
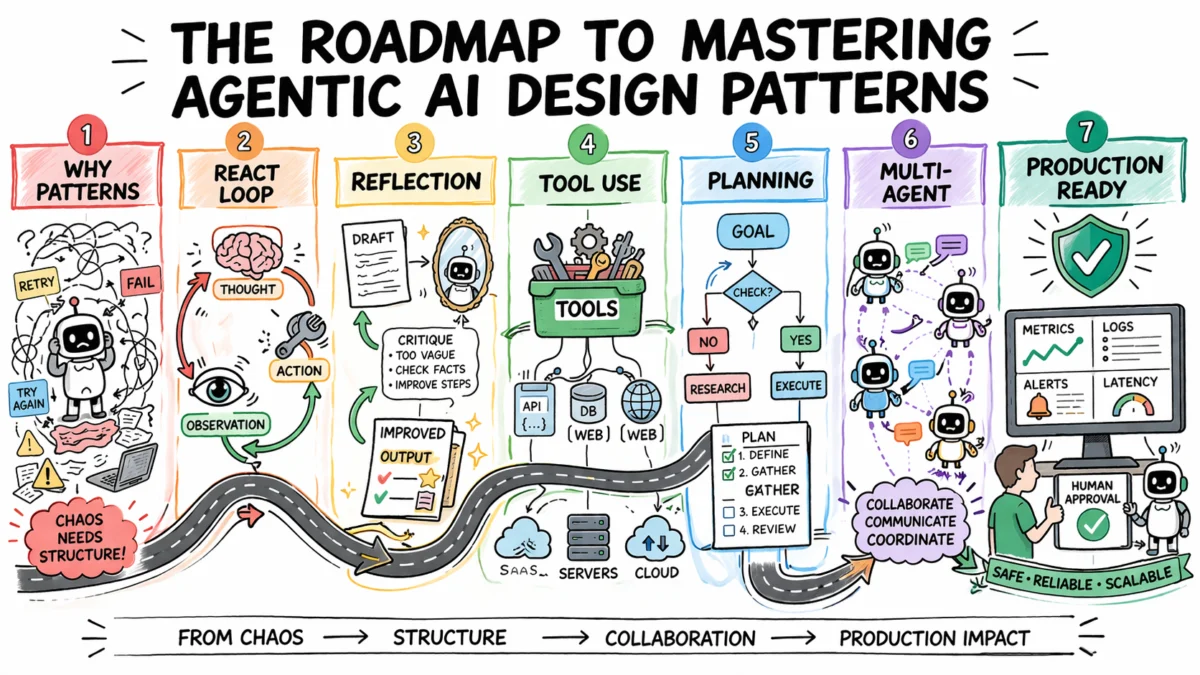
The rapid evolution of artificial intelligence, particularly in the realm of large language models (LLMs), has ushered in an era where AI systems are no longer merely predictive tools but active, autonomous agents capable of complex reasoning and interaction with the real world. However, the development of these "agentic AI" systems often proceeds in an ad-hoc manner, with developers addressing challenges piece by piece rather than through a cohesive, architectural framework. This lack of structural governance for reasoning, action, error recovery, and task hand-offs leads to unpredictable behavior, significant debugging challenges, and an inability to systematically improve agent performance, especially in multi-step workflows where early errors can cascade.
Agentic design patterns emerge as a critical solution to these systemic issues. Much like design patterns in traditional software engineering, these are reusable, proven approaches tailored for recurring problems in agentic system design. They dictate how an agent formulates its reasoning before acting, evaluates its own outputs, selects and utilizes external tools, coordinates with other agents, and determines when human intervention is necessary. The judicious selection of the appropriate pattern for a given task is paramount, transforming unpredictable AI behavior into something predictable, debuggable, and composable as system requirements inevitably grow. This article provides a comprehensive roadmap for understanding and applying agentic AI design patterns, elucidating why pattern selection is an architectural imperative, exploring the core patterns prevalent in production systems today, and detailing their fit, trade-offs, and layering in real-world applications.
