
A previously unknown vulnerability in OpenAI’s popular ChatGPT platform allowed sensitive conversation data to be exfiltrated without user knowledge or consent, according to new findings from cybersecurity firm Check Point, while a separate critical command injection flaw in OpenAI Codex could have led to the compromise of GitHub credential data, as detailed by BeyondTrust Phantom Labs. These discoveries underscore a rapidly evolving threat landscape surrounding artificial intelligence tools and the paramount importance of robust, multi-layered security protocols as AI systems become increasingly integrated into both personal and enterprise workflows.
Unmasking Covert Data Exfiltration in ChatGPT
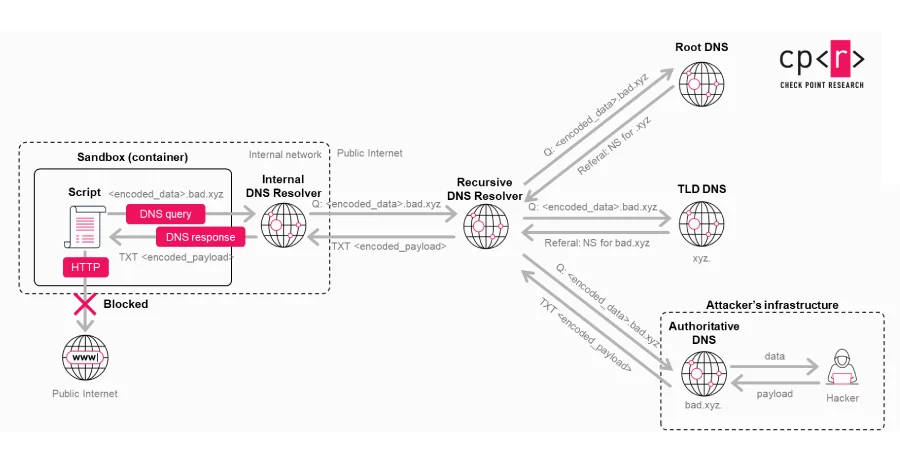
Check Point’s research revealed a sophisticated vulnerability within ChatGPT that bypassed its inherent security mechanisms, creating a "covert exfiltration channel." This flaw enabled a single, meticulously crafted malicious prompt to transform an otherwise innocuous conversation into a conduit for leaking user messages, uploaded files, and other sensitive content. The implications were significant: a backdoored custom GPT could leverage this weakness to access user data without any overt signs or consent from the user, operating entirely under the radar.
ChatGPT, a generative AI model developed by OpenAI, has rapidly ascended to prominence, revolutionizing how individuals and businesses interact with technology. Its capabilities range from drafting emails and writing code to analyzing complex datasets and assisting with research. This widespread adoption, particularly in enterprise environments where sensitive and proprietary information is frequently handled, makes any security vulnerability a serious concern. OpenAI has implemented various "guardrails" designed to prevent unauthorized data sharing and block direct outbound network requests, aiming to create a secure, isolated environment for user interactions. However, the newly discovered vulnerability managed to circumvent these safeguards entirely.
The technical ingenuity behind this exploit lies in its manipulation of a side channel originating from the Linux runtime environment that ChatGPT utilizes for code execution and data analysis. Instead of attempting direct, overt network requests that would typically be blocked by OpenAI’s controls, the attackers could abuse a hidden DNS-based communication path. This method served as a "covert transport mechanism," encoding sensitive information into DNS requests. These requests, being a fundamental part of internet communication and often less scrutinized than direct HTTP/HTTPS traffic, effectively flew under the radar of OpenAI’s visible AI guardrails. Furthermore, Check Point’s researchers demonstrated that this same hidden communication path could be exploited to establish remote shell access within the Linux runtime, thereby achieving full command execution capabilities.

The primary danger of this vulnerability stemmed from its stealth. It operated in the absence of any warning or user approval dialog, creating a significant "security blind spot." The AI system, operating under the assumption that its execution environment was entirely isolated and incapable of direct external data transfer, did not recognize the malicious DNS activity as an external data transfer requiring resistance or user mediation. Consequently, no warnings were triggered, no explicit user confirmation was sought, and the data leakage remained largely invisible from the user’s perspective, making detection incredibly challenging.
