
In an era defined by an exponential growth of digital information, the demand for sophisticated information retrieval systems has never been more critical. Traditional keyword-based search, while foundational, increasingly struggles to meet the nuanced requirements of modern data environments, frequently failing when a user’s query does not precisely match the literal terms within a document. For instance, a support engineer searching for "login keeps failing" would likely miss a crucial ticket titled "OAuth2 token refresh race condition," despite its direct relevance. This fundamental disconnect between literal text and underlying intent is precisely the challenge that context-aware semantic search aims to overcome, offering a powerful paradigm shift in how we interact with and extract value from vast data repositories.
The Evolution Beyond Keyword Search
The limitations of traditional keyword search are well-documented. Relying solely on lexical matches, it often delivers either an overwhelming volume of loosely related results or, conversely, misses highly relevant documents due to variations in vocabulary or phrasing. This inefficiency translates directly into lost productivity, increased operational costs, and diminished user satisfaction across diverse sectors from corporate knowledge management to public information services. The digital age, particularly within enterprise environments, generates immense volumes of unstructured data—emails, support tickets, reports, legal documents, and research papers—each containing invaluable insights often hidden behind linguistic ambiguities. The need for a system that understands the meaning behind a query, rather than just the words, became paramount.
Semantic Search: Understanding Meaning Through Embeddings
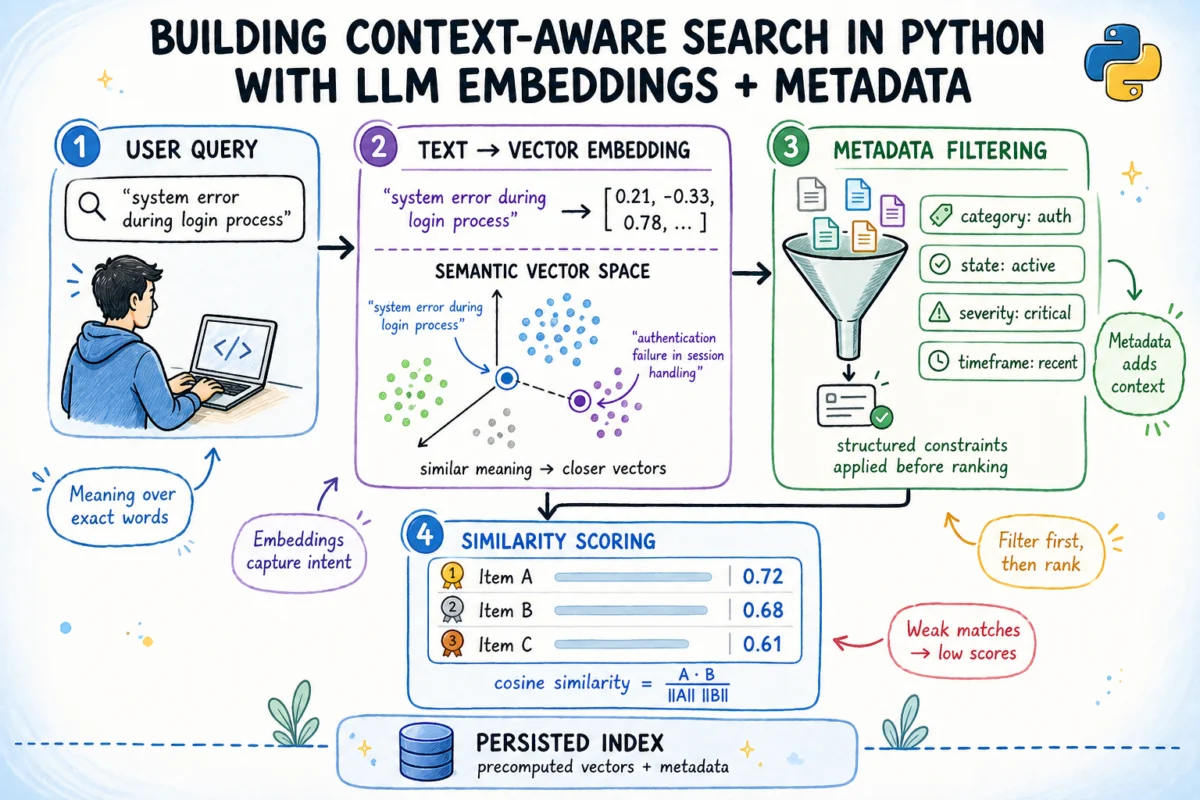
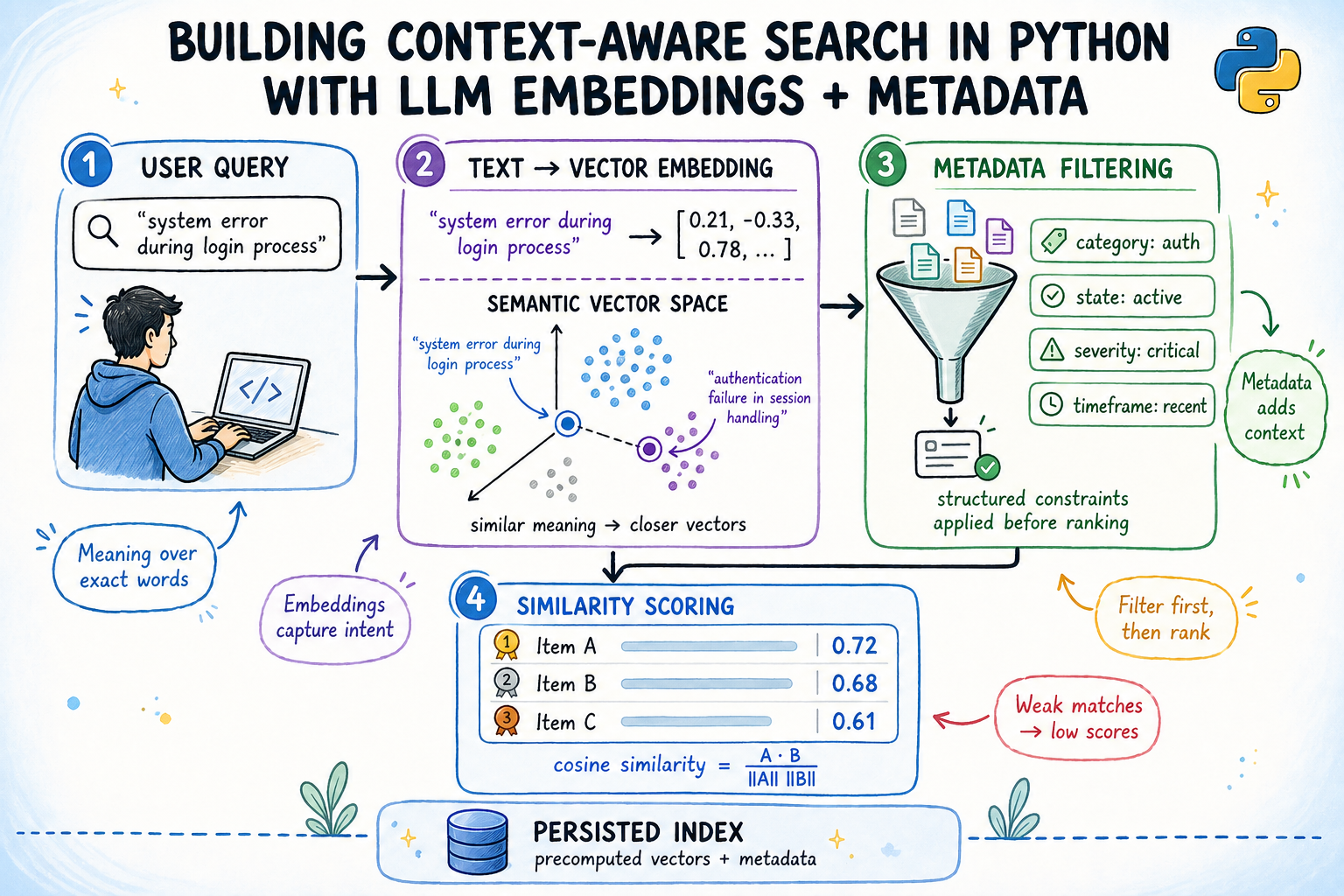
Semantic search represents a significant leap forward by converting text into dense vector representations known as embeddings. These high-dimensional numerical vectors are generated by sophisticated machine learning models, often large language models (LLMs) or their smaller, specialized variants, which are trained to map semantically similar pieces of text to vectors that are close to each other in a multi-dimensional space. This geometric proximity, where meaning dictates closeness rather than exact word overlap, allows the system to identify relationships and relevance that keyword searches would entirely miss.
