
Amazon Web Services (AWS) has announced a significant new feature for Amazon Simple Storage Service (Amazon S3), enabling customers to create general-purpose buckets within their own account regional namespace. This enhancement fundamentally simplifies bucket creation and management, particularly as data storage needs escalate in both volume and complexity, offering a predictable and exclusive naming mechanism across multiple AWS Regions. The move is designed to mitigate long-standing challenges associated with the global uniqueness requirement for S3 bucket names, providing enterprises and developers with greater control and assurance over their cloud storage infrastructure.
Understanding the New Feature: Account Regional Namespaces in S3
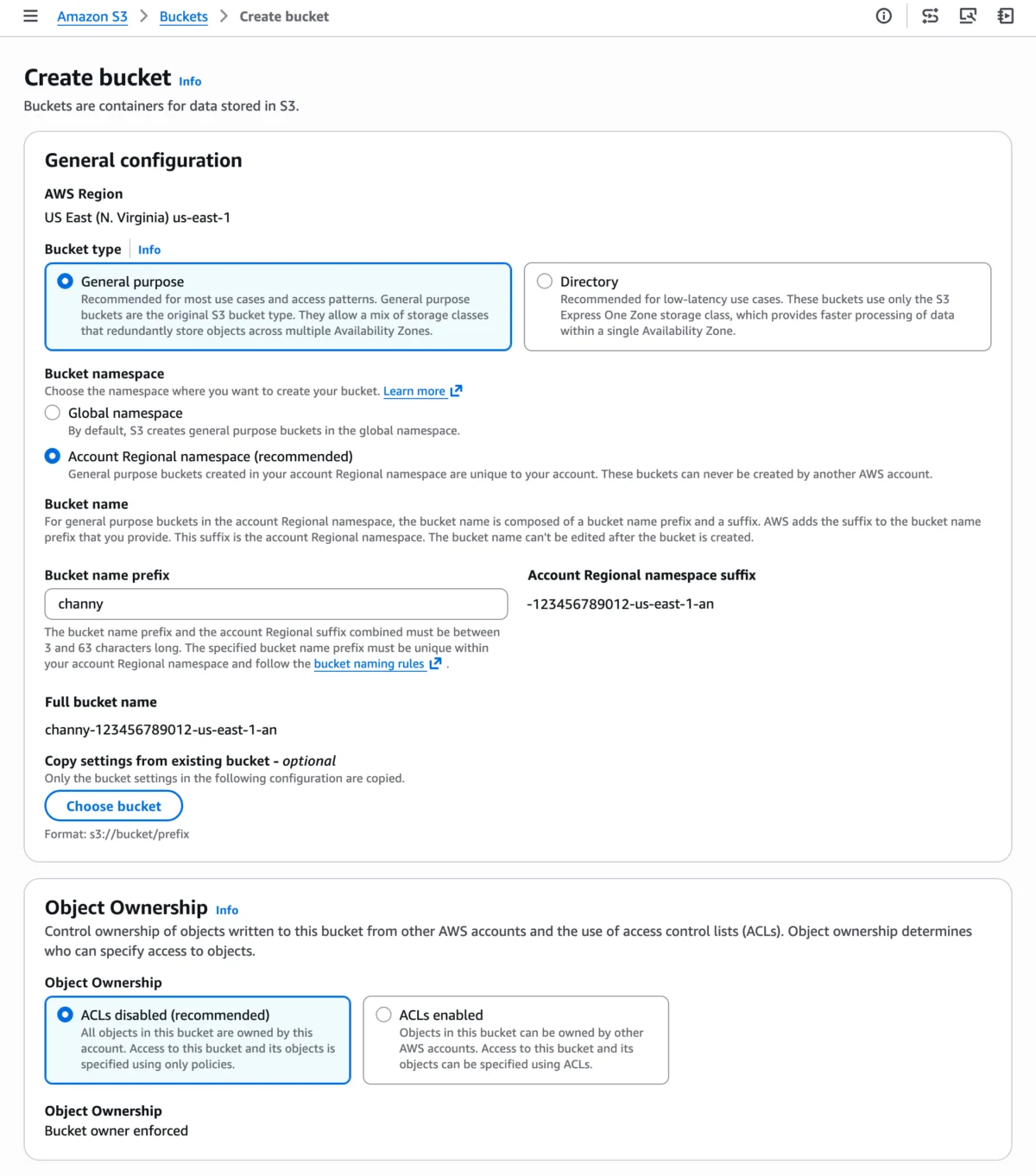
Historically, all Amazon S3 general-purpose bucket names had to be globally unique across all AWS accounts and regions. While this ensured a singular identifier for every bucket, it often led to naming collisions, frustration for developers attempting to secure intuitive names, and complex naming conventions within large organizations. The new account regional namespace feature directly addresses this by introducing a mechanism where bucket names are unique only within a customer’s specific AWS account and selected region, eliminating the global contention.
