
AWS has announced the launch of Amazon S3 Files, a groundbreaking new service designed to seamlessly integrate AWS compute resources with Amazon Simple Storage Service (S3) by offering a fully-featured, high-performance file system interface directly to S3 buckets. This development marks a significant evolution in cloud storage, effectively blurring the lines between traditional object storage and file systems, a distinction that has long been a foundational concept for cloud architects and data engineers.
For over a decade, AWS customers have navigated the inherent differences between object storage, characterized by its flat structure, immutability (requiring replacement of an entire object for any change), and massive scalability, and hierarchical file systems, which offer byte-level modifications and familiar directory structures. This architectural dichotomy often forced organizations to choose between the cost-efficiency, durability, and vast scale of S3 for archival and data lake purposes, and the interactive, mutable capabilities of file systems for compute-intensive applications. Amazon S3 Files directly addresses this challenge, transforming S3 into a central data hub that can be accessed as a native file system from virtually any AWS compute instance, container, or function.
Historical Context: The Evolving Landscape of Cloud Storage

The journey of cloud storage began with services like Amazon S3, launched in 2006, pioneering the concept of object storage. S3 quickly became the backbone for countless applications, data lakes, and backups due to its eleven nines of durability, high availability, and pay-as-you-go pricing model. However, its object-based nature meant that workloads requiring frequent, granular modifications or hierarchical access patterns often necessitated a separate file system solution. This led to the development of services like Amazon Elastic File System (EFS) in 2016, providing scalable, fully managed NFS file storage for Linux-based workloads, and later Amazon FSx, which expanded file system options to include Windows File Server, Lustre, NetApp ONTAP, and OpenZFS, catering to specific enterprise and high-performance computing (HPC) needs.
While these services provided comprehensive solutions for various storage requirements, the fundamental separation between object and file storage often resulted in data silos. Organizations frequently found themselves duplicating data across S3 and file systems, or implementing complex synchronization mechanisms to ensure consistency, adding to operational overhead and cost. Data movement between these different storage types could also introduce latency and complexity, particularly for emerging workloads like machine learning (ML) model training, big data analytics, and agentic AI systems that often require both the vast scale of S3 and the interactive, shared access of a file system. The introduction of S3 Files represents a strategic move by AWS to unify these experiences, simplifying cloud architectures and streamlining data workflows.
Technical Deep Dive: How S3 Files Bridges the Gap
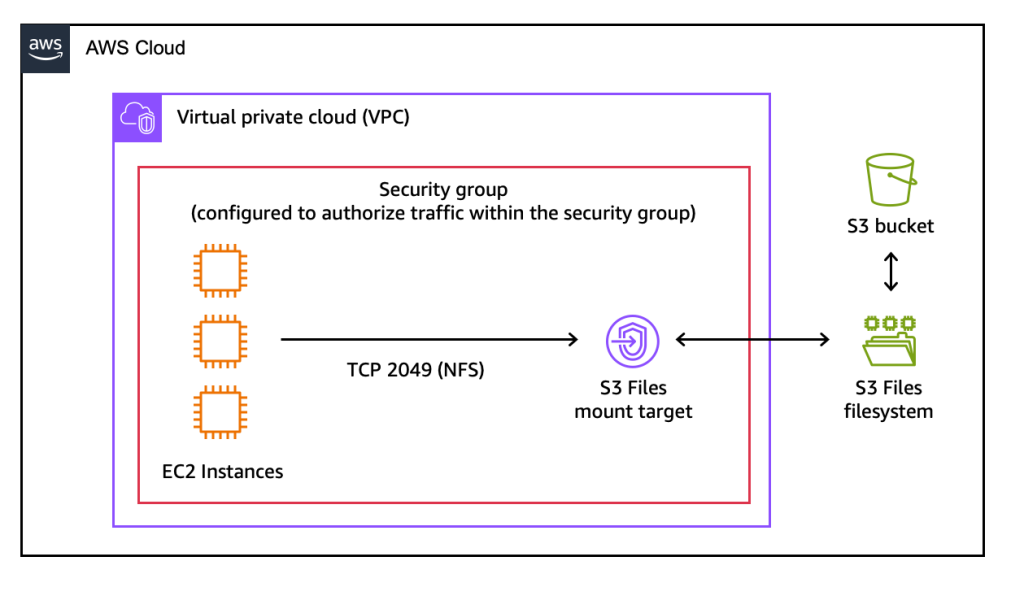
At its core, Amazon S3 Files allows S3 buckets to be mounted as file systems, supporting standard Network File System (NFS) v4.1+ operations including creating, reading, updating, and deleting files and directories. This means developers and data scientists can interact with S3 data using familiar file system commands and tools, without needing to refactor applications designed for file-based access.

