
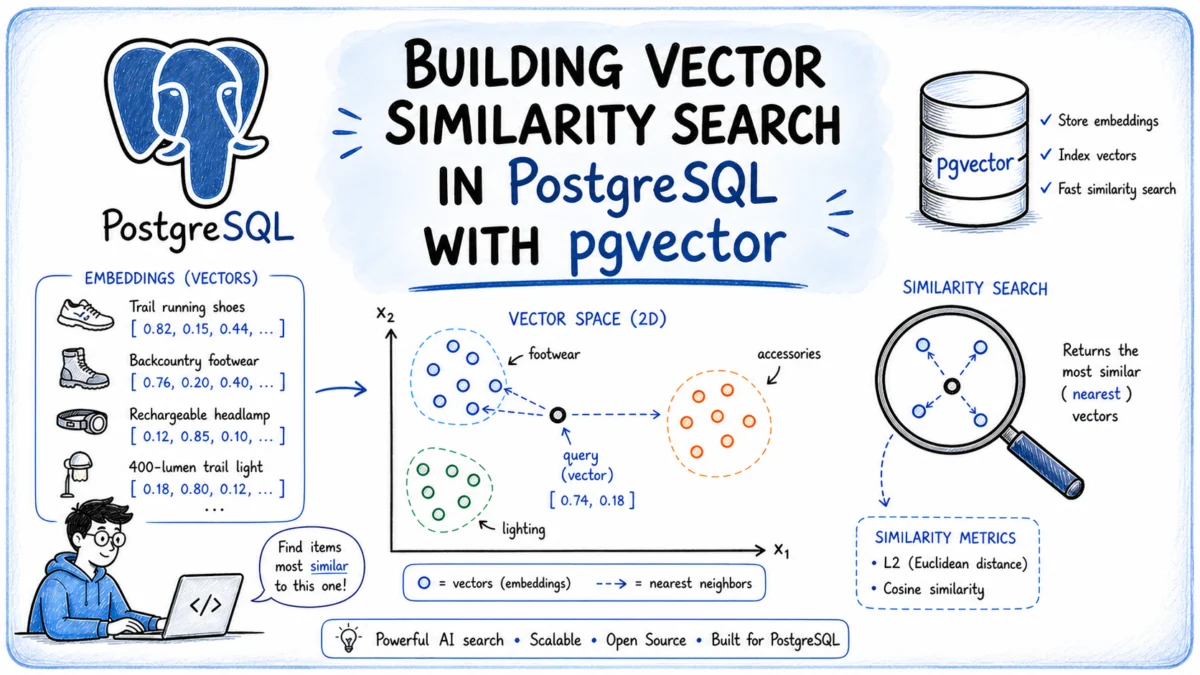
The Paradigm Shift to Semantic Search
Traditional search mechanisms, which rely heavily on keyword indexes, often fall short when user intent is expressed in natural language or when the lexicon used in a query does not precisely align with the terms present in the underlying data. For instance, a user query like "something warm and breathable for high-altitude trekking" would yield suboptimal results from a keyword index if the product descriptions use terms such as "insulating," "moisture-wicking," or "mountaineering gear" without explicitly mentioning "warm" or "breathable." This limitation highlights a fundamental gap in how computers have historically processed human language and intent.
The advent of similarity search directly addresses this challenge. Instead of a direct lexical match, similarity search leverages sophisticated machine learning models to understand the meaning or context of a query and compare it against the meaning embedded within data records. This enables a system to connect a user’s natural language intent to highly relevant records, even if the specific words differ entirely. This capability is becoming increasingly critical across diverse applications, from e-commerce product recommendations and content discovery platforms to enterprise knowledge management and intelligent chatbots.
Understanding Vector Embeddings: The Core of Semantic Meaning
At the heart of similarity search are vector embeddings. A vector embedding is a numerical representation of a piece of data – be it a word, a phrase, a sentence, an image, or an entire document – as a list of floating-point numbers. These numbers are generated by a machine learning model, often a neural network, that has been extensively trained to capture the semantic essence of the input. The fundamental principle is that semantically similar content will produce embeddings that are numerically "close" to each other in a high-dimensional numeric space. Conversely, dissimilar content will result in vectors that are farther apart.
Consider two phrases: "a device for illuminating the path ahead in the dark" and "a portable light source for nighttime exploration." While the wording differs, an advanced embedding model would map these phrases to vectors that are in close proximity within the vector space, reflecting their shared meaning related to portable lighting. This proximity is precisely what powers similarity search: a user’s query is transformed into an embedding, and the system then identifies stored embeddings that are numerically closest to it, retrieving the corresponding data rows.
