

Hangzhou, China – mere hours after OpenAI’s highly anticipated GPT-5.5 release, Chinese AI laboratory DeepSeek unveiled its latest suite of open-weight models, DeepSeek-V4-Pro and DeepSeek-V4-Flash. This strategic timing, following years of U.S. government efforts to curtail China’s access to advanced AI hardware through chip export bans, suggests a refined understanding of market dynamics and a potent response from the Hangzhou-based firm. The new models boast an extraordinary one-million-token context window, a feature that dramatically expands the amount of information an AI can process simultaneously, rivaling the length of entire literary trilogies. Crucially, both models are offered at significantly lower price points than comparable Western offerings, and are entirely free for local deployment, positioning DeepSeek as a formidable disruptor in the global AI landscape.
This latest release builds upon DeepSeek’s history of impactful contributions. Their previous breakthrough, R1 in January 2025, is widely credited with a significant market reaction, reportedly wiping $600 billion from Nvidia’s market capitalization in a single trading day. The concern among investors then was whether the substantial investments made by American companies were truly necessary to achieve results that a smaller Chinese lab could produce at a fraction of the cost. The V4 release, however, represents a more nuanced, technically focused strategy, emphasizing efficiency and practical application for AI developers.
Two Models, Distinct Capabilities
DeepSeek’s new offerings are characterized by their dual nature, catering to different user needs and computational budgets.
DeepSeek-V4-Pro: The Parameter Powerhouse
The flagship model, DeepSeek-V4-Pro, is an immense undertaking with a staggering 1.6 trillion total parameters. Parameters in an AI model are akin to the synaptic connections in a human brain, storing knowledge and enabling pattern recognition. A higher parameter count theoretically allows for greater complexity and a broader knowledge base. This makes V4-Pro the largest open-source Large Language Model (LLM) currently available. However, the sheer scale is managed through an innovative "Mixture-of-Experts" (MoE) architecture, a refinement of techniques DeepSeek has been developing since its V3 iteration. In this MoE setup, only a fraction of the model’s parameters – approximately 49 billion per inference pass – are activated for any given query. This allows the model to leverage an expansive knowledge base without incurring proportional computational costs, a significant advancement in efficiency.
DeepSeek stated in its official Hugging Face model card, "DeepSeek-V4-Pro-Max, the maximum reasoning effort mode of DeepSeek-V4-Pro, significantly advances the knowledge capabilities of open-source models, firmly establishing itself as the best open-source model available today. It achieves top-tier performance in coding benchmarks and significantly bridges the gap with leading closed-source models on reasoning and agentic tasks."
DeepSeek-V4-Flash: The Efficiency Champion
Complementing the Pro version is V4-Flash, designed for speed and cost-effectiveness. This model features 284 billion total parameters, with 13 billion active during inference. DeepSeek’s own benchmarks indicate that V4-Flash achieves performance comparable to the Pro version on reasoning tasks when provided with an extended "thinking budget," making it an attractive option for applications demanding rapid responses and lower operational expenses.

The Million-Token Context: A Paradigm Shift
Both V4-Pro and V4-Flash share the groundbreaking capability of processing one million tokens. This translates to approximately 750,000 words, a capacity comparable to the entirety of J.R.R. Tolkien’s "The Lord of the Rings" trilogy, with room to spare. This vast context window is not a premium add-on but a standard feature, a significant differentiator in a market where long-context capabilities are often limited or prohibitively expensive. This feature is particularly transformative for tasks involving extensive documentation, complex codebases, or detailed historical analysis, where understanding the relationships across vast amounts of text is crucial.
DeepSeek’s Innovation: Rethinking Attention at Scale
The technical underpinnings of DeepSeek’s achievement lie in its novel approach to the "attention mechanism," the core component that allows LLMs to weigh the importance of different words in a sequence. Traditional attention mechanisms suffer from a quadratic scaling problem: doubling the context length roughly quadruples the computational cost. This has historically made processing extremely long contexts inefficient and impractical. DeepSeek’s research paper, openly available on GitHub, details two key innovations designed to circumvent this limitation.
Compressed Sparse Attention
The first innovation, Compressed Sparse Attention (CSA), operates in two stages. Initially, it compresses groups of tokens—for instance, every four tokens—into a single entry. Subsequently, instead of attending to all these compressed entries, it employs a "Lightning Indexer" to selectively identify the most relevant results for a given query. This effectively reduces the number of tokens the model needs to process from a million to a much smaller, curated set of critical segments, analogous to a librarian who doesn’t read every book but knows precisely where to find the most pertinent information.