The Foundational Challenge: From Prompting Fixes to Architectural Solutions
Before delving into specific design patterns, it is crucial for developers to reframe their understanding of agent failures. The common instinct is to attribute misbehavior to "prompting failures," assuming a better system prompt will resolve the issue. While prompt engineering remains vital, a deeper analysis frequently reveals that the root cause is architectural. An agent that enters an endless loop, for instance, typically lacks an explicit stopping condition within its design. Similarly, an agent that misuses tools often operates without a clear contract dictating when and how to invoke specific functionalities. Inconsistent outputs from identical inputs point to the absence of a structured decision-making framework.
Design patterns are engineered to address these very problems. They offer repeatable architectural templates that explicitly define the agent’s operational loop: how it makes decisions, when to terminate a task, how to recover gracefully from errors, and how to interact reliably with external systems. Without these structured approaches, agent behavior becomes exceedingly difficult to debug, optimize, or scale effectively.
A common pitfall for development teams is the "pattern-selection problem," characterized by an eagerness to deploy the most sophisticated and capable patterns—such as multi-agent systems or dynamic planning—prematurely. This inclination towards premature complexity in agentic systems carries substantial costs: more model calls translate to higher latency and increased token expenses; a greater number of agents introduces more potential points of failure; and intricate orchestration amplifies the likelihood of coordination bugs. The expensive mistake is often made by adopting complex patterns before simpler alternatives have demonstrably reached their limitations. The practical implication is a mandate to start with the simplest effective pattern and only introduce greater complexity when clear, unavoidable limitations necessitate it. This approach ensures efficiency, manageability, and cost-effectiveness in development. For further insights, resources from Google Cloud and Amazon Web Services offer valuable perspectives on AI agent design patterns.
Core Agentic Design Patterns: A Strategic Toolkit for Reliable AI
The journey to building robust agentic AI systems is navigated through a series of foundational design patterns, each addressing specific challenges and offering distinct advantages.
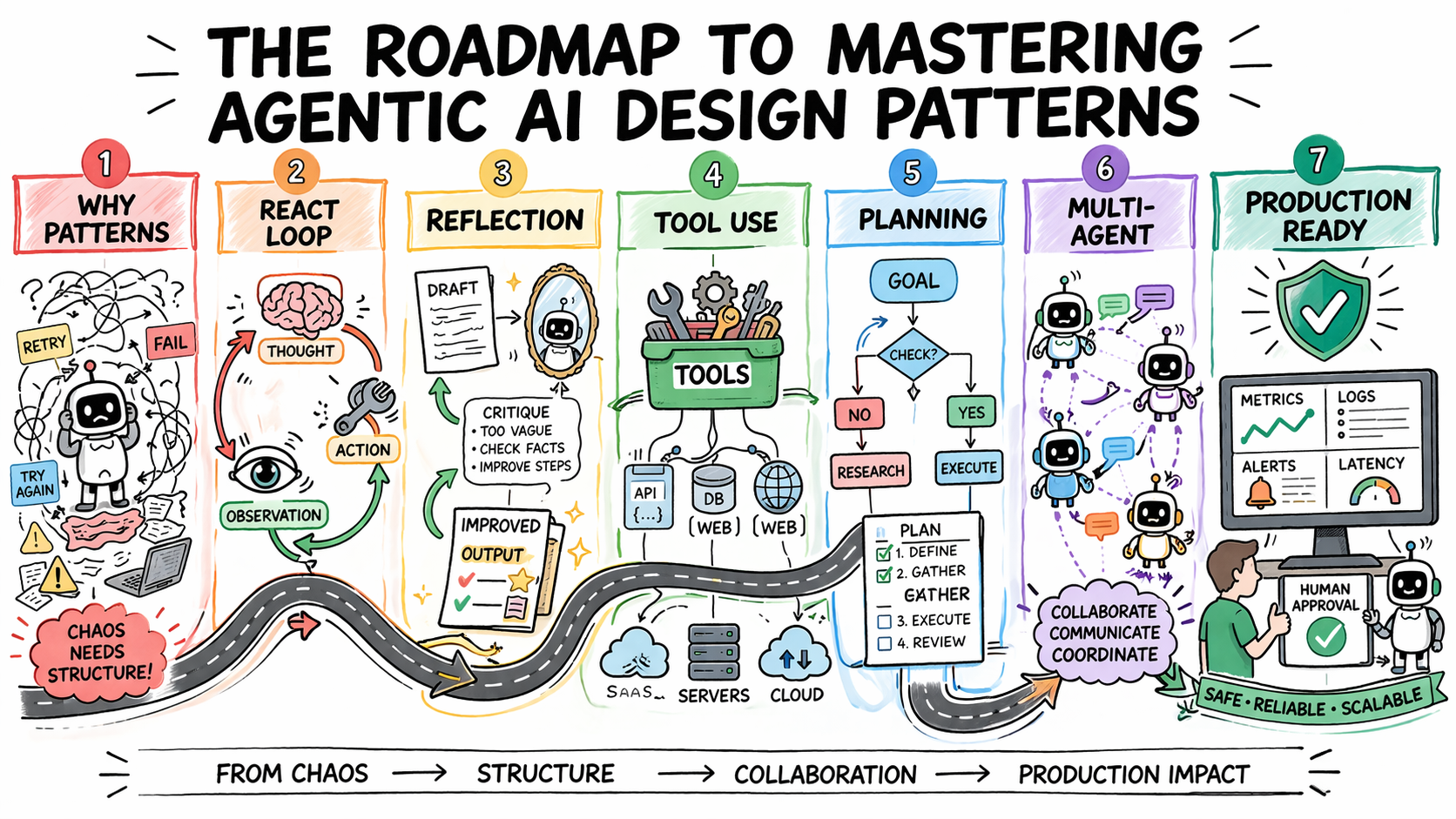
1. ReAct: The Default for Adaptive and Transparent Reasoning
The ReAct pattern, an acronym for "Reasoning and Acting," stands as the most foundational and often the ideal default for addressing complex, unpredictable tasks. It ingeniously integrates chain-of-thought reasoning with the utilization of external tools within a continuous feedback loop. The pattern alternates systematically through three distinct phases:
