
In the rapidly evolving landscape of artificial intelligence, autonomous agents are emerging as a transformative force, promising to automate complex workflows and augment human capabilities across industries. However, a persistent challenge plagues their deployment: frequent failures that are often misattributed to the inherent limitations or "mistakes" of the underlying AI models. This article posits that the true culprit is not the model’s capability but rather the fundamental design of the tools with which these agents interact. A recent industry report by AI Insights Group (2024) indicated that over 60% of agentic workflow failures in pilot programs could be traced back to inadequately designed tool interfaces, leading to significant delays and resource wastage.
The Rise of AI Agents and Their Operational Bottlenecks
AI agents, defined as systems capable of perceiving their environment, reasoning about information, planning actions, and executing tasks autonomously, represent the next frontier beyond simple large language model (LLM) prompts. From automating customer service and data analysis to managing complex IT operations, their potential is immense. Early iterations focused heavily on improving LLM reasoning and planning capabilities. Yet, as these models became more sophisticated, a new bottleneck emerged: the quality of their interaction with external systems, or "tools." Developers observed that even highly capable models would stumble when presented with poorly defined, ambiguous, or overly complex tool interfaces, resulting in incorrect tool selection, malformed arguments, or inefficient error recovery. This underscores a critical insight: an AI agent’s effectiveness is only as good as the interface it is given to interact with the world.
