
Amazon Web Services (AWS) today unveiled a significant new metadata capability for Amazon Simple Storage Service (Amazon S3) called "annotations," designed to allow organizations to attach rich, large-scale business context directly to their objects. This innovation marks a pivotal step in enabling more intelligent, autonomous data workflows, particularly for AI-driven applications, by providing an unprecedented level of metadata flexibility and scale within S3.
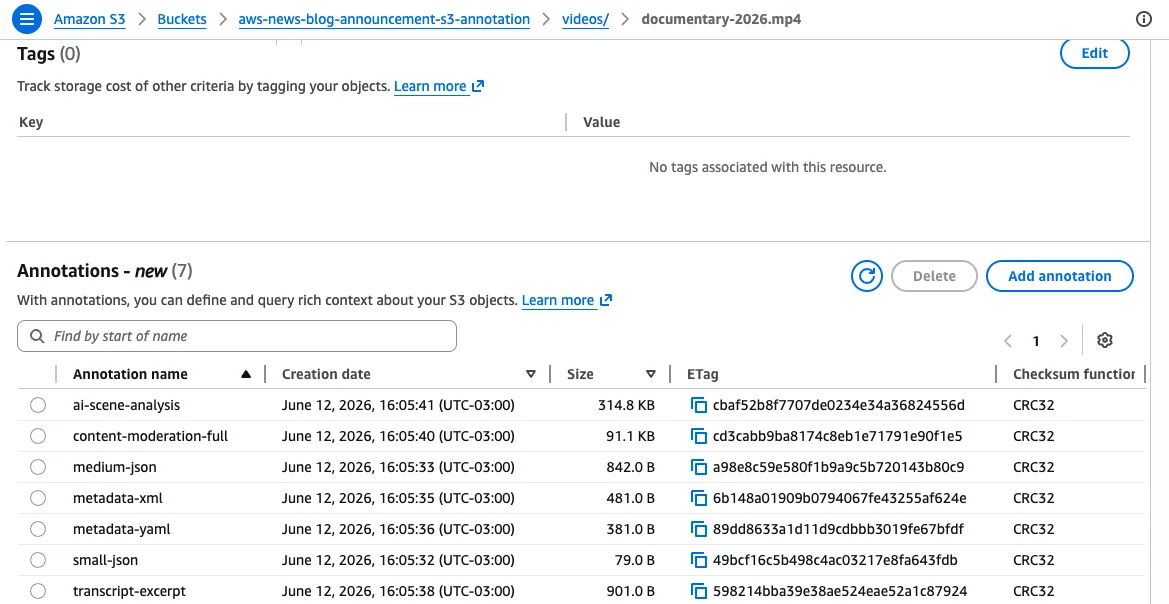
The announcement addresses a critical and evolving challenge in modern data management: the need for metadata that is as dynamic and scalable as the data it describes. Historically, managing comprehensive business context alongside petabytes of unstructured data has required complex, costly, and often disparate metadata systems. S3 annotations promise to streamline this process by allowing users to store up to 1,000 named annotations per object, each up to 1 MB in size, culminating in a remarkable 1 GB of contextual data per object. These annotations can be stored in flexible formats such as JSON, XML, YAML, or plain text, offering immense versatility. Crucially, annotations can be modified or deleted at any time without necessitating the re-writing of the associated objects, ensuring that object context remains perpetually current and relevant.
The Evolution of Data and the Metadata Imperative
The rapid proliferation of data, particularly unstructured data, has transformed enterprise IT landscapes. Reports consistently indicate that global data creation is accelerating, with projections suggesting zettabytes of data being generated annually. A substantial portion of this data finds its home in object storage solutions like Amazon S3, which has become the de facto standard for data lakes, archiving, and cloud-native applications. However, storing data is only the first step; extracting value from it hinges on effective data discovery, understanding, and governance.