- Observation: The agent processes the current state, including user input, previous tool outputs, or internal reflections.
- Reasoning: Based on the observation, the agent formulates a thought process, deciding the next logical step, whether to act, to refine its understanding, or to conclude.
- Action: The agent executes a chosen action, which could involve calling an external tool, generating a response, or seeking more information.
This cycle reiterates until the task is definitively completed or a pre-defined stopping condition is met. ReAct’s effectiveness stems from its externalization of reasoning. Every decision, every step of the agent’s logic, is made visible, providing unparalleled transparency. This transparency is crucial for debugging: when an agent falters, developers can pinpoint precisely where the logical breakdown occurred, rather than grappling with an opaque output. Furthermore, ReAct mitigates premature conclusions and hallucinations by grounding each reasoning step in an observable, real-world result before proceeding, ensuring decisions are data-driven.
However, ReAct is not without its trade-offs. Each iteration of the loop necessitates an additional model call, which can significantly increase both latency and computational cost, especially for lengthy tasks. Errors in tool output can propagate through subsequent reasoning steps, leading to cumulative inaccuracies. The non-deterministic nature of some LLMs can mean identical inputs yield different reasoning paths, posing consistency challenges in regulated or high-stakes environments. Critically, without an explicit iteration cap, the ReAct loop can run indefinitely, leading to spiraling costs and inefficiency.
ReAct is best suited for scenarios where the solution path is not predetermined, such as adaptive problem-solving, multi-source research synthesis, and customer support workflows characterized by variable complexity. Conversely, it should be avoided when speed is the paramount concern or when inputs are sufficiently well-defined that a fixed, less iterative workflow would prove faster and more economical. Academic research, notably "ReAct: Synergizing Reasoning and Acting in Language Models," and resources from IBM provide deeper insights into its mechanics and applications.
2. Reflection: Elevating Output Quality Through Self-Correction
Reflection endows an agent with the vital capability to evaluate and subsequently revise its own outputs before they are presented to the end-user. This pattern follows a robust generation-critique-refinement cycle. Initially, the agent produces an output. This output is then critically assessed against a set of predefined quality criteria. The insights derived from this assessment form the basis for subsequent revisions. This iterative cycle continues for a specified number of iterations or until the output demonstrably meets a predetermined quality threshold.
