
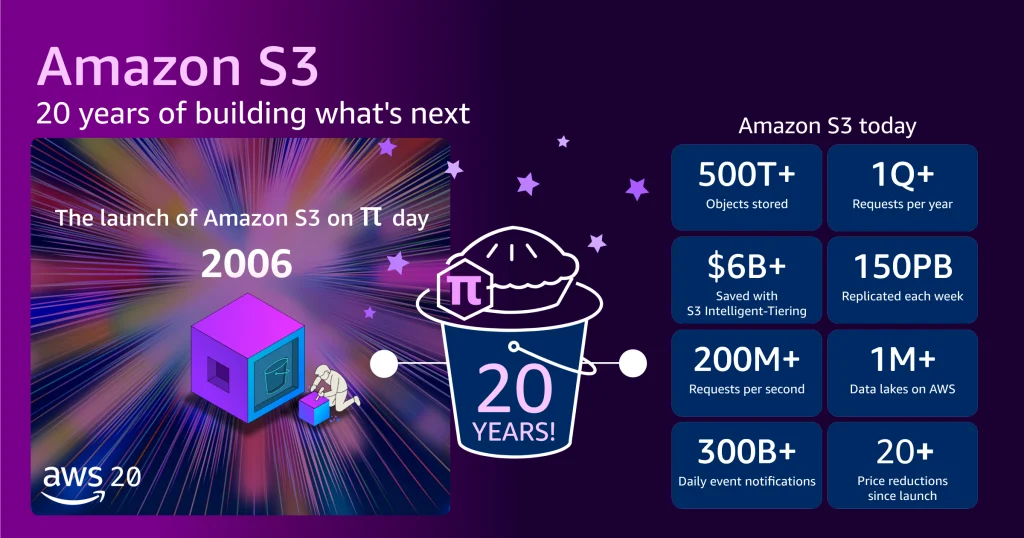
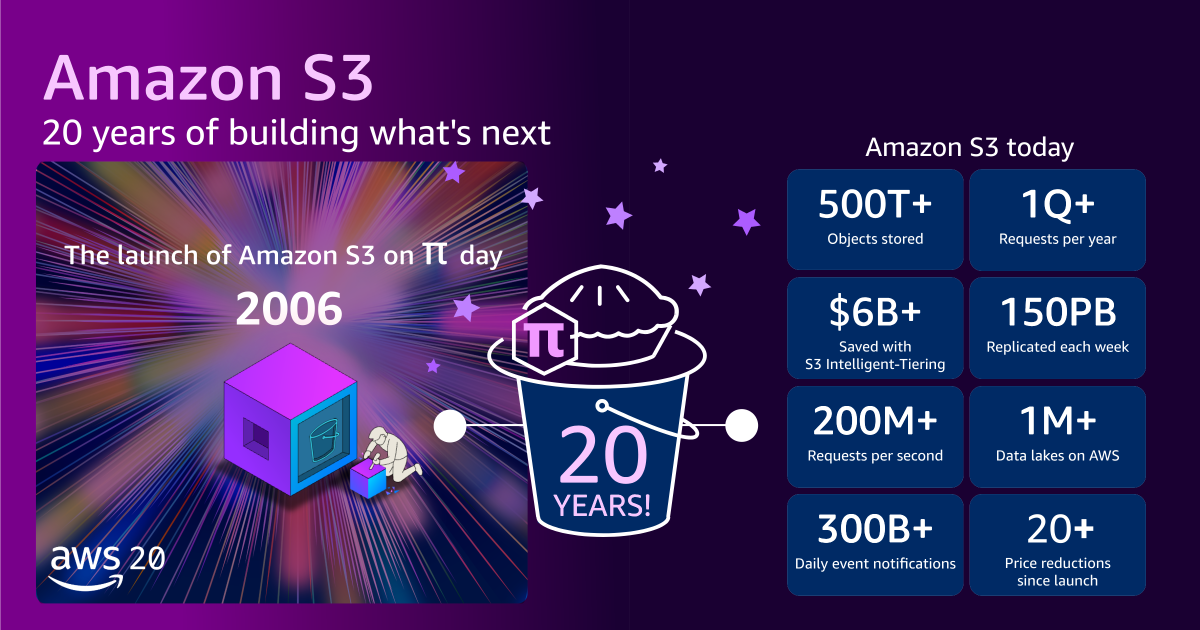
On March 14, 2006, a seemingly modest announcement appeared on the Amazon Web Services (AWS) "What’s New" page, introducing Amazon Simple Storage Service (Amazon S3). What began with a single paragraph and minimal fanfare—even Jeff Barr’s customary blog post was brief, penned just before boarding a flight—would quietly revolutionize the landscape of cloud computing and data storage, becoming an indispensable foundation for the modern internet and artificial intelligence workloads. Two decades later, S3 stands as a testament to foundational engineering principles and relentless innovation, having evolved from a pioneering object storage service into a global data backbone of unimaginable scale.