The dimensionality of these vectors – the number of floating-point numbers in the list – is determined by the specific embedding model used. Common models like OpenAI’s text-embedding-ada-002 typically produce 1536-dimensional vectors, while other models may range from a few dozen to several thousand dimensions. The choice of model impacts the quality and nuance of semantic understanding, with the MTEB Leaderboard serving as a standard reference for comparing model performance. Crucially, the dimension configured for the vector column in the database must precisely match the output dimension of the chosen embedding model to ensure data integrity and query functionality.
pgvector: Bringing Native Vector Search to PostgreSQL
For years, implementing semantic search often necessitated the deployment of specialized vector databases or complex hybrid architectures. This approach introduced operational overhead, data synchronization challenges, and fragmented data governance. pgvector, an open-source extension for PostgreSQL, fundamentally alters this landscape by adding native vector search capabilities directly to an existing PostgreSQL database. This means vector embeddings can reside alongside the relational data they describe, preserving PostgreSQL’s robust transactional guarantees, JOIN semantics, point-in-time recovery, and the full power of the SQL query language.
The pgvector extension introduces a vector data type, allowing for the efficient storage of embeddings. It also provides SQL distance operators, which are essential for ordering query results based on similarity. Furthermore, pgvector offers two primary index types, Hierarchical Navigable Small Worlds (HNSW) and Inverted File Flat (IVFFlat), designed to accelerate nearest-neighbor lookups, making similarity search performant even at massive scales. Beyond standard floating-point vectors, the extension supports specialized formats like half-precision, binary, and sparse vectors, catering to diverse use cases and optimization needs.
Installation and Setup
Installing pgvector is a straightforward process, supporting PostgreSQL 13 and newer versions. For Debian and Ubuntu systems, the APT package manager provides the quickest route: sudo apt install postgresql-18-pgvector (replacing 18 with the relevant PostgreSQL major version). For other Linux distributions or for more control, compiling from source is a viable option, involving cloning the pgvector repository, navigating to its directory, and executing make followed by make install. macOS users benefit from Homebrew, simplifying the installation. Once the extension binaries are installed, it must be enabled within the target database using the SQL command: CREATE EXTENSION IF NOT EXISTS vector;. This command needs to be executed only once per database.
Structuring Data for Semantic Search
To demonstrate, consider building a product catalog for an outdoor gear store. Each product requires a text description, which will be transformed into an embedding for semantic search. A typical table schema might look like this:
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
category TEXT,
description TEXT,
price NUMERIC(8,2),
embedding vector(1536)
);Here, the embedding column is defined with vector(1536), signifying that it will store 1536-dimensional vectors, aligning with a common embedding model output. For illustrative purposes and to simplify understanding of vector proximity, a smaller 3-dimensional vector table can be used, where specific components of the vector might correlate with distinct product attributes:
CREATE TABLE gear (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
category TEXT,
description TEXT,
embedding vector(3)
);Populating with Embedding Data
In a production environment, populating the embedding column involves calling an external embedding API (e.g., from OpenAI, Cohere, or a self-hosted model) for each product description at the time of insertion or update. The returned vector is then stored. For pedagogical clarity, hypothetical 3-dimensional values can be hand-crafted to illustrate the clustering principle: footwear items might share similar first-component values, lighting items cluster around the second, and backpacks around the third, demonstrating how semantic similarity translates to numerical proximity.