In recent years, the rise of artificial intelligence (AI) and machine learning (ML) has intensified the demand for richer, more accessible metadata. AI agents and autonomous workflows are increasingly tasked with finding, understanding, and acting on vast datasets without human intervention. This shift necessitates metadata that can evolve alongside the data itself, scale to petabytes of objects, and remain queryable without incurring expensive retrieval costs or requiring complex data rehydration processes. Traditional metadata approaches, while functional for their intended purposes, often fall short in meeting these advanced requirements.
Bridging the Metadata Gap: S3 Annotations in Detail
Amazon S3 has long offered various metadata capabilities. System-defined metadata captures fundamental properties like object size, storage class, and creation time. Object tags provide key-value pairs primarily for operational tasks such as access control, lifecycle management, and cost allocation, limited to 10 tags per object. User-defined metadata allows for small amounts of custom information to be added at upload time, typically as HTTP headers, with a size limit of 2 KB. While these capabilities are effective for their specific use cases, they present limitations when organizations need to attach substantially richer, more mutable, and deeply integrated business context.
Annotations directly address these limitations by providing metadata capabilities at a fundamentally different scale and with unparalleled flexibility. Unlike immutable tags or static user-defined metadata, annotations are fully mutable and can store significantly larger payloads, up to 1,000 annotations per object, totaling 1 GB. This allows for a granular and expansive description of each object, whether it’s an AI-generated transcript of an audio file, a detailed content rating for a video, or technical specifications for an engineering schematic. An AWS spokesperson noted, "This innovation directly responds to the escalating need for more intelligent and self-managing data environments, empowering organizations to unlock deeper insights from their data without the operational overhead of managing external metadata systems."

A key advantage of S3 annotations is their inherent integration with the object lifecycle. The contextual data stored as annotations moves automatically with the object during copy, replication, and cross-region transfers, ensuring data consistency and integrity across distributed environments. When an object is deleted, its associated annotations are also automatically removed, simplifying data governance and compliance efforts.
Transforming Industry Use Cases
The introduction of S3 annotations is expected to solve complex metadata challenges across a multitude of industries:
- Media and Entertainment: A media company can attach comprehensive technical specifications (codec, resolution, audio tracks, frame rate), AI-produced summaries, content ratings, and licensing information directly to video and audio assets. This streamlines asset management, facilitates automated content distribution, and enhances searchability for editors and AI-driven content platforms.
- Healthcare and Life Sciences: For genomic sequencing data or medical images, annotations can store detailed patient consent forms, experimental parameters, data lineage, and compliance certifications (e.g., HIPAA, GDPR status). This ensures robust data governance, simplifies auditing, and accelerates research by providing immediate context for sensitive datasets.
- Financial Services: Financial institutions can use annotations to attach regulatory compliance data, audit trails, data classification levels, and retention policies to transactional records or archived documents. This improves risk management, simplifies regulatory reporting, and supports legal discovery processes.
- Manufacturing and IoT: Sensor data streams or CAD files can be enriched with annotations describing device specifications, calibration history, environmental conditions at data capture, and maintenance logs. This enables predictive maintenance, quality control, and faster root cause analysis in complex industrial environments.
- Data Science and AI/ML: Data scientists can leverage annotations to store model training parameters, data preprocessing steps, feature engineering details, data quality metrics, and AI-generated labels directly with their datasets. This creates a self-documenting data lake, improves model reproducibility, and accelerates the development and deployment of AI applications. An industry expert commented, "The ability to embed rich, machine-readable context directly with data objects is a game-changer for AI/ML workflows. It fundamentally shifts how AI models will discover, understand, and interact with data, moving us closer to truly autonomous data pipelines."
Seamless Integration and Queryability at Scale
The true power of S3 annotations is fully realized when integrated with S3 Metadata annotation tables. When enabled on a bucket, S3 automatically indexes annotations into a fully managed Apache Iceberg table. Apache Iceberg is an open table format for large analytic datasets, known for its performance and schema evolution capabilities. These "annotation tables" become immediately queryable through Amazon Athena and any other Iceberg-compatible analytics engine.