The core of this innovation lies in the appending of a unique, system-generated suffix to the user-defined bucket name prefix. This suffix is composed of the customer’s AWS account ID, the AWS Region, and an additional identifier (-an), ensuring the resulting full bucket name is exclusive to that account and region. For instance, a user might specify mycompany-data as their prefix. If their AWS account ID is 123456789012 and the region is us-east-1, the complete bucket name would automatically become mycompany-data-123456789012-us-east-1-an. Any attempt by another AWS account to create a bucket using this exact suffix, even with a different prefix, would be automatically rejected, thereby guaranteeing naming exclusivity. This mechanism frees users from the burden of constantly checking global availability and devising increasingly obscure names to avoid conflicts.
Technical Deep Dive: The Naming Convention
The new naming convention dictates that the user provides a bucket name prefix, to which AWS automatically appends the account ID, the region identifier, and the account-regional suffix. This structured format ([prefix]-[account-id]-[region]-an) ensures uniqueness without requiring global coordination. The combined length of the prefix and the account regional suffix must adhere to S3’s existing bucket naming rules, specifically being between 3 and 63 characters long. This structure provides a clear, machine-readable identifier that inherently includes critical metadata about the bucket’s ownership and geographical placement.
Background and Context: The Evolution of S3 Naming
Amazon S3, launched in 2006, revolutionized cloud storage by offering highly scalable, durable, and cost-effective object storage. Its initial design, where bucket names were globally unique, was pragmatic for a nascent cloud ecosystem. However, as AWS grew to serve millions of customers and expanded its global footprint to dozens of regions, the global namespace model began to present operational challenges.
The Global Namespace Challenge
The global uniqueness requirement meant that if "my-first-bucket" was taken by an account in us-east-1, no other AWS account, regardless of region, could use that exact name. This often led to:
- Naming Collisions: As more customers adopted S3, finding simple, intuitive, and available bucket names became increasingly difficult.
- Complex Naming Conventions: Organizations had to implement elaborate internal naming schemes (e.g.,
project-environment-region-purpose-uniqueid) to ensure internal consistency and avoid collisions, adding cognitive load and potential for error. - Operational Overhead: Developers frequently encountered "BucketAlreadyExists" errors during automated deployments, necessitating manual intervention or redesign of naming logic.
- Multi-Region Strategy Hurdles: For applications deployed across multiple regions, maintaining consistent naming conventions while ensuring global uniqueness often involved adding region-specific identifiers to the bucket names, even when the underlying data was entirely separate.
Addressing Developer Pain Points
This new feature represents a significant step in addressing these long-standing developer pain points. By shifting the uniqueness scope from global to account-regional, AWS acknowledges the maturity of its cloud platform and the evolving needs of its enterprise customers. It allows for a more natural and logical naming scheme, where a bucket named production-logs in us-east-1 for Account A can coexist with a production-logs bucket in us-east-1 for Account B, or even in eu-west-1 for Account A, without any naming conflicts. This mirrors how resource naming often works in other cloud services and on-premises environments, providing a more intuitive experience for cloud architects and developers.
Enhanced Security and Governance
Beyond simplifying naming, the account regional namespace feature integrates robust security and governance capabilities through AWS Identity and Access Management (IAM) policies and AWS Organizations Service Control Policies (SCPs). Security teams can now enforce the use of this new naming convention across an entire organization or specific accounts.
This is achieved using the new s3:x-amz-bucket-namespace condition key in IAM policies. By leveraging this condition key, administrators can mandate that employees only create buckets within their account regional namespace. For example, an SCP at the organizational level could prevent the creation of any new S3 general-purpose buckets that do not utilize the account regional namespace. This ensures compliance with internal naming standards, prevents accidental creation of globally named buckets, and reinforces a consistent security posture. Such centralized control is invaluable for large enterprises managing hundreds or thousands of AWS accounts, helping to standardize infrastructure deployment and reduce the surface area for misconfigurations. The ability to programmatically enforce these standards through policies streamlines governance and strengthens the overall security framework for data storage.

Seamless Integration Across AWS Tools
AWS has ensured that the new account regional namespace feature is readily accessible and manageable through its existing ecosystem of tools, minimizing the learning curve and enabling rapid adoption. Users can leverage the AWS Management Console, AWS Command Line Interface (CLI), AWS SDKs, and infrastructure-as-code platforms like AWS CloudFormation.
