
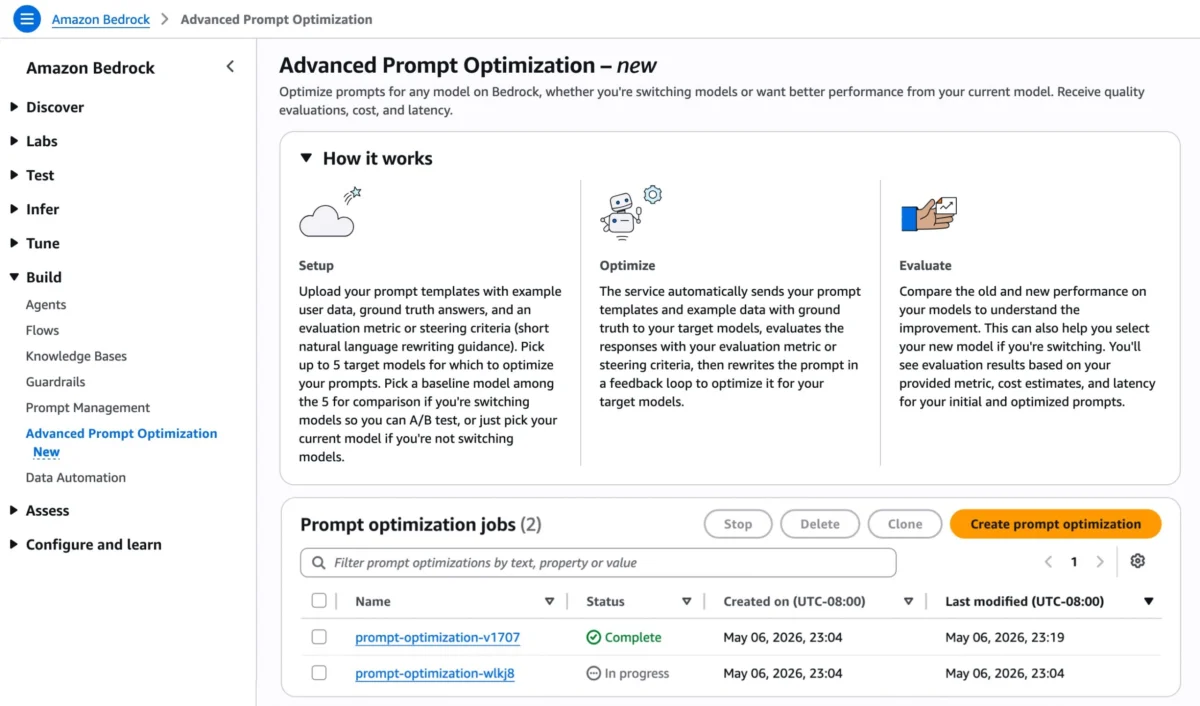
Amazon Web Services (AWS) today unveiled Amazon Bedrock Advanced Prompt Optimization, a sophisticated new capability designed to streamline and enhance the process of prompt engineering for large language models (LLMs) hosted on its fully managed service, Amazon Bedrock. This innovative tool empowers developers and organizations to systematically refine their prompts for any model available on Bedrock, simultaneously comparing optimized prompts across up to five different models. The announcement marks a significant step forward in simplifying model migration and achieving superior performance from existing AI deployments, addressing a critical bottleneck in the rapidly evolving field of generative artificial intelligence.
Addressing the Core Challenge of Prompt Engineering
The advent of generative AI, particularly large language models (LLMs), has ushered in an era of unprecedented innovation, enabling applications ranging from sophisticated content generation and summarization to complex code assistance and data analysis. At the heart of interacting with these powerful models lies "prompt engineering"—the art and science of crafting effective inputs (prompts) to elicit desired outputs. While crucial, prompt engineering has traditionally been a highly iterative, manual, and often inefficient process, demanding significant expertise and trial-and-error. Developers frequently spend considerable time fine-tuning prompts to achieve optimal results, dealing with issues such as model hallucination, irrelevant responses, or suboptimal performance across various use cases.

This challenge is further compounded when organizations consider migrating between different LLMs or integrating new models, each with its unique characteristics and sensitivities to prompt structure. The lack of standardized, automated optimization tools has often led to prolonged development cycles, increased operational costs due to inefficient token usage, and inconsistent application performance. Amazon Bedrock Advanced Prompt Optimization directly confronts these issues by introducing a structured, metric-driven approach to prompt refinement.
