasoning_node(state: AgentState):
# Logic: The AI 'thinks' before acting
thought = "I need to check the inventory levels before approving the CEO's request."
# Audit log entry
audit =
"node": "reasoning_node",
"thought": thought,
"timestamp": datetime.datetime.now(datetime.timezone.utc).isoformat(),
"metadata": "model": "claude-3-5-sonnet", "tokens": 450
# Perform the actual logic...
result = "Searching DB..."
return
"internal_monologue": [thought],
"audit_log": [audit],
"messages": ["role": "assistant", "content": result]
# The 'Audit Hook' Node
def audit_persistence_node(state: AgentState):
"""
This node acts as a gateway to long-term storage.
It 'dehydrates' the current audit trail to S3.
"""
latest_audit = state["audit_log"][-1]
# In practice, call your S3/RDS logic here
# s3.upload_json(latest_audit, key=f"audits/trace_id/step.json")
print(f"[AUDIT LOGGED]: Node latest_audit['node'] completed.")
return stateThe reasoning_node function, when augmented with the audit_persistence_node, demonstrates how each logical step of the AI’s process is captured. The audit dictionary stores detailed information about the AI’s "thought" process and the associated metadata. The audit_persistence_node then ensures this information is logged to a durable store.
Tools like LangSmith, which integrates natively with LangChain, offer advanced features for tracing and observability. By using Custom Annotations, developers can tag specific parts of the AI’s chain of thought, making it easily searchable and filterable within the observability platform. This granular level of detail is invaluable for debugging complex AI workflows and ensuring accountability.
from langsmith import traceable
from langchain_openai import ChatOpenAI
from config import settings # your centralized config
@traceable(
run_type="chain",
name="Inventory_Reasoning_Step",
metadata=
"department": "logistics",
"priority": "high"
)
def reasoning_node(state):
"""
Production-safe reasoning node:
- No environment mutation
- No chain-of-thought leakage
- Structured reasoning context instead
"""
reasoning_context =
"intent": "inventory_analysis",
"data_source": "s3+rds",
"request_origin": "ceo_query"
data = state.get("data", "")
if not isinstance(data, str):
data = str(data)
safe_data = data[:5000] # prevent excessive token usage
llm = ChatOpenAI(model="gpt-4o")
response = llm.invoke(
f"Analyze the following structured data:nsafe_data"
)
return
"messages": [response],
"reasoning_context": reasoning_context
The @traceable decorator from LangSmith automatically instruments the reasoning_node function. It captures detailed information about the execution, including the input, output, and any associated metadata. This makes it possible to visualize the entire chain of thought and analyze performance metrics within the LangSmith platform.
Furthermore, tools like Arize Phoenix can act as an "Automated Compliance Officer." By tracing AI executions, Phoenix can run "Judgments" – automated evaluations – to detect issues like hallucinations. This proactive monitoring is essential for maintaining the integrity and reliability of AI systems in production.
import phoenix as px
from phoenix.otel import register
from openinference.instrumentation.langchain import LangChainInstrumentor
# 1. Launch Phoenix (local or cloud)
session = px.launch_app()
# 2. Register the OTel tracer (This is your OTel Spine)
tracer_provider = register(
project_name="AI-Native-Enterprise",
endpoint="http://localhost:6006/v1/traces" # Your Phoenix Collector
)
# 3. Instrument LangChain/LangGraph
# Every node execution now streams to Phoenix automatically
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)
# 4. Example: LLM-as-a-Judge (Hallucination Detection)
from phoenix.evals import HallucinationEvaluator, OpenAIModel, run_evals
# We run this on a schedule or after a HITL rehydration event
evaluator = HallucinationEvaluator(model=OpenAIModel(model="gpt-4o"))
results = run_evals(
dataframe=px.active_session().get_spans_dataframe(),
evaluators=[evaluator],
provide_explanation=True
)The Phoenix instrumentation code sets up a robust observability pipeline. It launches the Phoenix application, registers an OpenTelemetry tracer, and then instruments LangChain/LangGraph. This ensures that every execution trace is automatically streamed to Phoenix. The subsequent example demonstrates how to leverage Phoenix’s evaluation capabilities, such as a HallucinationEvaluator, to automatically assess the quality and accuracy of AI outputs. This is crucial for maintaining trust and compliance in AI-driven decision-making.
Organizational Impact
The implementation of AI-Native applications represents a significant shift in the workforce’s role. Employees transition from being mere "Task Performers" to becoming "AI-Native System Governors." This evolution requires new skill sets, focusing on overseeing, managing, and validating AI operations, rather than executing repetitive tasks.
The ultimate outcome of adopting this layered, AI-Native architecture is an organization that can operate with the speed and agility of AI for the vast majority of its tasks, estimated at 95%. Crucially, this enhanced efficiency does not come at the expense of security or compliance. For the remaining high-stakes 5% of operations, the system retains robust human oversight and verification, ensuring that critical decisions are made with both AI-driven intelligence and human judgment. This balanced approach allows businesses to harness the transformative power of AI while maintaining the highest standards of operational integrity and risk management.