The Dawn of Cloud Storage: S3’s Genesis
Before the advent of S3, the digital infrastructure landscape was markedly different. Developers and businesses grappled with the significant "undifferentiated heavy lifting" of managing their own storage. This involved procuring, configuring, maintaining, and scaling physical hardware, a complex, costly, and time-consuming endeavor. Ensuring data durability, security, and availability required specialized expertise and substantial capital investment, often leading to fragmented and inefficient storage solutions. Startups faced high barriers to entry, while established enterprises struggled with the agility needed to respond to rapidly changing data demands.
AWS itself, born from Amazon’s internal need to build a robust, scalable infrastructure for its e-commerce operations, recognized this universal challenge. The vision for S3 was simple yet profound: abstract away the complexities of storage, offering it as a utility that developers could access programmatically over the internet. This meant freeing engineers from worrying about hard drives, RAID configurations, and disaster recovery plans, allowing them to channel their efforts into building innovative applications and services. The initial promise was clear: "Amazon S3 is storage for the Internet. It is designed to make web-scale computing easier for developers. Amazon S3 provides a simple web services interface that can be used to store and retrieve any amount of data, at any time, from anywhere on the web. It gives any developer access to the same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of web sites." This declaration, though understated at the time, laid the groundwork for a paradigm shift.
A Quiet Revolution: The 2006 Launch and Its Enduring Principles
The launch of S3 was not accompanied by a grand press conference or elaborate marketing campaigns. Instead, it was a developer-centric release, emblematic of AWS’s early approach: deliver robust building blocks and let the developer community discover their potential. At its core, S3 introduced two fundamental primitives that remain central to its operation today: PUT, to store an object, and GET, to retrieve it. This simplicity belied a sophisticated underlying architecture designed for massive scale and resilience.
From its inception, S3 was guided by five unwavering principles that have underpinned its continuous evolution:
- Security: Data protection is paramount, with security features built in by default, enabling customers to control access and encrypt their data.
- Durability: S3 is engineered for "11 nines" (99.999999999%) of durability, a design goal that translates into an expectation of virtually no data loss over extended periods. This is achieved through sophisticated replication and self-healing mechanisms.
- Availability: Designed for high uptime, S3’s architecture anticipates and handles failures at every layer, ensuring data is accessible when needed.
- Performance: The service is optimized to deliver consistent, high-speed access to data, regardless of the volume stored or the rate of requests.
- Elasticity: S3 automatically scales to accommodate growing data volumes and fluctuating access patterns without requiring any manual intervention from users.
These five fundamentals represent AWS’s commitment to handling the "undifferentiated heavy lifting," allowing developers to focus on application logic rather than infrastructure management. This philosophy proved to be a powerful catalyst for innovation across the technology industry.
Exponential Growth: S3’s Unprecedented Scale and Economic Impact
The journey of S3 over two decades is a remarkable story of exponential growth and continuous price reduction. When it launched in 2006, S3 offered approximately one petabyte (PB) of total storage capacity across about 400 storage nodes housed in 15 racks, spanning three data centers. It was designed to store tens of billions of objects, with a maximum object size of 5 gigabytes (GB). The initial pricing was set at 15 cents per gigabyte per month.
Fast forward to today, and the numbers are staggering. S3 now stores more than 500 trillion objects, a number that continues to climb at an astonishing rate. It serves over 200 million requests per second globally, processing hundreds of exabytes (EB) of data across 123 Availability Zones (AZs) in 39 AWS Regions, catering to millions of customers worldwide. The maximum object size has expanded dramatically from 5 GB to 50 terabytes (TB), representing a 10,000-fold increase in individual object capacity. To put its physical scale into perspective, if one were to stack all the tens of millions of hard drives comprising S3’s infrastructure, they would reach the International Space Station and nearly back.
This incredible expansion has been accompanied by a consistent commitment to reducing costs for customers. Today, the price for S3 storage has plummeted to slightly over 2 cents per gigabyte per month, representing an approximate 85% reduction since its launch in 2006. Furthermore, AWS has introduced various storage classes and intelligent tiering options, allowing customers to optimize their storage spend based on access patterns and durability requirements. For instance, Amazon S3 Intelligent-Tiering, which automatically moves data between different access tiers, has collectively saved customers more than $6 billion in storage costs compared to using Amazon S3 Standard alone. This combination of immense scale and ever-decreasing cost has democratized access to enterprise-grade storage, making it feasible for everything from small startups to global enterprises.
Industry Standard: The S3 API’s Pervasive Influence
Beyond its internal growth, S3’s impact reverberates across the entire storage industry through the widespread adoption of its Application Programming Interface (API). The S3 API has become a de facto standard, a common language for cloud storage. Numerous third-party vendors and open-source projects now offer S3-compatible storage tools and systems, implementing the same API patterns and conventions. This standardization has significant implications: it fosters interoperability, reduces vendor lock-in, and allows developers to leverage existing skills and tools across diverse storage environments. The portability of knowledge and code has accelerated innovation, creating a richer and more accessible storage ecosystem for everyone.