Deployment with AWS Management Console
For interactive creation, users can simply navigate to the Amazon S3 console, choose "Create bucket," and then select the "Account regional namespace" option. This intuitive interface guides them through the process, allowing them to provide their desired bucket name prefix. The console automatically handles the appending of the account and region-specific suffix, simplifying the creation workflow for individual users and smaller teams.
Deployment with AWS Command Line Interface (CLI)
The AWS CLI provides a powerful, scriptable interface for managing AWS resources. To create a bucket with an account regional namespace using the CLI, users can specify the --bucket-namespace account-regional parameter during the create-bucket command.
$ aws s3api create-bucket --bucket mybucket-123456789012-us-east-1-an
--bucket-namespace account-regional
--region us-east-1This command explicitly tells S3 to create the bucket within the account’s regional namespace, using the provided full bucket name which includes the generated suffix. This method is ideal for scripting and automating bucket creation tasks.
Programmatic Creation with AWS SDK for Python (Boto3)
Developers can integrate this functionality directly into their applications using AWS SDKs. The Python SDK (Boto3) provides a clear example of how to programmatically create these buckets. The CreateBucket API request can now include a BucketNamespace parameter set to "account-regional". The SDK example provided demonstrates how to dynamically fetch the account ID and region, construct the full bucket name with the appropriate suffix, and then make the API call.
import boto3
class AccountRegionalBucketCreator:
"""Creates S3 buckets using account-regional namespace feature."""
ACCOUNT_REGIONAL_SUFFIX = "-an"
def __init__(self, s3_client, sts_client):
self.s3_client = s3_client
self.sts_client = sts_client
def create_account_regional_bucket(self, prefix):
"""
Creates an account-regional S3 bucket with the specified prefix.
Resolves caller AWS account ID using the STS GetCallerIdentity API.
Format: ---an
"""
account_id = self.sts_client.get_caller_identity()['Account']
region = self.s3_client.meta.region_name
bucket_name = self._generate_account_regional_bucket_name(
prefix, account_id, region
)
params =
"Bucket": bucket_name,
"BucketNamespace": "account-regional"
if region != "us-east-1":
params["CreateBucketConfiguration"] =
"LocationConstraint": region
return self.s3_client.create_bucket(**params)
def _generate_account_regional_bucket_name(self, prefix, account_id, region):
return f"prefix-account_id-regionself.ACCOUNT_REGIONAL_SUFFIX"
if __name__ == '__main__':
s3_client = boto3.client('s3')
sts_client = boto3.client('sts')
creator = AccountRegionalBucketCreator(s3_client, sts_client)
response = creator.create_account_regional_bucket('test-python-sdk')
print(f"Bucket created: response")This example illustrates how developers can build robust, automated solutions that dynamically create S3 buckets aligned with their organizational naming standards and regional deployments.
Automating with AWS CloudFormation
For infrastructure-as-code (IaC) practitioners, AWS CloudFormation offers powerful capabilities to define and deploy AWS resources. CloudFormation templates can be updated to leverage the new feature, simplifying the management of S3 buckets within the account regional namespace. By utilizing CloudFormation’s pseudo parameters, AWS::AccountId and AWS::Region, users can dynamically construct bucket names.
Two primary methods are available within CloudFormation:
- Using
!SubwithBucketName: This approach allows the explicit construction of the full bucket name within the template.Resources: MyS3Bucket: Type: AWS::S3::Bucket Properties: BucketName: !Sub "amzn-s3-demo-bucket-$AWS::AccountId-$AWS::Region-an" BucketNamespace: "account-regional" - Using
BucketNamePrefix: This streamlined option allows users to provide only the customer-defined prefix, with CloudFormation automatically appending the necessary account and region-specific suffix.Resources: MyS3Bucket: Type: AWS::S3::Bucket Properties: BucketNamePrefix: 'amzn-s3-demo-bucket' BucketNamespace: "account-regional"These CloudFormation integrations are particularly beneficial for organizations that rely heavily on IaC for consistent and repeatable infrastructure deployments across multiple accounts and regions. They enable teams to standardize their bucket naming conventions within their templates, reducing manual errors and accelerating deployment cycles.
Implications for Developers and Enterprises
The introduction of account regional namespaces for S3 general-purpose buckets carries significant implications for various stakeholders within the AWS ecosystem.

Streamlined Multi-Region Deployments
For enterprises operating global applications or requiring data locality across multiple AWS Regions, this feature dramatically simplifies their storage strategy. Developers can now use identical, meaningful bucket name prefixes across different regions (e.g., app-logs in us-east-1 and app-logs in eu-central-1) without fear of collision. This consistency enhances readability of infrastructure code, reduces mental overhead, and makes it easier to manage deployments and data replication strategies. It aligns S3 naming more closely with the regionalized nature of many other AWS services, fostering a more cohesive cloud architecture.