For example, the phrases "car breakdown" and "automobile malfunction" would generate very similar embeddings, allowing a semantic search engine to recognize their equivalence even if the exact words are not present in a document. This capability is powered by models like all-MiniLM-L6-v2, a compact yet powerful sentence embedding model that maps any given sentence to a 384-dimensional vector. Operating efficiently on standard CPU architectures and requiring a mere 22 MB download (cached locally after the first use), all-MiniLM-L6-v2 offers an accessible entry point into high-performance semantic search without the need for specialized hardware or complex API integrations.
The mathematical underpinning of semantic similarity within these vector spaces is often cosine similarity. This metric measures the cosine of the angle between two vectors, ranging from -1 (indicating opposite directions or meanings) to 1 (indicating identical directions or meanings). In practical applications, unrelated documents typically yield scores around 0.1–0.25, while strong semantic matches register above 0.6. A crucial optimization involves ensuring that all embedding vectors are L2-normalized, meaning their length is precisely 1.0. When vectors are unit-normalized, their cosine similarity simplifies to a straightforward dot product, dramatically accelerating the scoring process as the entire candidate pool can be ranked through a single, highly efficient matrix multiplication. This optimization is critical for real-time performance in production systems dealing with large datasets.
The Indispensable Role of Structured Metadata Filtering
While embeddings excel at capturing semantic content, they inherently do not encode contextual attributes such as authorship, creation date, team ownership, or document status. These crucial details, often structured as metadata, reside outside the textual content and are vital for narrowing down search results to truly relevant and actionable information. Combining semantic understanding with robust metadata filtering is what elevates a basic semantic search to a truly context-aware system.
Consider a legal professional searching for case precedents. While semantic search might find all documents discussing "contractual obligations," metadata filters could then restrict these results to "cases decided in the last year," "involving specific jurisdictions," or "pertaining to corporate law." Similarly, in an e-commerce context, a search for "running shoes" could be refined by "brand: Nike," "size: 9," and "customer rating: 4+ stars." This layered approach ensures that the system not only understands what someone is asking but also respects critical contextual constraints at the same time. The ability to filter by date, status, team, priority, or any other structured attribute significantly enhances precision and user experience, making the search engine far more useful in real-world scenarios.
Building the System: A Python-Based Approach
Constructing such a system in Python involves several distinct yet interconnected steps, beginning with dependency installation: pip install sentence-transformers numpy.
1. Setting Up the Dataset: Engineering Support Tickets
To illustrate the practical application, a corpus of 20 engineering support tickets serves as an excellent case study. These tickets are structured as plain Python dictionaries, each containing a text field for embedding and various metadata fields like id, team (infrastructure, backend, frontend), status (open, resolved), priority (high, medium, low), and created date (spanning a two-month window). This diverse metadata allows for comprehensive filtering scenarios. For instance, a typical dataset might reveal a distribution of 14 open tickets and 6 resolved tickets, spread across the different teams, mimicking a realistic operational environment. The full dataset, while truncated in the article for brevity, is readily available on GitHub, ensuring reproducibility for developers.
2. Generating Embeddings: Transforming Text into Vectors
The SentenceTransformer library is instrumental here. After initializing the all-MiniLM-L6-v2 model, the encode method processes the text field from all support tickets. The normalize_embeddings=True parameter is critical, as it ensures all output vectors have an L2 norm of 1.0. This pre-normalization streamlines the subsequent cosine similarity calculations, transforming them into simple dot products and significantly boosting performance. The output is a NumPy array of shape (N, D), where N is the number of documents (20 in this example) and D is the dimensionality of the embeddings (384).
3. Building the Context-Aware Index
The core of the system is the ContextAwareIndex class. This class holds both the embedding matrix and the original document metadata. Its search method accepts a query string and a series of optional keyword arguments corresponding to the metadata fields (team, status, priority, after, before, min_score).
The key design principle within the search method is to perform metadata filtering before semantic scoring. This is a crucial optimization:
- First, the query string is embedded into the same vector space.