Perhaps one of S3’s most remarkable achievements, alongside its scale and cost efficiency, is its unwavering commitment to backward compatibility. Code written for S3 in 2006 continues to function seamlessly today, without requiring any modifications. This enduring compatibility is a testament to AWS’s rigorous engineering discipline, ensuring that customer investments in data and applications are protected over the long term. While the underlying infrastructure has undergone multiple generations of upgrades, disk migrations, and complete rewrites of request-handling code, the fundamental API contract has remained intact, embodying the "just works" philosophy.
Engineering Excellence: The Innovation Engine
The ability to operate S3 at such an unprecedented scale, while maintaining its core tenets of durability, availability, and performance, is a direct result of continuous engineering innovation. Insights into these advanced engineering practices were recently shared by Mai-Lan Tomsen Bukovec, VP of Data and Analytics at AWS, during an in-depth interview with Gergely Orosz of The Pragmatic Engineer.
At the heart of S3’s legendary 11 nines of durability lies a sophisticated system of microservices. These "auditor services" continuously inspect every single byte across the entire fleet of storage nodes, proactively detecting any signs of data degradation. Upon detection, they automatically trigger repair systems, ensuring that data integrity is maintained and objects are never lost. The design goal for durability explicitly reflects the meticulous sizing of replication factors and re-replication fleets, ensuring a truly lossless system.
S3 engineers also leverage cutting-edge techniques such as formal methods and automated reasoning in production environments. These mathematical approaches are used to rigorously prove the correctness of critical system components. For instance, when new code is checked into the S3 index subsystem, automated proofs verify that consistency properties have not regressed. This same methodology is applied to validate the correctness of complex features like cross-Region replication and intricate access policies, providing an unparalleled level of confidence in the system’s behavior.
In a significant engineering undertaking over the past eight years, AWS has progressively rewritten performance-critical code in the S3 request path using Rust. Components responsible for blob movement and disk storage have already been refactored, with work actively ongoing across other parts of the system. Rust’s benefits extend beyond raw performance; its robust type system and memory safety guarantees eliminate entire classes of bugs at compile time. This is a crucial advantage when operating a service with S3’s scale and stringent correctness requirements, significantly enhancing reliability and reducing the likelihood of production issues.
Underlying these specific technical choices is a broader design philosophy: "Scale is to your advantage." S3 engineers consciously design systems such that increased scale inherently improves attributes for all users. For example, as S3 grows larger, the workloads become more de-correlated, meaning that a localized issue is less likely to impact a large portion of users. This inherent de-correlation enhances overall reliability and stability for the entire customer base.
Beyond Storage: The Future as a Data Foundation
As S3 enters its third decade, its vision extends far beyond being merely a storage service. It is increasingly positioned as the universal foundation for all data and AI workloads. The guiding principle for its future is elegantly simple: store any type of data once in S3 and work with it directly, eliminating the need to move data between specialized, often expensive, systems. This approach significantly reduces costs, streamlines data pipelines, and removes the complexity and redundancy associated with maintaining multiple copies of the same data across different platforms.
This evolving role is evident in a series of recent innovations that leverage S3 as a direct data plane for advanced analytics and machine learning. While the original article omits a specific list, these capabilities often include:
- Data Lake Foundations: S3 serves as the primary storage layer for data lakes, allowing organizations to store vast amounts of raw data in its native format, which can then be queried by various analytics services.
- Direct Querying: Services like Amazon Athena (for interactive SQL queries) and Amazon Redshift Spectrum (for querying data in S3 directly from Redshift data warehouses) enable users to analyze data without moving it.
- Machine Learning Integration: S3 is deeply integrated with machine learning services like Amazon SageMaker, serving as the repository for training data, model artifacts, and inference results, facilitating the entire ML lifecycle.
- Tiered Storage for Cost Optimization: Continuous innovation in storage classes (e.g., S3 Glacier Instant Retrieval, S3 One Zone-IA) and Intelligent-Tiering ensures that data is stored at the most cost-effective tier based on access patterns, without sacrificing durability or availability.
- Data Governance and Management: Enhanced capabilities for data governance, auditing, and lifecycle management ensure that data stored in S3 meets regulatory and compliance requirements.
Each of these capabilities operates within the S3 cost structure, making it economically feasible to handle diverse data types and complex workloads that traditionally required expensive databases or highly specialized systems. This convergence of storage and compute on S3 is transforming how organizations derive value from their data, particularly in the age of big data and generative AI.
From a modest one petabyte to hundreds of exabytes, from 15 cents to 2 cents per gigabyte, and from simple object storage to the foundational layer for AI and analytics, Amazon S3 has embarked on an extraordinary journey. Through it all, its five enduring fundamentals—security, durability, availability, performance, and elasticity—have remained steadfast. This commitment, coupled with the remarkable achievement of maintaining complete API backward compatibility for two decades, underscores S3’s status as a cornerstone of the digital economy. As AWS looks to the future, the next 20 years of innovation on Amazon S3 promise to further solidify its role as the ubiquitous, intelligent data fabric for the world.