Under the hood, S3 Files leverages Amazon Elastic File System (EFS) technology to deliver its high-performance characteristics. When data is actively accessed through the S3 Files interface, relevant file metadata and contents are intelligently placed onto a high-performance storage layer, resulting in sub-millisecond latencies (approximately 1ms) for frequently accessed data. This caching mechanism is dynamic and optimized for performance, ensuring that interactive workloads receive the responsiveness they demand.
For larger files or sequential reads that might not benefit from being fully cached in the high-performance layer, S3 Files intelligently serves these directly from Amazon S3, maximizing throughput. Furthermore, for byte-range reads, only the requested portions of a file are transferred, minimizing data movement and associated costs. The system also incorporates intelligent pre-fetching capabilities, anticipating data access patterns to proactively load data, further enhancing performance. Users retain fine-grained control over what data (full file data or metadata only) is stored on the high-performance layer, allowing for optimization based on specific workload access patterns.
Crucially, S3 Files maintains automatic synchronization between the mounted file system and the underlying S3 bucket. Changes made on the file system are reflected as new objects or new versions of existing objects in the S3 bucket within minutes. Conversely, changes to objects directly in the S3 bucket become visible in the file system within seconds, though occasional variations up to a minute or longer can occur. This close-to-open consistency, a hallmark of NFS, makes S3 Files ideal for shared, interactive workloads where multiple compute resources need to concurrently read, write, and mutate data.
Simplifying Workloads: Use Cases and Benefits
The implications of Amazon S3 Files are far-reaching, particularly for data-intensive and collaborative workloads.
- Machine Learning and AI Training: ML models often require access to vast datasets stored in S3. Historically, this involved complex data pipelines to move data to file systems for training, or custom connectors to access S3 directly. With S3 Files, ML engineers can mount their S3 data lakes as file systems, allowing ML frameworks and libraries, many of which are file-system native, to interact with the data directly. This simplifies data preparation, accelerates training iterations, and eliminates data duplication. Agentic AI systems, which frequently rely on file-based tools and Python libraries, will also benefit from seamless access to shared data.
- Big Data Analytics: Workloads involving Hadoop, Spark, or other analytics engines can now leverage S3 Files to process data directly from S3 with file system semantics, potentially simplifying data access layers and improving performance for iterative queries or transformations.
- DevOps and Production Applications: Applications that are designed to read and write to local file systems can now operate on S3 data without modification. This simplifies migration paths for legacy applications to the cloud and streamlines the development of cloud-native applications that require shared, mutable storage.
- Content Creation and Media Workflows: For teams collaborating on large media files, S3 Files provides a shared, high-performance file system interface over S3, eliminating the need for complex file synchronization tools or dedicated media storage solutions.
- Data Sharing Across Clusters: The ability to attach S3 Files to multiple compute resources enables effortless data sharing across different clusters—whether EC2 instances, ECS containers, EKS pods, or Lambda functions—without the overhead of data duplication. This fosters greater collaboration and efficiency in multi-tenant or distributed environments.
AWS officials emphasized that S3 Files empowers organizations to designate S3 as the ultimate central repository for all their data, from raw ingested data to processed outputs, knowing it is readily accessible via a file system interface. This eliminates the longstanding tradeoff between S3’s cost-effectiveness and durability, and a file system’s interactive capabilities.
Comparison with Existing AWS File Services
With S3 Files entering the market, customers might wonder how it fits alongside existing AWS file storage services like Amazon EFS and Amazon FSx. AWS has provided clarity on the optimal use cases for each:
- Amazon S3 Files: Best suited for interactive, shared access to data that primarily resides in Amazon S3 through a high-performance file system interface. It excels in workloads where multiple compute resources (production applications, agentic AI agents, ML training pipelines) need to collaboratively read, write, and mutate data with sub-millisecond latency and automatic synchronization with S3. It leverages S3’s inherent scalability and cost-efficiency for the vast majority of data while providing a performant front-end.
- Amazon Elastic File System (EFS): Ideal for general-purpose, shared file storage for Linux-based workloads that require high availability, durability, and scalability without needing to store data in S3 as its primary backing store. EFS is a fully managed NFS file system from the ground up, offering elastic scaling and pay-for-what-you-use pricing. It’s often used for web serving, content management, application development, and home directories. While S3 Files uses EFS technology under the hood for its high-performance layer, EFS itself is a distinct service for native file system needs.