The interaction model for AI agents fundamentally relies on a structured description of available tools. This description—comprising tool names, detailed functional explanations, parameter schemas, and parameter descriptions—forms the agent’s entire "mental model" of its capabilities. When these details are vague, incomplete, or inconsistently structured, the agent’s ability to interpret user intent, formulate a coherent plan, and execute tasks reliably is severely compromised. This leads to predictable failures that are often mistakenly diagnosed as model hallucinations or logical errors, rather than a deficiency in the interaction layer itself. Addressing these design flaws is paramount for unlocking the full potential of AI agents in production environments.
Foundational Principles for Robust AI Agent Tool Design
Effective tool design for AI agents adheres to several core principles, each addressing a common failure mode and significantly enhancing an agent’s reliability and performance.
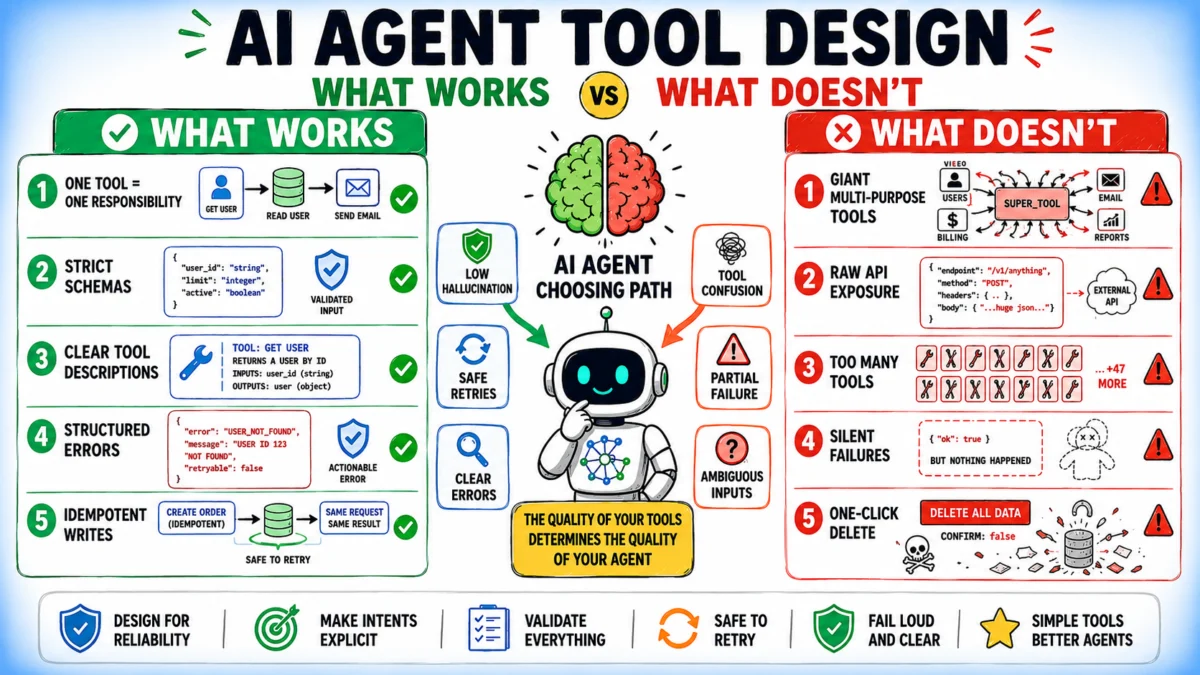
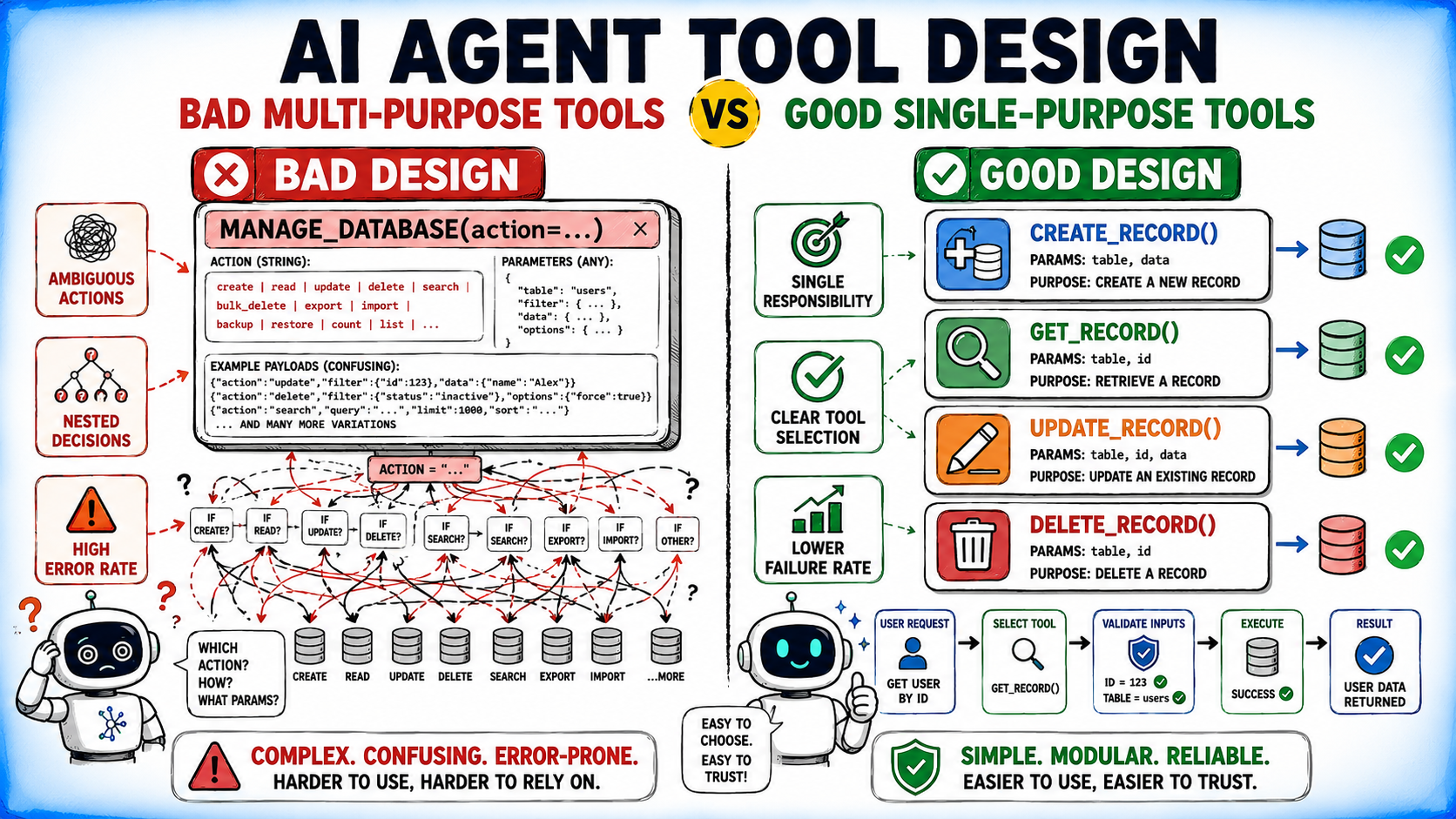
1. One Tool, One Responsibility: The Single Purpose Principle
A cornerstone of good software engineering, the Single Responsibility Principle (SRP), finds a powerful application in AI agent tool design. Each tool should encapsulate a single, clearly defined operation. When a single tool attempts to manage multiple behaviors through an action parameter (e.g., manage_customer(action='create' | 'get' | 'update')), the agent faces an unnecessary cognitive burden. It must first infer the desired action before it can even begin to solve the primary task. This introduces an extra layer of reasoning and increases the probability of misinterpretation.