Heavily Compressed Attention
The second method, Heavily Compressed Attention (HCA), is even more aggressive. It collapses every 128 tokens into a single entry, eliminating the need for sparse selection and offering an extremely cost-effective global overview, albeit with a potential loss of fine-grained detail. By interleaving layers of CSA and HCA, DeepSeek’s models are able to achieve both detailed comprehension and a broad understanding of context simultaneously.
The impact of these innovations is substantial. According to the technical paper, at a one-million-token context length, V4-Pro requires only 27% of the compute power used by its predecessor, V3.2. Furthermore, the KV cache, which stores the model’s contextual memory, has been reduced to a mere 10% of V3.2’s requirement. V4-Flash pushes these efficiencies even further, demanding only 10% of the compute and 7% of the memory.
Cost-Effectiveness: A Game-Changer
This dramatic improvement in efficiency translates directly into cost savings for users. When compared to the recently announced pricing for OpenAI’s GPT-5.5, which ranges from $5 input/$30 output per million tokens for the standard version to $30 input/$180 output per million tokens for GPT-5.5 Pro, DeepSeek’s pricing is remarkably competitive. V4-Pro is priced at $1.74 input and $3.48 output per million tokens, while the even more economical V4-Flash costs just $0.14 input and $0.28 output per million tokens.
Industry analysts have highlighted the profound implications of this cost differential. Saoud Rizwan, CEO of Cline, pointed out that if ride-sharing giant Uber had utilized DeepSeek models instead of Claude for its AI operations, its projected 2026 AI budget, reportedly sufficient for only four months of usage, would have been extended to cover seven years. This illustrates the potential for significant cost reductions and extended operational capabilities for businesses leveraging DeepSeek’s technology.
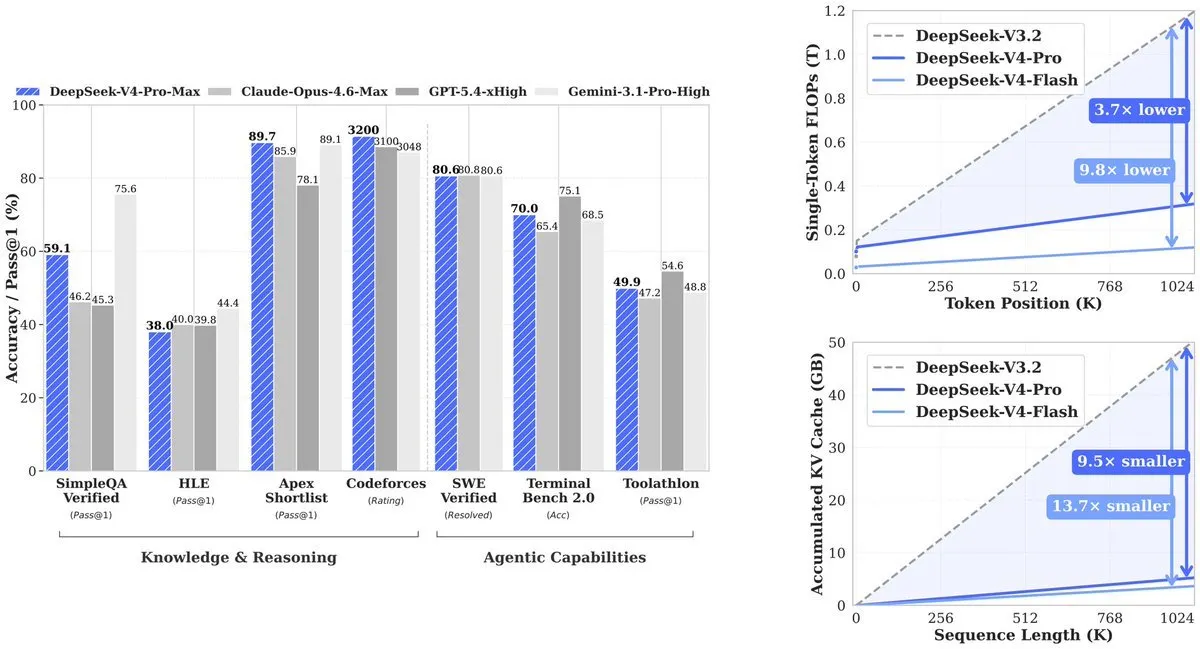
Benchmarking Performance: A Transparent Approach
DeepSeek has adopted an unusual yet commendable strategy in its technical report by openly publishing the performance gaps between its models and leading competitors. While many AI labs tend to highlight only their strongest benchmark results, DeepSeek provided a comprehensive comparison against GPT-5.4 and Gemini-3.1-Pro. The report acknowledges that V4-Pro’s reasoning capabilities lag behind these models by an estimated three to six months.