Deep Dive into Advanced Prompt Optimization Capabilities
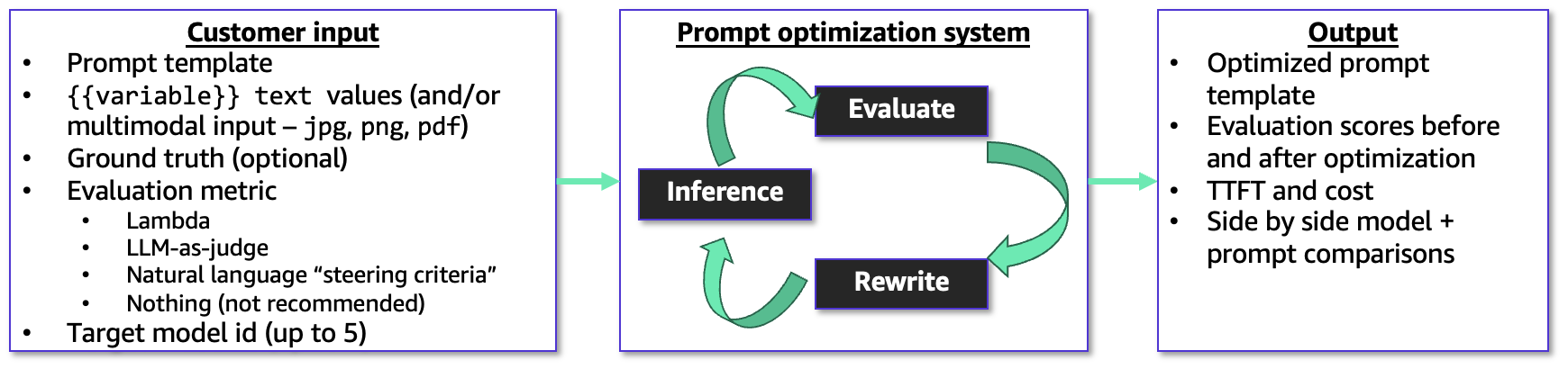
The new optimization tool offers a comprehensive framework for prompt improvement. Users initiate the process by providing a prompt template, which may include variable placeholders for dynamic content. Crucially, they supply example user inputs for these variables, alongside ground truth answers—the ideal responses expected from the model. This ground truth data forms the basis for evaluating the model’s performance. An evaluation metric, chosen by the user, guides the optimization process, ensuring that refinements are aligned with specific performance objectives.
One of the standout features is its robust support for multimodal user inputs. The optimizer can process png, jpg, and pdf files as inputs to prompt templates. This capability is particularly vital for tasks involving document analysis, image interpretation, or other complex scenarios where textual input alone is insufficient. For instance, an organization might use this to optimize prompts for an LLM designed to extract specific data points from scanned invoices or analyze visual elements in product images, significantly broadening the scope of AI applications on Bedrock.

To guide the optimization, users can leverage several powerful mechanisms:
- AWS Lambda Function: For highly customized scoring logic, users can provide an AWS Lambda function. This allows for intricate, programmable evaluation criteria tailored to unique business requirements, offering unparalleled flexibility in defining what constitutes an "optimized" response.
- LLM-as-a-Judge Rubric: This method employs another LLM to act as an impartial judge, evaluating responses based on a custom rubric provided in natural language. This democratizes sophisticated evaluation, making it accessible even without deep programming expertise in scoring.
- Short Natural Language Description: For simpler scenarios, users can provide a concise natural language description to steer the optimization. This intuitive approach allows for quick iterations and adjustments without the need for complex setup.
The prompt optimizer operates within a sophisticated, metric-driven feedback loop. It iteratively refines the prompt template and observes the resulting model responses against the predefined evaluation metric. This continuous process aims to achieve the best possible alignment between the prompt and the desired output, optimizing for accuracy, relevance, conciseness, or any other specified performance indicator. Upon completion, the tool outputs both the original and the final optimized prompt templates, along with detailed evaluation scores, estimated costs associated with model inference, and latency metrics. This comprehensive output empowers developers to make informed decisions about prompt deployment and model selection.
A Streamlined Workflow for Enhanced Efficiency
The operational flow for utilizing Amazon Bedrock Advanced Prompt Optimization is designed for ease of use and integrates seamlessly with the existing Bedrock console. Users can navigate to the "Advanced Prompt Optimization" page and select "Create prompt optimization."