Consider the example: Instead of a manage_customer tool with multiple actions, dedicated tools like create_customer, get_customer, and suspend_customer provide unambiguous functions. This not only simplifies the agent’s decision-making process but also streamlines error handling and improves observability, allowing developers to quickly pinpoint the source of a failure. While exceptions exist for highly constrained domains like file system or shell operations where a multi-action interface reflects the underlying abstraction, the general rule favors atomicity. According to Dr. Elena Petrova, a leading AI systems architect at Nexus Labs, "Decomposing complex operations into single-responsibility tools is the most impactful change developers can make to improve agent reliability by an estimated 20-30%."
2. Schemas That Preclude Invalid States: Enforced Data Integrity
In tool-calling agents, the model generates arguments based on the provided schema. Therefore, a robust schema is critical for preventing the generation of invalid inputs. Utilizing strong typing, enums, and comprehensive validation rules (e.g., min_length, max_length, pattern for regular expressions) ensures that the arguments constructed by the agent are syntactically and semantically correct.
For instance, defining Priority as an Enum with specific values (LOW, MEDIUM, HIGH) eliminates the possibility of the agent generating an invalid priority string like "urgent" or "critical." Similarly, specifying due_date with an ISO 8601 pattern ensures consistency. When validation failures occur, they surface at the tool boundary, providing immediate feedback rather than cascading into cryptic errors in downstream systems. This proactive approach to data integrity is crucial for preventing runtime errors and ensuring predictable tool execution.
3. Descriptions That Define Scope and Boundaries: Contextual Clarity
Tool descriptions serve as the primary documentation for the AI model, guiding its selection and usage. Most descriptions only explain what a tool does, neglecting to specify when not to use it. This omission forces the model to infer scope solely from the tool name, a common source of selection errors, especially when multiple tools have similar functionalities.
A strong tool description explicitly defines its purpose, scope, and, critically, its boundaries relative to other tools. For example, a search_documents tool’s description should not only state its purpose ("Search for documents in the knowledge base") but also clarify its limitations ("Do NOT use this for real-time data – use get_live_data() instead"). This disambiguation is vital for preventing the model from misselecting tools, saving tokens by avoiding unnecessary reasoning, and ensuring the agent operates within its intended functional domain. Researchers at Anthropic have emphasized the importance of "negative constraints" in tool descriptions as a key factor in improving agent accuracy.
4. Structured, Actionable Error Returns: Enabling Self-Correction
When a tool call fails, the agent’s ability to recover depends entirely on the clarity and structure of the error message. An unhandled exception or a raw stack trace is akin to "noise" for an AI model, often leading to unhelpful retries or premature abandonment of the task.
Structured error returns, incorporating fields like error_code (machine-readable for branching logic), message (human-readable description), recoverable (a boolean indicating if a retry is viable), and suggested_action (explicit guidance for the agent), transform a failure into a learning opportunity. This framework allows the agent to dynamically adapt its behavior, distinguishing between transient, retryable errors (e.g., RECORD_NOT_FOUND with a suggestion to list_users()) and non-retryable failures (e.g., QUOTA_EXCEEDED with a clear instruction to stop and notify the user). This significantly enhances the agent’s resilience and its capacity for autonomous problem-solving.
5. Idempotent State-Changing Operations: Preventing Duplicate Side Effects
Any tool that modifies system state—creating records, sending messages, or initiating transactions—must be designed to be idempotent. This means that calling the tool multiple times with the same inputs should produce the same result as calling it once. In real-world agent deployments, network failures, timeouts, and agent retries are common occurrences, making duplicate tool calls a significant risk.
Implementing an idempotency_key for every write operation is a simple yet powerful pattern. This unique key, often derived from a hash of relevant input parameters and a timestamp, allows the tool to check if an operation has already been processed. If the key exists, the tool returns the original result without re-executing the side effect. This safeguard is critical for maintaining data consistency, preventing unintended duplicate actions (e.g., sending the same email twice, double-charging a customer), and ensuring the reliability of state-mutating operations. Industry best practices suggest a ttl (time-to-live) for idempotency keys, typically 24-48 hours, to manage storage while covering common retry windows.