However, V4-Pro-Max demonstrates superior performance in specific, critical areas. It achieved a score of 3,206 on the Codeforces competitive programming benchmark, placing it among the top human participants. On the Apex Shortlist, a rigorous set of advanced STEM problems, V4-Pro achieved a 90.2% pass rate, surpassing both Opus 4.6 (85.9%) and GPT-5.4 (78.1%). Furthermore, on the SWE-Verified benchmark, which assesses a model’s ability to resolve real-world issues from open-source repositories, V4-Pro scored 80.6%, matching the performance of Claude Opus 4.6.
Where V4-Pro shows room for improvement includes multitasking benchmarks like MMLU-Pro, where it scored 87.5% compared to Gemini-3.1-Pro’s 91.0%. In expert knowledge evaluations such as GPQA Diamond, it scored 90.1% against Gemini’s 94.3%. Humanity’s Last Exam, a graduate-level benchmark, saw Gemini-3.1-Pro achieve 44.4% while V4-Pro scored 37.7%.
In long-context evaluations, V4-Pro leads other open-source models and outperforms Gemini-3.1-Pro on the CorpusQA benchmark, simulating real document analysis over one million tokens. However, it trails behind Claude Opus 4.6 on the MRCR benchmark, which tests a model’s ability to retrieve specific information deeply embedded within extensive text.
Built for Agents: Beyond Question Answering
The V4 release is particularly significant for developers focused on building AI agents and sophisticated applications. V4-Pro has demonstrated strong performance in various AI coding environments, including Claude Code and OpenCode. An internal survey of 85 developers who utilized V4-Pro as their primary coding agent indicated that a substantial majority found it ready for default deployment, with over 52% stating it was ready, and 39% leaning towards that conclusion. Internal DeepSeek employees reported that V4-Pro surpasses Claude Sonnet and approaches Claude Opus 4.5 in agentic coding tasks.
Artificial Analysis, an independent evaluator of AI models, ranked V4-Pro as the top open-weight model on GDPval-AA, a benchmark that assesses economically valuable knowledge work across finance, legal, and research domains using an Elo rating system. V4-Pro-Max achieved an Elo score of 1,554, surpassing GLM-5.1 (1,535) and MiniMax’s M2.7 (1,514). While Claude Opus 4.6 still holds a lead with 1,619 Elo, the gap is notably narrowing.
A significant advancement introduced with V4 is "interleaved thinking." In previous models, agents performing multi-step tasks involving tool calls (e.g., web searches, code execution) would often lose contextual memory between steps, requiring them to re-establish their understanding. V4, however, retains the full chain of thought across these tool calls, preventing "amnesia" during complex, multi-stage workflows. This capability is crucial for developing robust automated pipelines and sophisticated agentic systems.
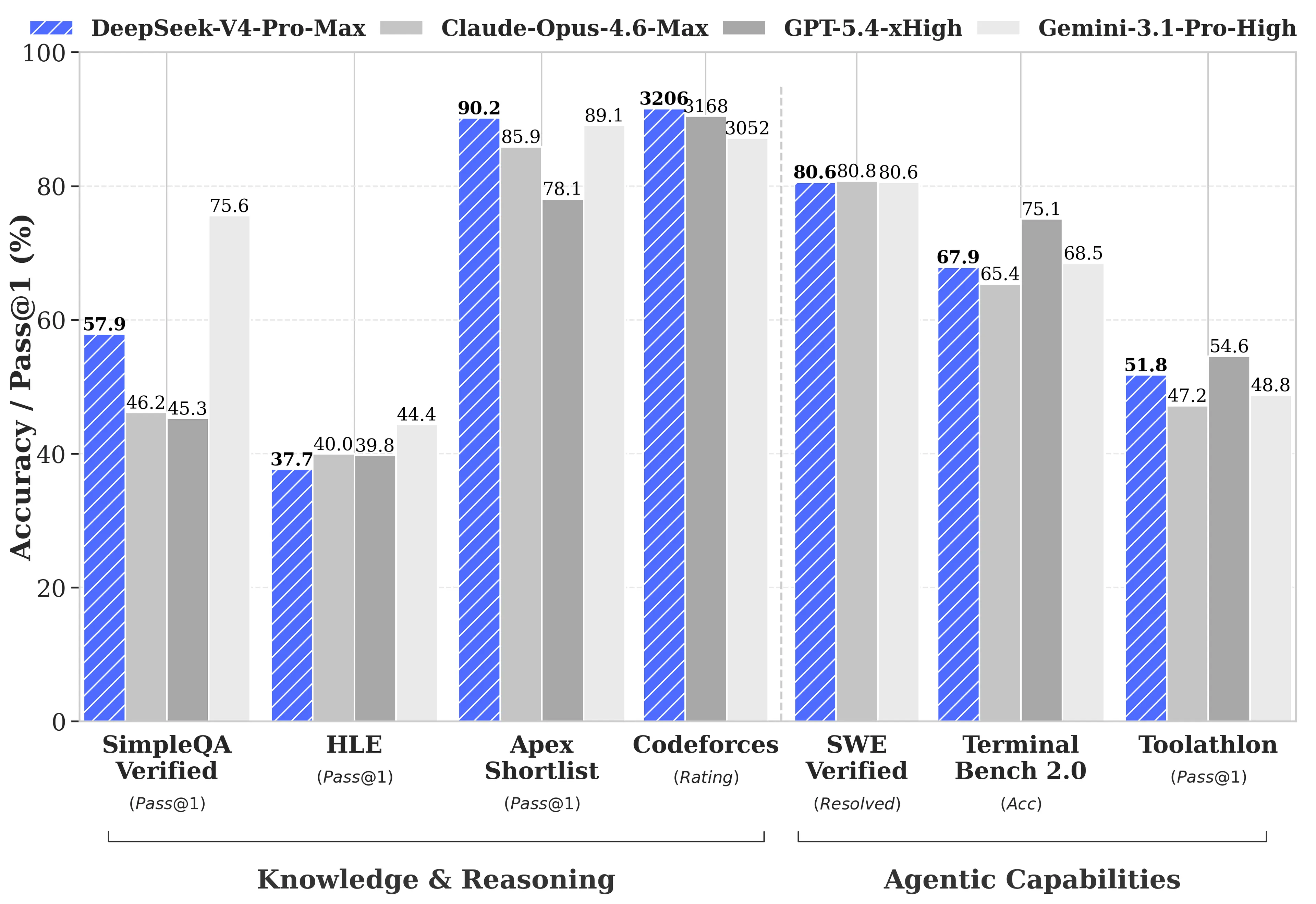
The U.S.-China AI Dynamics