This pattern proves particularly effective when the critique mechanism is highly specialized. For instance, an agent tasked with reviewing code can be configured to concentrate on identifying bugs, edge cases, or security vulnerabilities. An agent reviewing a legal contract might specifically check for missing clauses or logical inconsistencies. The efficacy of reflection is significantly amplified when the critique step is linked to external verification tools—such as a linter for code, a compiler, or a schema validator. This integration provides the agent with deterministic, objective feedback, moving beyond sole reliance on its own judgment and enhancing the rigor of the evaluation process.
Several design decisions are critical for successful implementation. The critic component should ideally be independent of the generator. At a minimum, this implies a separate system prompt with distinct instructions; in high-stakes applications, employing a different model entirely for the critic can prevent it from inheriting the generator’s blind spots, thereby fostering genuine evaluation rather than superficial self-agreement. Furthermore, explicit iteration bounds are non-negotiable. Without a maximum loop count, an agent perpetually seeking marginal improvements risks stalling indefinitely instead of converging on an acceptable output.
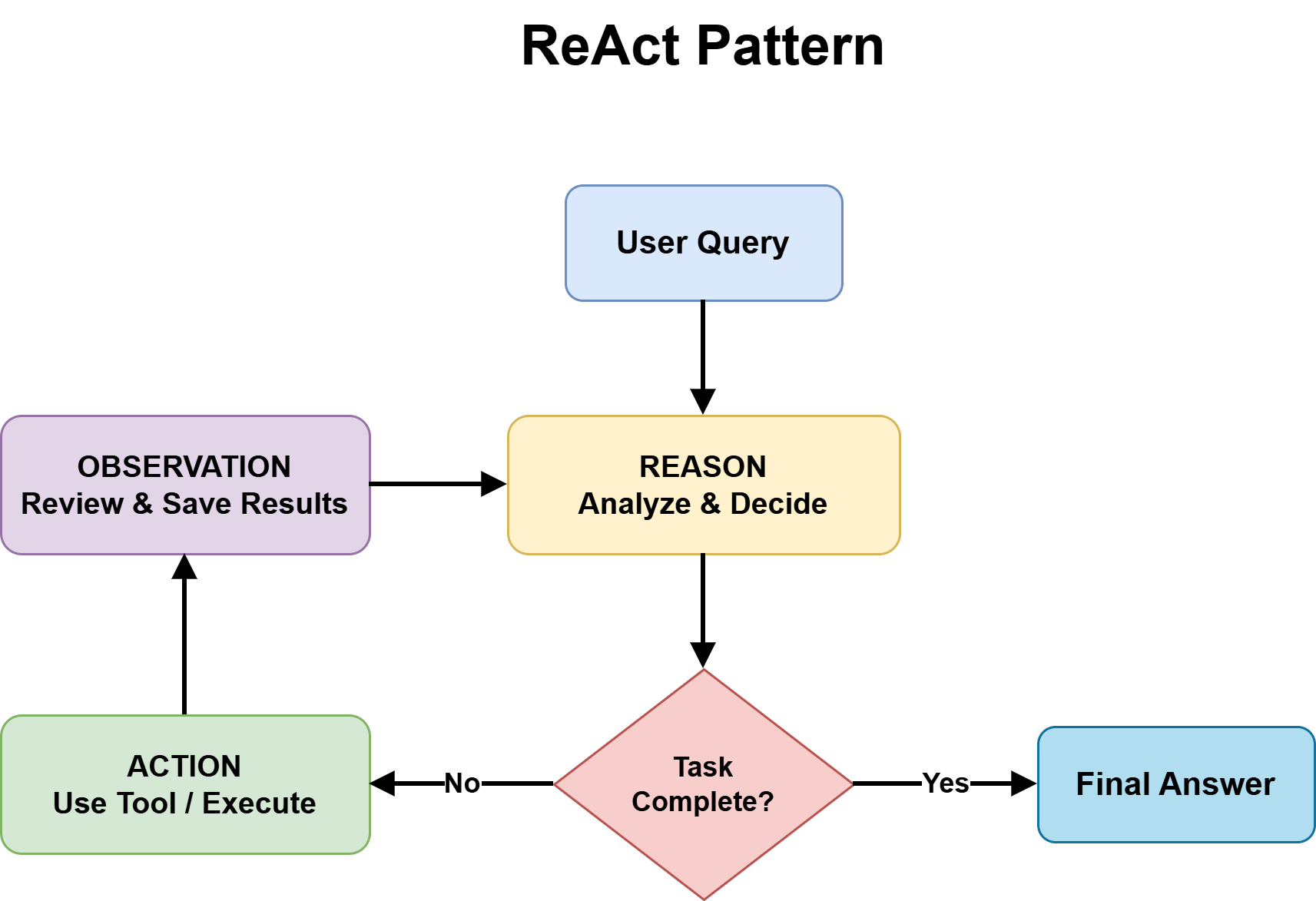
Reflection is the optimal pattern when output quality takes precedence over speed, and when tasks possess sufficiently clear correctness criteria to enable systematic evaluation. However, it introduces additional cost and latency, which may not be justifiable for simple factual queries or applications with stringent real-time performance requirements. DeepLearning.AI and the LangChain blog offer further exploration into reflection agents and their design.