- Amazon FSx: This family of services provides fully managed third-party file systems for specific enterprise workloads.
- FSx for Lustre: Optimized for high-performance computing (HPC) and GPU clusters, delivering extremely high throughput and low latency for data-intensive workloads like scientific simulations and complex data analytics.
- FSx for Windows File Server: Provides fully managed, highly available Windows file shares with native support for SMB protocol, Active Directory integration, and familiar Windows features. Essential for Windows-based applications and user shares.
- FSx for NetApp ONTAP: Offers the rich data management features and protocol support of NetApp ONTAP, including multi-protocol access (NFS, SMB, iSCSI), data replication, snapshots, and deduplication. Suitable for demanding enterprise applications and data center migrations.
- FSx for OpenZFS: Delivers high-performance, open-source ZFS file systems with advanced data management features like snapshots, clones, and data compression. Ideal for workloads requiring high throughput and IOPS.
In essence, S3 Files serves as the bridge for S3-centric workloads requiring file system access, while EFS and FSx remain the go-to choices for workloads that demand specific native file system capabilities or are migrating from on-premises NAS environments.
Pricing and Global Availability
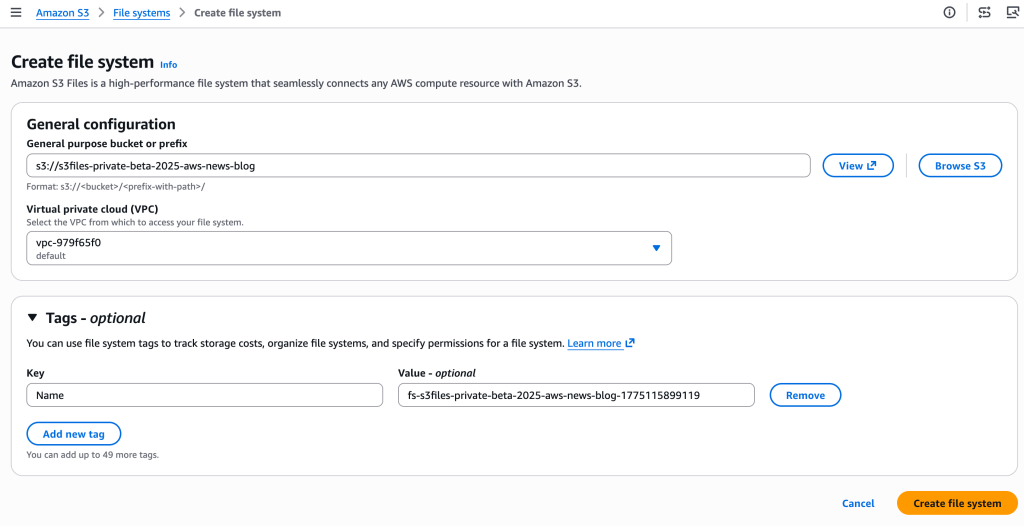
Amazon S3 Files is available today in all commercial AWS Regions, enabling global access to this new capability. The pricing model for S3 Files is structured to align with its usage: customers pay for the portion of data stored in the S3 file system’s high-performance layer, for small file read and all write operations to the file system, and for S3 requests incurred during data synchronization between the file system and the S3 bucket. The underlying Amazon S3 pricing for data stored in buckets remains separate. This model aims to provide cost-effectiveness by only charging for the active, high-performance portion of the file system while leveraging S3’s low-cost storage for the bulk of the data.
Broader Impact and Future Outlook
The introduction of Amazon S3 Files is more than just a new feature; it represents a significant shift in cloud data management paradigms. Industry analysts anticipate that this service will accelerate the adoption of S3 as a universal data platform, simplifying cloud architectures by eliminating data silos and the complexities of manual data movement and synchronization. It empowers organizations to build more agile and efficient data pipelines, especially for nascent fields like generative AI, where models often interact with vast, constantly evolving datasets.
By providing a familiar file system interface over S3, AWS is lowering the barrier to entry for many traditional applications to leverage the benefits of cloud object storage. This move reinforces AWS’s strategy to offer a comprehensive suite of storage solutions that cater to every imaginable workload, from cold archives to real-time analytics, while continuously innovating to simplify the user experience. As the volume and complexity of data continue to grow exponentially, services like S3 Files will be critical in enabling organizations to derive maximum value from their data assets without compromising on performance, cost, or operational simplicity. The unified approach promises to unlock new possibilities for data-driven innovation across various industries.