Boosting Operational Efficiency and DevOps Practices
DevOps teams will find bucket provisioning more predictable and less error-prone. Automated scripts and CI/CD pipelines can now confidently create buckets with predefined prefixes, knowing that the uniqueness will be handled at the account-regional level. This eliminates the need for complex logic to generate unique names or retry mechanisms for naming conflicts, speeding up development and deployment cycles. The ability to enforce these naming standards via IAM and SCPs further enhances operational governance, ensuring that all teams adhere to best practices without manual oversight.
Enhanced Security Posture
The ability to enforce account regional namespaces through IAM and AWS Organizations SCPs is a crucial security benefit. It allows organizations to standardize their S3 deployments, making it easier to audit and manage permissions. By ensuring that all new general-purpose buckets conform to an internal, account-specific naming convention, security teams can reduce the likelihood of misconfigured or rogue buckets that could expose sensitive data. This proactive governance capability is vital in today’s threat landscape, where data breaches often stem from simple configuration errors.
Key Considerations and Limitations
While the account regional namespace feature is a powerful addition, it comes with specific considerations and limitations that users should be aware of:
- New Buckets Only: This feature is exclusively for creating new general-purpose buckets. Existing S3 buckets in the global namespace cannot be renamed or migrated to the account regional namespace. Users wishing to adopt the new naming convention for existing data will need to create new buckets and migrate their data.
- General Purpose Buckets Only: The account regional namespace is supported only for general-purpose S3 buckets. Other specialized S3 bucket types, such as S3 table buckets, S3 vector buckets, and S3 directory buckets, already operate within account-level or zonal namespaces and are not impacted by this new feature. These specialized buckets have their own distinct naming and operational characteristics.
- Character Limits: The combined length of the bucket name prefix and the automatically generated account regional suffix must be between 3 and 63 characters, adhering to standard S3 bucket naming conventions.
Availability and Global Rollout
The new capability for creating general-purpose buckets in your account regional namespace is now broadly available across 37 AWS Regions worldwide. This extensive rollout includes critical regions such as the AWS China Regions and AWS GovCloud (US) Regions, ensuring that a wide array of global customers, including those with stringent regulatory requirements, can leverage this feature. Importantly, AWS has confirmed that there is no additional cost associated with using this new naming feature; it is included as part of the standard Amazon S3 service.
This widespread availability underscores AWS’s commitment to providing consistent, advanced features across its global infrastructure. For organizations with distributed operations or those serving customers in diverse geographic locations, the immediate and broad availability means they can implement consistent storage strategies without regional disparities in functionality.
Expert Reactions and Industry Outlook
Industry analysts and cloud architecture experts are expected to widely welcome this announcement. The global uniqueness constraint for S3 bucket names has been a recurring point of feedback from the AWS developer community for years. This new feature directly addresses that feedback, simplifying a fundamental aspect of cloud storage.
"This move by AWS is a testament to their continuous commitment to customer feedback and operational excellence," commented a leading cloud architect, requesting anonymity as they are not authorized to speak for their firm. "The ability to define S3 bucket names within an account’s regional scope removes a significant friction point for multi-account and multi-region deployments. It will streamline automation, improve infrastructure-as-code consistency, and free up developers to focus on application logic rather than wrestling with naming conventions."
This enhancement is likely to be seen as aligning S3 more closely with modern DevOps practices and enterprise cloud governance models. It reflects a broader trend in cloud computing towards providing more localized and context-aware resource management, moving away from global constraints where possible. As organizations continue to scale their cloud footprints and embrace sophisticated automation, features like the account regional namespace become essential building blocks for resilient and efficient cloud operations.
Conclusion
The introduction of account regional namespaces for Amazon S3 general-purpose buckets marks a pivotal evolution in AWS’s storage services. By shifting the paradigm from global uniqueness to account-regional exclusivity, AWS empowers customers with enhanced naming predictability, simplified management, and improved governance capabilities. This feature will undoubtedly accelerate cloud adoption for complex enterprise workloads, streamline multi-region deployments, and bolster the efficiency of DevOps teams. As cloud infrastructure continues to grow in scale and complexity, innovations that simplify fundamental operations, like resource naming, are invaluable. AWS customers are encouraged to explore this new feature via the Amazon S3 console and provide feedback through AWS re:Post or their usual AWS Support channels, contributing to the ongoing refinement of cloud services.