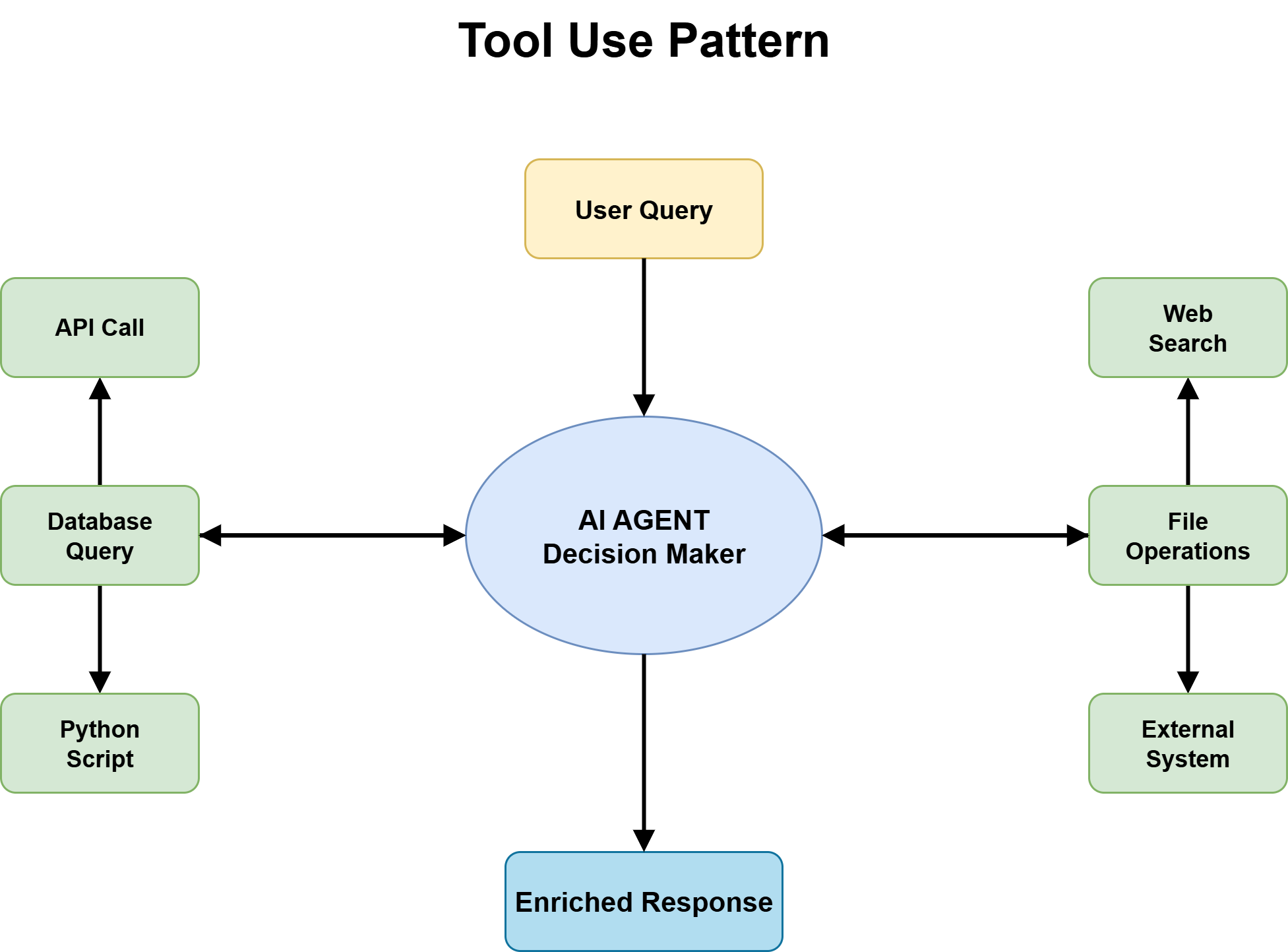
3. Tool Use: Bridging AI and the Real World
Tool use is perhaps the most transformative agentic design pattern, converting an AI agent from a passive knowledge system into an active, real-world action system. Without the ability to use tools, an agent is confined to its training data, lacking access to current information, external systems, or the capacity to trigger actions in the physical or digital world. With tool use, an agent gains the power to call APIs, query databases, execute code, retrieve relevant documents, and interact seamlessly with various software platforms. For nearly every production-grade agent handling real-world tasks, tool use forms the indispensable foundation upon which all other capabilities are built.