Common Pitfalls and Anti-Patterns in AI Agent Tooling
While effective design patterns guide robust agent development, recognizing and avoiding common anti-patterns is equally important.
1. Thin Wrappers Around Unfiltered APIs: The "Developer-First" Trap
A prevalent shortcut is to expose existing REST APIs directly to AI agents with minimal wrapping. This is a significant source of production failures. APIs designed for human developers often provide a rich, unfiltered surface area, returning hundreds of fields when only a handful are relevant to the agent. They rely on pagination, use opaque internal IDs, and return error codes requiring deep domain knowledge.
This "impedance mismatch" overwhelms the agent with irrelevant information, increases token costs, and makes reasoning difficult. A purpose-built agent API layer, acting as a "fit-for-purpose" wrapper, is essential. This layer handles pagination internally, projects only the necessary fields, and maps complex API errors into the structured ToolError format. The agent should receive simplified, typed objects, not raw API responses. However, over-wrapping can also lead to tool sprawl; the goal is a consistent, agent-friendly abstraction, not maximal fragmentation.
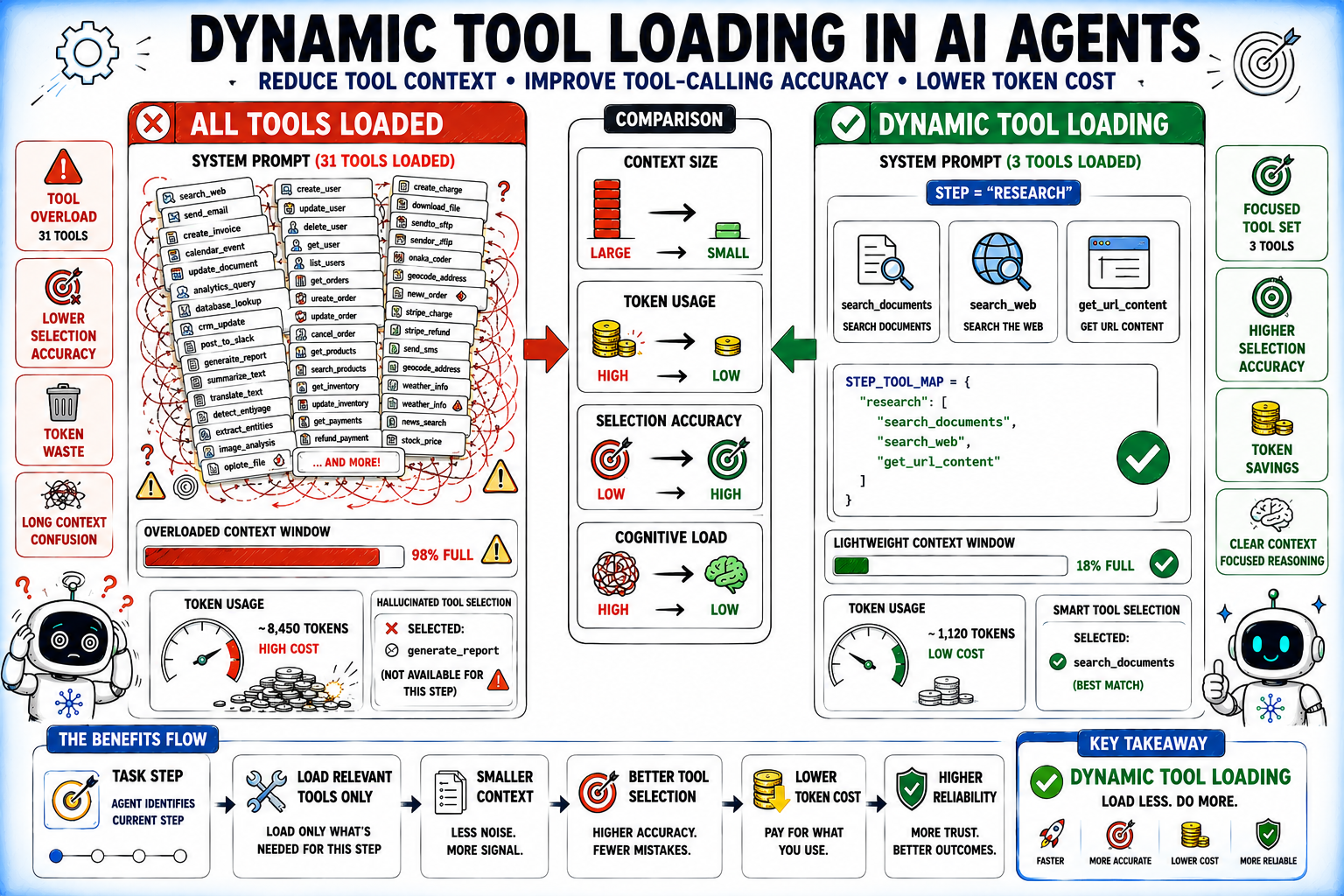
2. Loading All Tools Into Every Context: The "Context Window Bloat" Problem
As tool catalogs grow, agent performance degrades. The "LongFuncEval" study (2025) highlighted a substantial drop in tool-calling accuracy as the number of available tools increased, even with advanced LLMs featuring large context windows. Loading every tool into every system prompt consumes valuable token budget, increases latency, and makes it harder for the model to identify the most relevant tool, akin to finding a "needle in a haystack."