The release of DeepSeek V4 occurs against a backdrop of escalating U.S.-China tensions in the artificial intelligence sector. Since 2022, the United States has implemented export controls on high-end Nvidia chips, aiming to slow China’s AI development. Paradoxically, these restrictions appear to have spurred innovation within Chinese AI labs like DeepSeek, forcing them to develop more efficient architectures and bolster domestic hardware capabilities. This strategic pivot underscores a growing self-reliance and technological advancement within China’s AI ecosystem.
The AI landscape has been particularly dynamic in recent months. Anthropic released Claude Opus 4.7 on April 16, a model noted for its coding and reasoning strengths, albeit with high token usage. Xiaomi entered the fray on April 22 with its MiMo V2.5 Pro, a fully multimodal model capable of processing image, audio, and video, priced competitively at $1 input and $3 output per million tokens. Its performance on coding benchmarks rivals that of Opus 4.6, marking Xiaomi’s rapid emergence as a significant player in the AI race. OpenAI’s GPT-5.5, launched the day prior to DeepSeek’s announcement, saw its output costs climb as high as $180 per million tokens for the Pro version. While it outperforms V4-Pro on specific benchmarks like Terminal Bench 2.0, its significantly higher cost for comparable tasks presents a clear advantage for DeepSeek. Tencent also contributed to the flurry of releases with Hy3, a state-of-the-art model emphasizing efficiency.
Implications for Developers and Enterprises
The influx of advanced AI models, particularly DeepSeek’s V4, presents a compelling case for re-evaluating AI adoption strategies.
For enterprises, the economic calculus has fundamentally shifted. A leading open-source model that offers unparalleled context windows at a fraction of the cost of proprietary alternatives makes large-scale document processing, legal analysis, and code generation pipelines significantly more affordable. The one-million-token context window enables the ingestion of entire codebases or regulatory filings in a single request, streamlining complex workflows. Furthermore, the open-source nature of DeepSeek’s models allows for customization and fine-tuning to meet specific business needs, offering greater flexibility and control.
For individual developers and smaller teams, V4-Flash emerges as a particularly attractive option. Its exceptionally low cost per token makes advanced AI capabilities accessible to a broader range of projects. DeepSeek has already integrated V4-Flash into its existing chat and reasoning endpoints, meaning users of these services are already benefiting from its performance.
While DeepSeek’s V4 models are currently text-only, the company has indicated ongoing development in multimodal capabilities, an area where competitors like Xiaomi and OpenAI currently hold an advantage. Both V4-Pro and V4-Flash are released under the MIT license, ensuring broad accessibility and encouraging further community development. DeepSeek’s older chat and reasoner endpoints are scheduled for retirement on July 24, 2026, signaling a full transition to the V4 architecture. This strategic release, marked by technical innovation, competitive pricing, and a transparent approach to performance, firmly positions DeepSeek as a major force shaping the future of artificial intelligence.