The most paramount architectural decision in implementing tool use is the definition of a fixed tool catalog with strict input and output schemas. Without precise schemas, the agent is left to guess how to invoke tools, leading to frequent failures, especially under edge cases. Tool descriptions must be sufficiently precise to enable the agent to accurately reason about which tool is appropriate for a given situation; vague descriptions lead to mismatched calls, while overly narrow ones cause the agent to overlook valid use cases.
A second critical decision involves robustly handling tool failures. An agent that merely inherits the reliability problems of its external dependencies without explicit failure-handling logic will be inherently fragile. APIs are prone to rate-limiting, timeouts, returning unexpected data formats, and undergoing behavior changes after updates. The agent’s tool layer must incorporate explicit error handling mechanisms, intelligent retry logic, and graceful degradation paths for scenarios where external tools become temporarily unavailable.
Tool selection accuracy is a subtler yet equally vital concern. As tool libraries expand, agents must reason over increasingly larger catalogs to identify the correct tool for each task. Performance in tool selection tends to degrade with increasing catalog size. A valuable design principle is to structure tool interfaces such that the distinctions between different tools are unambiguous and clear, simplifying the agent’s decision-making process.
Finally, tool use introduces a significant security surface that agent developers often underestimate. Once an agent can interact with real systems—submitting forms, updating records, triggering financial transactions—the potential "blast radius" of errors or malicious exploitation grows exponentially. Implementing sandboxed execution environments, stringent input validation, output sanitization, and human approval gates for high-risk tool invocations are absolutely essential safety measures. The OWASP Top 10 for LLM Applications serves as a critical reference for mitigating these security risks. Resources from Microsoft and Machine Learning Mastery provide comprehensive frameworks for mastering LLM tool calling.
4. Strategic Planning: Orchestrating Complex Workflows
Planning emerges as the essential pattern for tasks where the inherent complexity or coordination requirements are too high for ad-hoc reasoning through a simple ReAct loop. While ReAct improvises steps dynamically, planning meticulously breaks down the overarching goal into an ordered sequence of subtasks, establishing explicit dependencies before any execution commences.
There are two primary implementations of planning:
- Explicit Plan Generation: The agent first generates a complete, multi-step plan outlining all necessary actions and their sequence, then executes this plan.
- Dynamic Task Decomposition: The agent breaks down the initial goal into a smaller set of sub-goals, tackles one, and then dynamically decomposes the next based on the current state.
Planning yields significant dividends in tasks requiring intricate coordination, such as multi-system integrations that must occur in a precise sequence, research tasks synthesizing information from numerous disparate sources, or complex development workflows spanning design, implementation, and rigorous testing phases. The primary benefit lies in surfacing hidden complexities and interdependencies upfront, before execution begins, thereby preventing costly mid-run failures and enabling more efficient resource allocation.
The trade-offs are straightforward. Planning necessitates an additional model call upfront to generate the plan, which is an overhead not justified for simpler tasks. Moreover, it assumes that the task structure is largely knowable in advance, an assumption that does not always hold true for highly dynamic or exploratory problems. Therefore, planning should be employed when the task structure can be clearly articulated upfront and when coordination between steps is sufficiently complex to benefit from explicit sequencing. For all other scenarios, ReAct remains the preferred default. DeepLearning.AI provides further insights into agentic design patterns for planning.