A key advantage of the new feature is its capacity to compare prompt performance across multiple models simultaneously. Users can select up to five inference models for optimization. This is invaluable for organizations contemplating a model migration, as they can designate their current model as a baseline and compare its performance against up to four alternative models. This side-by-side evaluation provides concrete data to support migration decisions, ensuring that a new model not only meets but potentially exceeds performance expectations without introducing regressions on critical use cases. For those not changing models, selecting only the current model allows for a clear "before and after" comparison of optimization benefits, quantifying the improvements gained.
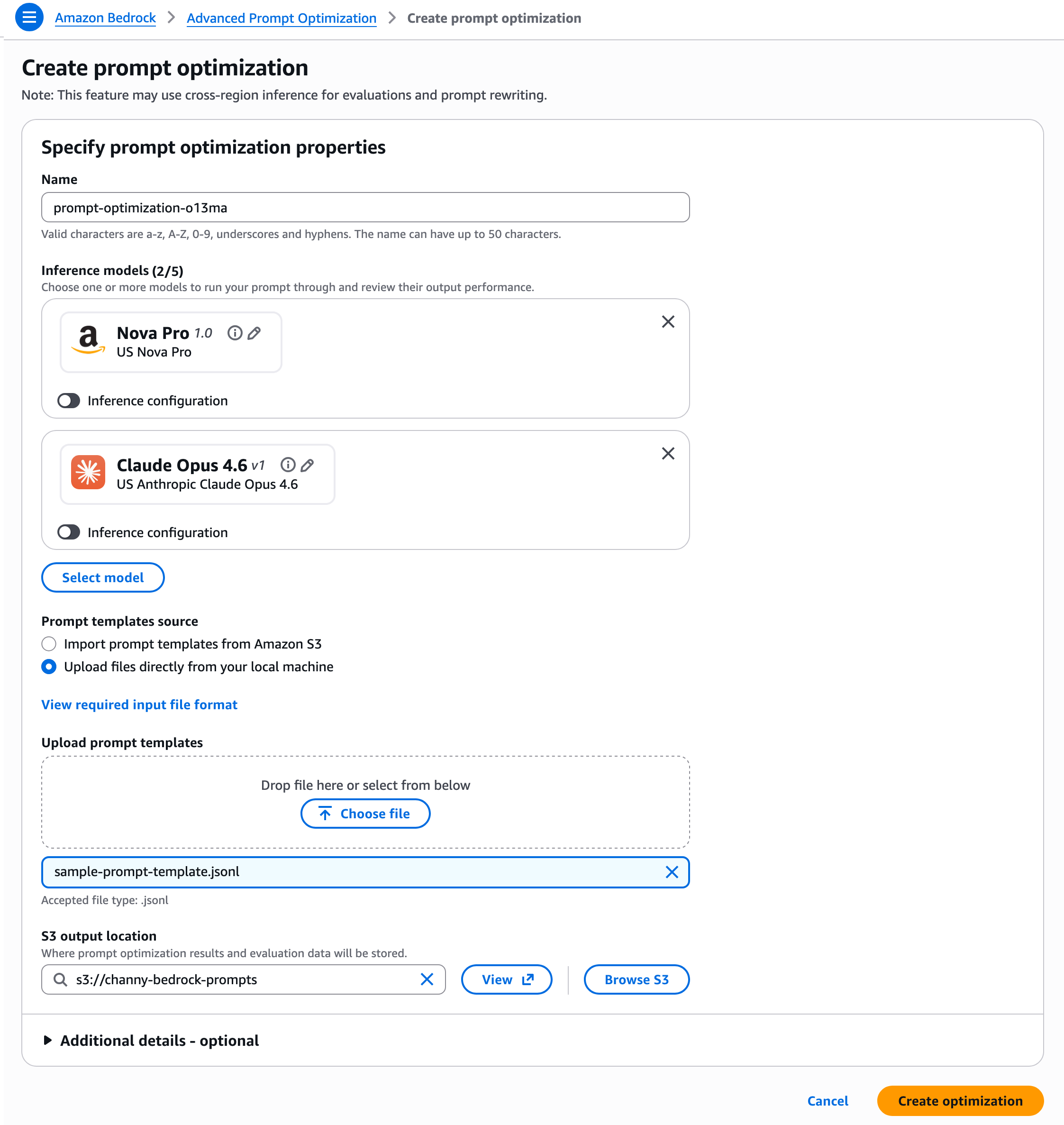
Preparation of prompt templates involves structuring them in a JSONL (JSON Lines) format. Each JSON object, representing a prompt template and its associated data, must reside on a single line. The JSONL schema requires specific fields such as version, templateId, promptTemplate, steeringCriteria (optional), customEvaluationMetricLabel (required if using custom LLM-as-a-judge or Lambda function), customLLMJConfig (for LLM-as-a-judge), evaluationMetricLambdaArn (for Lambda-based evaluation), and evaluationSamples. The evaluationSamples array is crucial, containing inputVariables and referenceResponse (optional ground truth). For multimodal inputs, the inputVariablesMultimodal array allows specifying type (PDF or IMAGE) and the s3Uri to the file in Amazon S3.