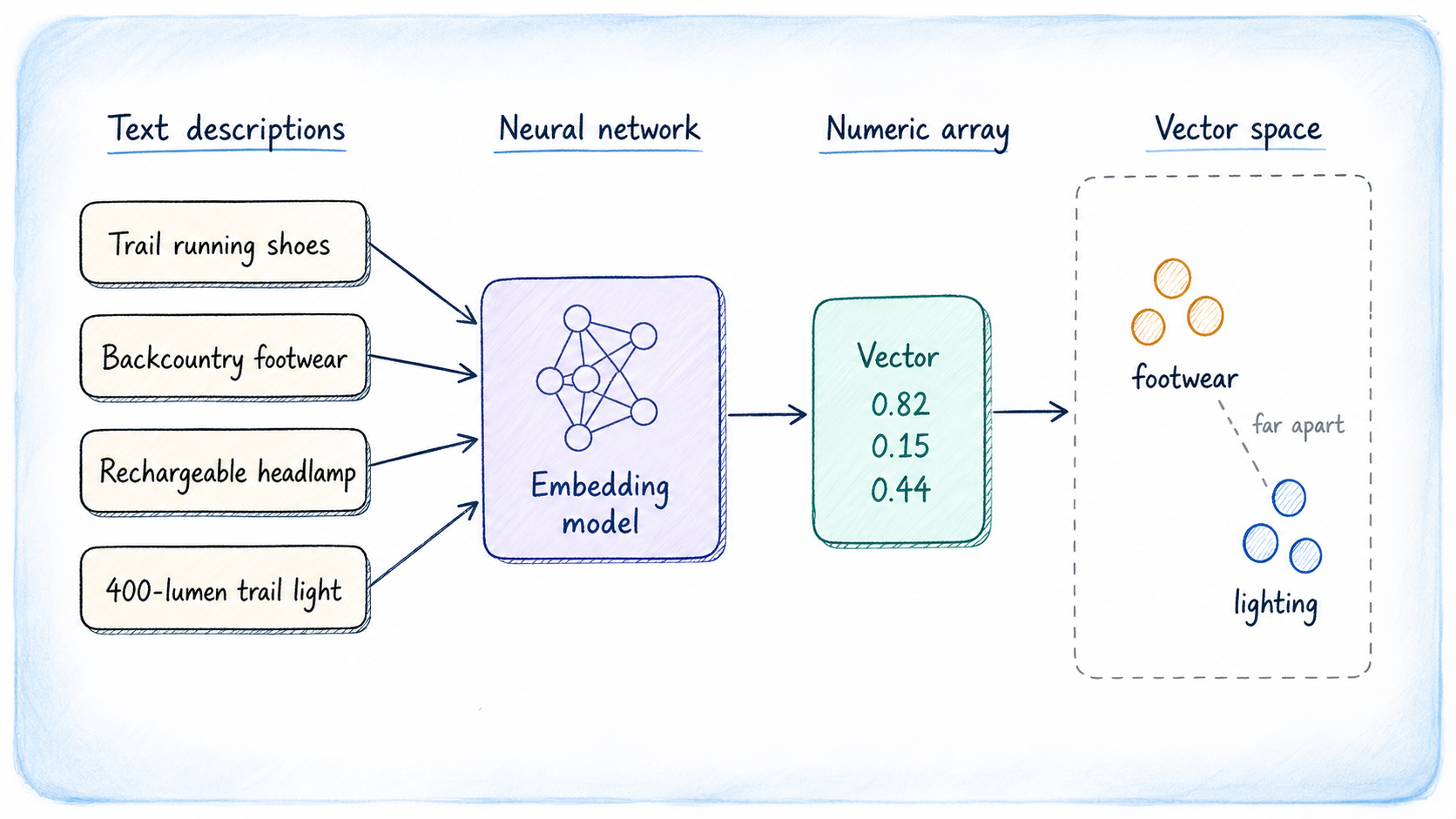
INSERT INTO gear (name, category, description, embedding) VALUES
('Merrell Moab 3 GTX', 'Footwear', 'Waterproof hiking boot for all-day trail comfort', '[0.82, 0.15, 0.44]'),
('Salomon Speedcross 6', 'Footwear', 'Aggressive trail runner for muddy and technical terrain', '[0.79, 0.21, 0.38]'),
('Black Diamond Spot 400', 'Lighting', 'Rechargeable headlamp with 400 lumens and waterproofing', '[0.11, 0.88, 0.22]'),
('Petzl ACTIK CORE', 'Lighting', 'Lightweight headlamp for hiking and camping', '[0.09, 0.91, 0.19]'),
('Osprey Atmos AG 65', 'Backpacks', 'Anti-gravity backpack for multi-day backcountry trips', '[0.55, 0.30, 0.77]'),
('Gregory Baltoro 75', 'Backpacks', 'High-volume pack for extended wilderness expeditions', '[0.58, 0.28, 0.81]');Executing Similarity Queries
Once the data and embeddings are in place, querying for similar items becomes straightforward. If a user searches for "trail footwear for rough terrain," and the application converts this query into a vector, say [0.80, 0.19, 0.40], the nearest neighbors can be retrieved using pgvector’s distance operators:
SELECT
name,
category,
description,
embedding <-> '[0.80, 0.19, 0.40]' AS distance
FROM gear
ORDER BY distance
LIMIT 3;The <-> operator computes the L2 (Euclidean) distance, which measures the straight-line distance between two points in vector space. Lower distance values indicate higher similarity. The expected output would prioritize the footwear items, followed by less relevant categories based on their numerical proximity to the query vector.
name | category | distance
-------------------+-----------+----------
Salomon Speedcross 6 | Footwear | 0.0300
Merrell Moab 3 GTX | Footwear | 0.0600
Osprey Atmos AG 65 | Backpacks | 0.4599
(3 rows)Selecting the Appropriate Distance Metric
pgvector offers a range of distance operators, each suited to different data characteristics and embedding model outputs. The choice of metric significantly impacts retrieval quality.