Dynamic tool loading offers a solution. By determining which tools are relevant to the current stage of an agent’s workflow and including only those, developers can significantly improve selection accuracy and reduce token costs. Techniques range from simple step-based mapping (e.g., research step uses search_web, write step uses create_document) to more sophisticated semantic search over tool descriptions to identify the most pertinent options. This targeted approach ensures the agent operates with an optimized and focused toolset.
3. Silent Partial Success: Masking Incomplete Operations
A critical design flaw arises when a tool completes only a portion of the requested work but returns a response that falsely indicates full success. This "silent partial success" misleads the agent, causing it to proceed with an incomplete or incorrect understanding of the system state, often leading to cascading errors or user dissatisfaction.
Tools performing bulk operations (e.g., bulk_create_tasks) must explicitly report both successful and failed items. A robust design includes fields like created_ids, failed_items (with reasons), and flags such as success and partial_success. This explicit reporting empowers the agent to branch its logic: it can retry failed items, report the partial outcome to the user, or halt the workflow, ensuring transparency and enabling intelligent recovery.
4. Overlapping Tool Names and Descriptions: Semantic Ambiguity
When multiple tools perform similar functions or have overlapping scopes, the agent constantly struggles to differentiate between them. Examples include get_user_info vs. fetch_user_details, or search_docs vs. query_knowledge_base. This semantic ambiguity forces the model to engage in additional, often token-intensive, reasoning to make a selection, increasing error rates and reducing efficiency.
Every tool must possess a distinct purpose that can be articulated without reference to other tools. If a description requires a "unlike X, this one…" clause, it signals a design problem. Auditing tool definitions for semantic distinctness before deployment is crucial to prevent "tool sprawl"—a common source of unreliable agent behavior in complex enterprise systems.
5. Destructive Actions Without a Confirmation Gate: Preventing Accidental Operations
Any tool that performs irreversible actions—deleting records, sending messages to real users, executing financial transactions—requires a structural two-step confirmation process. Relying solely on an in-prompt "are you sure?" is insufficient and prone to agent misinterpretation.
The safest pattern involves separating the staging of a destructive action from its execution. A stage_deletion tool, for instance, would prepare the deletion and return a short-lived, single-use confirmation token. A separate confirm_deletion tool would then be required to execute the action using this token, explicitly after user approval. This staged approach introduces a clear, structural boundary, preventing the agent from completing a destructive operation in a single, potentially erroneous reasoning step. It is crucial to note that this two-step flow must be augmented with additional safeguards like strict session binding and replay protection to prevent token misuse or leakage.
Conclusion: The Mandate for Meticulous Tool Engineering
The reliable deployment of AI agents hinges less on ever-larger, more capable LLMs and more on the meticulous engineering of their interfaces to the real world. As AI agents move from experimental setups to core operational roles within enterprises, the principles of robust tool design become non-negotiable. Industry experts, including those from leading AI research institutions, increasingly highlight tool design as a critical differentiator for agent performance and safety.
By adopting principles like single responsibility, stringent schema validation, explicit scope definitions, structured error handling, and idempotency, developers can build agents that are not only more accurate and efficient but also more resilient and trustworthy. Conversely, ignoring these design patterns will inevitably lead to agents that are prone to unpredictable failures, incur higher operational costs, and erode user confidence. The future of AI agents is not just about intelligent models; it is about intelligently designed interactions, marking tool engineering as a paramount skill for the next generation of AI developers.