Once the JSONL file is prepared, users can either upload it directly or import prompt templates from Amazon Simple Storage Service (Amazon S3). They also specify an S3 output location where the optimization results and evaluation data will be securely stored. Following these steps, choosing "Create optimization" initiates the automated process. Amazon Bedrock then takes over, sending prompt templates and example data to the chosen inference models, evaluating responses against the specified metrics, and iteratively rewriting prompts to achieve optimal performance.
Broader Impact and Strategic Implications
The introduction of Amazon Bedrock Advanced Prompt Optimization is poised to have a far-reaching impact across the AI development landscape:
- Democratization of Advanced Prompt Engineering: By automating and simplifying complex optimization tasks, AWS is effectively democratizing advanced prompt engineering. Developers who may not possess deep expertise in crafting highly sophisticated prompts can now leverage the tool to achieve expert-level results, lowering the barrier to entry for building high-performing AI applications.
- Accelerated Development Cycles: The manual nature of prompt tuning has been a significant time sink. This new tool drastically reduces the iteration time, allowing developers to experiment with different models and prompt variations much more rapidly. This acceleration translates directly into faster time-to-market for AI-powered products and features.
- Cost Optimization: Better-optimized prompts lead to more concise and accurate responses, which can significantly reduce the number of tokens consumed during inference. This is a direct pathway to cost savings, especially for applications with high query volumes. Furthermore, the ability to effectively migrate to more cost-efficient models without sacrificing performance provides an additional avenue for economic benefits.
- Enhanced AI Application Performance: By systematically optimizing prompts against defined metrics, organizations can ensure their AI applications deliver consistently higher quality, more relevant, and more accurate outputs. This directly contributes to improved user experiences and better business outcomes. For instance, a customer service chatbot optimized with this tool could provide more precise answers, reducing resolution times and improving customer satisfaction.
- Simplified Model Migration and Management: The simultaneous comparison feature is a game-changer for organizations navigating the dynamic LLM ecosystem. It provides empirical data to justify model choices, mitigating risks associated with transitioning to new models. This flexibility allows businesses to adopt the latest, most performant, or most cost-effective models as they become available on Bedrock, future-proofing their AI investments.
- Multimodal AI Advancement: The explicit support for multimodal inputs (images, PDFs) positions Bedrock Advanced Prompt Optimization as a crucial tool for a new generation of AI applications that integrate various data types. This opens up possibilities in fields like healthcare (analyzing medical images alongside patient records), manufacturing (interpreting visual inspections and maintenance logs), and legal services (processing contracts and visual evidence).
Availability and Pricing
Amazon Bedrock Advanced Prompt Optimization is available starting today across a wide range of AWS Regions, including US East (N. Virginia, Ohio), US West (Oregon), Asia Pacific (Mumbai, Seoul, Singapore, Sydney, Tokyo), Canada (Central), Europe (Frankfurt, Ireland, London, Zurich), and South America (São Paulo) Regions. This broad availability ensures that a global base of AWS customers can immediately begin leveraging this new capability.
Regarding pricing, organizations will be charged based on the Bedrock model-inference tokens consumed during the optimization process. These charges are applied at the same per-token rates as regular Bedrock inference, ensuring transparency and predictability in costs. Detailed pricing information is available on the Amazon Bedrock pricing page.
AWS encourages developers and organizations to explore the advanced prompt optimization capabilities via the Amazon Bedrock console or by utilizing the CreateAdvancedPromptOptimizationJob API. For further learning and practical implementation, comprehensive documentation on advanced prompt optimization in Bedrock and sample code repositories on GitHub are readily available. Feedback on the new feature can be submitted through AWS re:Post for Amazon Bedrock or via standard AWS Support channels, demonstrating AWS’s commitment to continuous improvement based on user input. This release underscores AWS’s dedication to providing cutting-edge tools that empower developers to build, deploy, and scale sophisticated generative AI applications with greater efficiency and effectiveness.