- L2 (Euclidean) distance (
<->): Measures the straight-line distance. Useful for unnormalized embeddings where magnitude matters. - Cosine distance (
<=>): Measures the angle between vectors, effectively ignoring their magnitude. This is often the preferred metric for normalized embeddings produced by many LLM-based APIs, as semantic meaning is typically encoded in direction. - Negative Inner Product (
<#>): Related to cosine similarity, often used when embeddings are normalized, where a higher inner product means greater similarity. The negative inner product allows for ordering in ascending order for "closest." - L1 (Manhattan) distance (
<+>): Sum of absolute differences along each dimension. - Hamming distance (
<~>) and Jaccard distance (<%): Specialized for binary vectors.
For most modern LLM-based embedding APIs that produce normalized or near-normalized vectors, cosine distance generally yields more accurate semantic rankings. Rewriting the previous query with cosine distance:
SELECT
name,
embedding <=> '[0.80, 0.19, 0.40]' AS cosine_distance
FROM gear
ORDER BY cosine_distance
LIMIT 3;Enhancing Performance with Vector Indexes
Without an index, every similarity query performs a full sequential scan, computing distances for every row. While acceptable for small datasets, this becomes a severe performance bottleneck with millions of records. pgvector provides two approximate nearest-neighbor (ANN) index types to accelerate these lookups: HNSW and IVFFlat.
Hierarchical Navigable Small Worlds (HNSW) constructs a multi-layer graph where nodes (vectors) are connected to a limited number of neighbors across various resolution levels. Queries navigate this graph from coarser to finer layers, efficiently locating nearest neighbors. HNSW offers an excellent speed-to-recall ratio and is incrementally buildable, meaning new rows can be added without rebuilding the entire index. However, it demands more memory and can take longer to construct than IVFFlat. For cosine distance, an HNSW index would be created as follows:
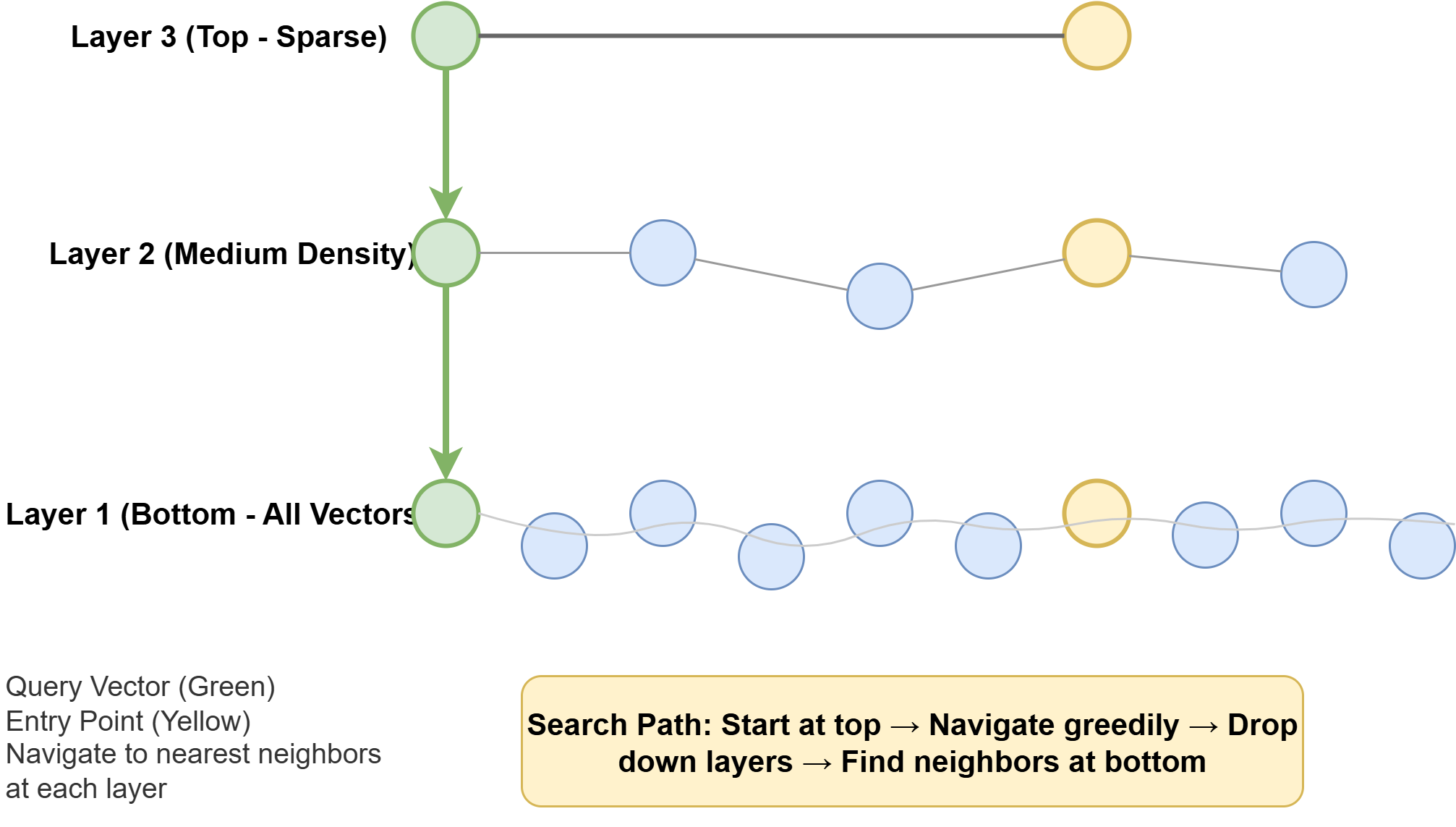
CREATE INDEX ON gear
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);Here, m defines the maximum connections per node, and ef_construction controls the candidate list size during graph construction, parameters that can be tuned for recall and performance.
Inverted File Flat (IVFFlat) partitions the vector space into a fixed number of clusters during index construction. At query time, it only searches clusters closest to the query vector. IVFFlat builds faster and uses less memory but is sensitive to post-construction data additions, which might land in poorly matched clusters and degrade recall over time.
It is paramount that the operator class used in the index definition (vector_cosine_ops, vector_l2_ops, etc.) precisely matches the distance operator used in the queries. A mismatch will cause PostgreSQL to fall back to a full sequential scan, negating the performance benefits of the index. Developers should always use EXPLAIN to verify index utilization.