5. Multi-Agent Collaboration: Specialization for Scalability and Enhanced Performance
Multi-agent systems represent a sophisticated architectural pattern where work is distributed across several specialized agents, each endowed with focused expertise, a tailored tool set, and a clearly defined role. In this setup, a central coordinator typically manages task routing and synthesis, while specialist agents handle the specific functionalities for which they are optimized.
The benefits of this collaborative approach are substantial: it often leads to superior output quality, allows for the independent improvement and optimization of individual agents, and provides a more scalable overall architecture. However, these advantages come with a significant increase in coordination complexity. Successful implementation necessitates addressing several key design questions from the outset:
- Ownership: Explicitly defining which agent possesses write authority over shared state is crucial to prevent conflicts and ensure data integrity.
- Routing Logic: Determining how the coordinator directs tasks between agents can involve either an LLM for flexible decision-making or deterministic rules for predictable routing. Most production systems adopt a hybrid approach.
- Orchestration Topology: The structure governing how agents interact and communicate is vital. Common topologies include:
- Sequential: Agents pass tasks from one to the next in a predefined order.
- Hierarchical: A primary agent delegates tasks to sub-agents and synthesizes their results.
- Blackboard: Agents contribute to a shared workspace, reading and writing information as needed, with a central arbitrator managing access and conflict resolution.
Given the inherent complexity, the prudent strategy is to begin with a single, highly capable agent leveraging ReAct and appropriate tools. A transition to a multi-agent architecture should only occur when a clear bottleneck or a demonstrable need for specialization and distributed processing emerges. Resources from Microsoft Azure and IBM provide valuable perspectives on multi-agent systems and their applications.
Beyond Design: Production Readiness and Safety in Agentic AI
The selection of appropriate design patterns constitutes only half the effort. Ensuring these patterns operate reliably and safely in production environments demands deliberate evaluation, explicit safety design, and continuous monitoring.
Define Pattern-Specific Evaluation Criteria: Establishing clear metrics is paramount.
- For ReAct, evaluate success rate, tool call accuracy, and loop efficiency.
- For Reflection, measure output quality metrics, reduction in errors, and the number of refinement iterations.
- For Tool Use, track API success rates, robustness of error handling, and security vulnerability detection.
- For Multi-Agent Systems, assess coordination efficiency, task completion rates, and inter-agent communication overhead.
Build Failure Mode Tests Early: Proactively develop tests that specifically probe for common vulnerabilities, such as tool misuse, infinite loops, routing failures, and degraded performance under long context windows. Treat observability as a non-negotiable requirement; step-level traces are essential for effective debugging and understanding agent behavior.
Design Guardrails Based on Risk: Implement robust validation mechanisms, rate limiting, and human approval gates where necessary, especially for high-risk actions. The OWASP Top 10 for LLM Applications serves as an invaluable reference for identifying and mitigating common security vulnerabilities.
Plan for Human-in-the-Loop (HITL) Workflows: Human oversight should be considered a fundamental design pattern, not merely a fallback. For critical or sensitive operations, integrating human review and approval stages can significantly enhance reliability and safety.
Leverage Existing Agent Orchestration Frameworks: Tools like LangGraph, AutoGen, CrewAI, and Guardrails AI provide robust frameworks that simplify the implementation of these design patterns, offering built-in functionalities for orchestration, testing, and guardrail enforcement. DeepLearning.AI offers short courses on evaluating AI agents, further emphasizing the importance of rigorous assessment.
Conclusion
Agentic AI design patterns are not a static checklist to be completed once; rather, they are dynamic architectural tools that must evolve in tandem with the complexity and requirements of your AI system. The strategic imperative is to commence with the simplest pattern that effectively addresses the task at hand, introducing additional complexity only when unequivocally necessary. Simultaneously, a substantial investment in observability, rigorous evaluation, and robust safety mechanisms is critical. This disciplined, iterative approach is the cornerstone for developing agentic AI systems that are not only functionally capable but also inherently reliable, scalable, and safe for real-world deployment. As agentic AI continues to mature, the judicious application of these design patterns will be the defining factor in separating experimental prototypes from production-grade, transformative AI solutions across diverse industries.