Timeline and Mitigation for ChatGPT Flaw
Check Point responsibly disclosed this vulnerability to OpenAI, which promptly addressed the issue. The patch was deployed on February 20, 2026. Crucially, there is no evidence to suggest that this particular vulnerability was ever exploited in a malicious context by threat actors before its discovery and remediation. This swift action by OpenAI highlights the collaborative efforts between security researchers and AI developers to maintain the integrity and security of these powerful platforms. However, the existence of such a sophisticated, covert exfiltration method serves as a stark reminder of the persistent and evolving challenges in securing advanced AI systems.
Exploitation Scenarios and Broader Implications
The potential for exploitation was considerable. An attacker could trick a user into pasting a malicious prompt by disguising it as a way to unlock premium capabilities for free or to enhance ChatGPT’s performance. For instance, a user seeking to "turbocharge" their AI experience might unwittingly paste a prompt that, unbeknownst to them, initiates a covert data transfer. The threat is further magnified when this technique is embedded within custom GPTs. In such a scenario, the malicious logic could be "baked in" directly by the custom GPT developer, negating the need to trick a user into pasting a specially crafted prompt altogether. Users interacting with a compromised custom GPT would be entirely unaware that their conversations and uploaded data were being siphoned off.
Eli Smadja, Head of Research at Check Point Research, emphasized the gravity of these findings, stating, "This research reinforces a hard truth for the AI era: don’t assume AI tools are secure by default." His statement, shared with The Hacker News, underscores a fundamental shift required in cybersecurity paradigms. As AI platforms evolve into comprehensive computing environments that handle increasingly sensitive data, relying solely on native security controls provided by AI vendors is no longer sufficient. Organizations must implement their own independent security layers to counter threats like prompt injections and other unforeseen behaviors in AI systems. "Organizations need independent visibility and layered protection between themselves and AI vendors. That’s how we move forward safely – by rethinking security architecture for AI, not reacting to the next incident," Smadja added, advocating for a proactive and architectural approach to AI security.

The Expanding Attack Surface: Prompt Poaching and Browser Extensions
The concerns raised by Check Point are not isolated incidents but rather part of a broader trend in AI security. Threat actors have already been observed publishing or updating web browser extensions that engage in "prompt poaching." These malicious add-ons silently siphon AI chatbot conversations without user consent, demonstrating how seemingly harmless browser utilities can become channels for data exfiltration.
Expel researcher Ben Nahorney highlighted the significant risks associated with such plugins: "It almost goes without saying that these plugins open the doors to several risks, including identity theft, targeted phishing campaigns, and sensitive data being put up for sale on underground forums." For organizations, the danger is amplified, as employees unknowingly installing these extensions could expose intellectual property, customer data, or other confidential information, leading to severe financial and reputational damage. This highlights the expanding attack surface presented by AI, where malicious actors are continuously finding new vectors to exploit.
Command Injection Vulnerability in OpenAI Codex
In parallel with the ChatGPT findings, a critical command injection vulnerability was discovered in OpenAI’s Codex, a cloud-based software engineering agent. This flaw, detailed by BeyondTrust Phantom Labs, could have been exploited to steal GitHub credential data and ultimately compromise multiple users interacting with a shared repository. OpenAI Codex is designed to assist developers by generating code, translating natural language to code, and performing various software engineering tasks, often requiring privileged access to developer environments and code repositories like GitHub.
Tyler Jespersen, a researcher at BeyondTrust Phantom Labs, explained the mechanism: "The vulnerability exists within the task creation HTTP request, which allows an attacker to smuggle arbitrary commands through the GitHub branch name parameter." This meant that due to improper input sanitization during the processing of GitHub branch names when tasks were executed on the cloud, an attacker could inject malicious commands. These commands, embedded within a seemingly legitimate branch name, would then be executed inside the agent’s container, allowing the retrieval of sensitive authentication tokens, specifically the victim’s GitHub User Access Token – the same token Codex uses to authenticate with GitHub.