- Next, a boolean mask is constructed. This mask is initialized to
Truefor all documents and then iteratively updated toFalsefor any document that fails to meet a specified metadata filter condition (e.g., ifteamis specified anddoc["team"] != team). - Only the embeddings of documents that pass all metadata filters (i.e., where the mask is
True) are then subjected to the dot product calculation with the query embedding. This efficiently reduces the computational load by discarding irrelevant documents early. - Finally, results are filtered by a
min_scorethreshold, sorted by semantic similarity in descending order, and the top-k matches are returned, enriched with their calculated similarity scores.
This pre-scoring filtering mechanism ensures that computational resources are not wasted on documents that would be discarded anyway and guarantees that the min_score threshold effectively prunes low-confidence matches from the contextually relevant set.
4. Running Queries: Demonstrating Contextual Power
The system’s efficacy is best demonstrated through practical queries:
-
Query 1: Searching Without Filters
A baseline search for "authentication token expiry and session management" without any metadata constraints reveals the semantic capabilities. The top results are likely backend tickets related to session management, OAuth2 tokens, and JWT verification, even if the exact query terms are not present in the ticket descriptions. This highlights the model’s ability to understand the underlying semantic intent. -
Query 2: Filtering by Status and Date
Applying filters to the identical query—e.g.,status="open"andbefore=date(2025, 11, 10)—drastically changes the result set. This simulates a workflow where a support team might only be interested in unresolved issues within a specific timeframe. The system intelligently prunes tickets that are resolved or fall outside the date window, delivering a more focused and actionable list of high-priority, open backend issues. This showcases the system’s ability to combine semantic understanding with precise temporal and status constraints. -
Query 3: Cross-Team Search with Priority Filter
A query like "resource exhaustion and memory pressure under load," constrained bystatus="open"andpriority="high", demonstrates the system’s ability to traverse team boundaries based on semantic content. Resource exhaustion issues, whether manifesting as Kubernetes OOMKilled errors (infrastructure) or database connection pool exhaustion (backend), share a common semantic theme. The filters ensure that only critical, open issues across relevant teams are presented, providing a holistic view of urgent operational problems.
5. Persisting the Index: Efficiency in Production
In a production environment, re-encoding the entire corpus every time the application starts is inefficient and resource-intensive. The solution lies in persisting the generated embeddings and metadata to disk. The embedding matrix can be saved as a binary .npy file using numpy.save, while the metadata (a list of dictionaries) is stored as JSON. A small but critical step is converting Python date objects within the metadata to ISO format strings before JSON serialization, and then parsing them back into date objects upon loading.
This persistence strategy ensures that subsequent application startups are significantly faster. The SentenceTransformer model benefits from local caching, loading almost instantly after its initial download. The ContextAwareIndex is then rebuilt by simply loading the pre-computed embeddings and metadata from disk, bypassing the time-consuming embedding generation process. This pattern is fundamental for building scalable and responsive semantic search applications.
Broader Impact and Future Implications
The development of context-aware semantic search engines marks a pivotal advancement in information retrieval. Its implications extend far beyond support ticket management:
- Enterprise Search: Revolutionizing how employees find information within large organizations, enabling faster access to knowledge bases, internal documents, and collaborative insights.
- Customer Support: Empowering chatbots and support agents with the ability to understand complex customer queries and provide accurate, contextually relevant solutions.
- Legal Discovery: Streamlining the process of reviewing vast quantities of legal documents, identifying pertinent clauses, precedents, and evidence with greater accuracy and speed.
- Research and Development: Accelerating scientific discovery by helping researchers navigate massive academic literature databases, connecting disparate ideas based on semantic links.
- E-commerce: Enhancing product discovery by understanding user intent beyond keywords, leading to more relevant recommendations and improved sales.
Looking ahead, the field is continuously evolving. The increasing sophistication of large language models promises even richer semantic understanding, potentially leading to multimodal search (combining text, images, and audio). Real-time indexing of dynamic data streams and the development of more robust, scalable vector databases (like Milvus or Pinecone) are areas of active research and development, addressing the challenges of managing and querying petabyte-scale embedding datasets. The convergence of advanced AI with practical engineering principles, as demonstrated by this Python-based system, paves the way for a future where information is not just found, but truly understood.