Filtered Similarity Search: Combining Vector and Relational Capabilities
One of pgvector’s most powerful advantages is its seamless integration with PostgreSQL’s query planner. This allows for combining vector ordering with standard SQL WHERE clauses, JOINs, and aggregations without needing a separate query language or data migration. For example, to find the two most similar footwear products to a query:
SELECT
name,
category,
embedding <-> '[0.80, 0.19, 0.40]' AS distance
FROM gear
WHERE category = 'Footwear'
ORDER BY distance
LIMIT 2;This query first filters products by category and then applies the vector similarity search, demonstrating how pgvector enables sophisticated hybrid search capabilities within a single database system. The output would correctly identify the relevant footwear items, highlighting the precision gained from combining semantic understanding with traditional relational filtering.
name | category | distance
-------------------+----------+----------
Salomon Speedcross 6 | Footwear | 0.0004
Merrell Moab 3 GTX | Footwear | 0.0016
(2 rows)Broader Implications and Future Outlook
The integration of vector similarity search directly into PostgreSQL via pgvector represents a significant step towards simplifying modern application architectures. Developers can now leverage the familiarity and robustness of a relational database for both structured data and high-dimensional vector embeddings, reducing the complexity of managing multiple data stores. This approach offers benefits in terms of data consistency, transactional integrity, and operational overhead.
Industry experts anticipate that solutions like pgvector will accelerate the adoption of AI-powered features across a broader spectrum of applications. As AI models become more ubiquitous, the ability to store and query their outputs (embeddings) alongside traditional data in a unified system streamlines development workflows and enhances data governance. While specialized vector databases might still offer peak performance for extremely large-scale, high-throughput vector-only workloads, pgvector provides a compelling alternative for applications where data locality, SQL compatibility, and simplified infrastructure are paramount. The ongoing development of pgvector, alongside the broader PostgreSQL ecosystem, promises further optimizations and features, solidifying its role as a versatile and powerful tool for building the next generation of intelligent applications. The key decisions for developers remain the choice of an embedding model, the appropriate distance metric, and the selection of an indexing strategy, all of which directly influence the accuracy and performance of semantic search.