Timeline and Mitigation for Codex Flaw
BeyondTrust reported this vulnerability to OpenAI on December 16, 2025. OpenAI responded swiftly, patching the issue by February 5, 2026. This vulnerability was broad in its scope, affecting not only the ChatGPT website but also the Codex CLI, Codex SDK, and the Codex IDE Extension, demonstrating the interconnectedness of OpenAI’s ecosystem and the potential for a single flaw to impact multiple tools.
Kinnaird McQuade, Chief Security Architect at BeyondTrust, further elaborated on the severity of the exploit on X, stating that it "granted lateral movement and read/write access to a victim’s entire codebase." This meant an attacker could gain extensive control over a compromised repository, potentially injecting malicious code, stealing proprietary information, or disrupting development pipelines.
Advanced Exploitation and Enterprise Implications
The research by BeyondTrust also highlighted how the branch command injection technique could be extended to steal GitHub Installation Access tokens and execute bash commands on the code review container whenever @codex was referenced in GitHub. This advanced exploitation scenario demonstrates a sophisticated understanding of the integration points between AI agents and development workflows. BeyondTrust explained: "With the malicious branch set up, we referenced Codex in a comment on a pull request (PR). Codex then initiated a code review container and created a task against our repository and branch, executing our payload and forwarding the response to our external server." This chain of events illustrates how a seemingly innocuous developer action – a comment on a pull request – could trigger a malicious payload if an underlying vulnerability exists.
The findings from both Check Point and BeyondTrust collectively paint a picture of a growing security challenge: the privileged access granted to AI coding agents can be weaponized, providing a "scalable attack path" into enterprise systems without triggering traditional security controls. As AI agents become more deeply integrated into developer workflows, managing and securing their interactions with sensitive data and systems becomes paramount. BeyondTrust emphasized this point, stating, "As AI agents become more deeply integrated into developer workflows, the security of the containers they run in – and the input they consume – must be treated with the same rigor as any other application security boundary." The report concluded with a stark warning: "The attack surface is expanding, and the security of these environments needs to keep pace."

Rethinking AI Security Architecture
These recent discoveries serve as a critical wake-up call for the entire AI industry and the organizations leveraging these powerful tools. The vulnerabilities highlight several key areas that demand immediate attention and a fundamental rethinking of cybersecurity strategies in the age of AI:
- Zero-Trust Principles for AI: The assumption of isolation or inherent security within AI environments has proven insufficient. A zero-trust approach, where no entity, internal or external, is trusted by default, must be applied to AI interactions, data flows, and execution environments.
- Input Sanitization and Validation: Both vulnerabilities, particularly the Codex flaw, underscore the critical importance of rigorous input sanitization and validation. Malicious inputs, whether disguised as prompts or branch names, must be meticulously scrubbed to prevent command injection and other forms of abuse.
- Visibility and Monitoring: The covert nature of the ChatGPT exfiltration vulnerability demonstrates the need for advanced monitoring capabilities that can detect subtle anomalies in network traffic, DNS requests, and runtime behavior within AI environments. Traditional network monitoring might not be sufficient.
- Layered Security for AI: Organizations cannot rely solely on the security features provided by AI vendors. Implementing independent, layered security solutions – including AI-specific firewalls, prompt injection defenses, and data loss prevention (DLP) tools – between their sensitive data and AI platforms is essential.
- Secure Development Lifecycles for AI: AI developers must integrate security considerations throughout the entire development lifecycle, from design and coding to deployment and maintenance. This includes threat modeling, secure coding practices, and regular security audits of AI models and their underlying infrastructure.
- User Education and Awareness: While technical controls are vital, educating users about the risks of malicious prompts, unverified browser extensions, and the importance of scrutinizing AI interactions remains a crucial defense layer.
In conclusion, the rapid evolution and widespread adoption of AI tools like ChatGPT and OpenAI Codex have introduced unprecedented capabilities but also significant new security challenges. The vulnerabilities uncovered by Check Point and BeyondTrust are stark reminders that the expanding attack surface of AI demands a proactive, sophisticated, and multi-layered approach to cybersecurity. As AI platforms become integral to critical operations, the security of these environments must not merely react to incidents but rather anticipate and prevent them through innovative security architectures, continuous research, and collaborative industry efforts. The future of AI safety hinges on our collective ability to move forward securely, by rethinking security architecture for AI, not just reacting to the next incident.