This integration eliminates the traditional headache of managing separate databases or "sidecar files" for metadata, which often require complex synchronization workflows and can incur significant operational and storage costs. With annotations flowing into managed tables, context becomes queryable at petabyte scale without requiring object restoration or retrieval charges, even for objects stored in S3 Glacier or other archival storage classes.
For AI agents, the S3 Tables Metadata Catalog Protocol (MCP) server provides a standardized interface. This allows AI models to query annotations using natural language, transforming data discovery. Imagine asking an AI agent, "Find all PG-rated movies with Spanish subtitles from 2023," and receiving results in seconds, a task that would traditionally require querying multiple, disconnected systems and potentially hours of manual effort.
Getting Started and Technical Implementation
To begin leveraging S3 annotations, users must ensure their AWS Identity and Access Management (IAM) policy or bucket policy grants permissions for s3:PutObjectAnnotation and s3:GetObjectAnnotation actions. Annotations can then be added to any existing or new S3 object using the PutObjectAnnotation API.

For instance, using the AWS Command Line Interface (AWS CLI), a media company could attach technical specifications and an AI-produced summary to a video asset:
# Create a JSON file with technical metadata
cat > mediainfo.json << 'EOF'
"codec":"H.265","resolution":"3840x2160","audio_tracks":8,"frame_rate":29.97
EOF
# Attach it as an annotation named 'mediainfo'
aws s3api put-object-annotation
--bucket my-media-bucket
--key videos/documentary-2026.mp4
--annotation-name mediainfo
--annotation-payload ./mediainfo.json
# Attach a plain-text AI-generated summary as a separate annotation named 'ai_summary'
echo "A 90-minute nature documentary covering wildlife migration patterns across three continents, featuring aerial footage and underwater sequences. Languages: English, Spanish, Portuguese." > ai_summary.txt
aws s3api put-object-annotation
--bucket my-media-bucket
--key videos/documentary-2026.mp4
--annotation-name ai_summary
--annotation-payload ./ai_summary.txtThese commands illustrate how two distinct annotations, one structured JSON and one plain text, can be associated with a single object. Each annotation is identified by a unique name, allowing for independent reading, modification, and deletion. This design supports concurrent enrichment workflows, where different teams can add relevant context without interfering with each other’s metadata.
Retrieving a specific annotation is straightforward using GetObjectAnnotation, while ListObjectAnnotations provides an overview of all annotations attached to an object. Annotations can be updated by simply calling PutObjectAnnotation again with the same annotation name, and DeleteObjectAnnotation removes them when no longer needed. For large objects uploaded via multipart upload, annotations can be attached after the upload completes.
Querying Annotations at Scale with S3 Metadata Tables
The ability to query across all annotations at scale unlocks profound insights. Enabling S3 Metadata annotation tables transforms individual object annotations into a collective, queryable dataset. This configuration is managed via the S3 console or the CreateBucketMetadataConfiguration API.
For example, to enable annotation tables:
"JournalTableConfiguration":
"RecordExpiration": "Expiration": "DISABLED"
,
"InventoryTableConfiguration": "ConfigurationState": "DISABLED" ,
"AnnotationTableConfiguration":
"ConfigurationState": "ENABLED",
"Role": "arn:aws:iam::123456789012:role/S3MetadataAnnotationRole"
Once enabled, any annotation attached to objects in the bucket will appear in the annotation table within approximately one hour. For buckets with existing annotated objects, S3 automatically backfills these annotations into the table, a process that runs in the background and can take several hours to days depending on the volume of data.
A significant architectural advantage of S3 annotation tables is their schema flexibility. Unlike traditional metadata tables that often require predefined schemas, annotation tables automatically adapt to any JSON, XML, or YAML structure. Each annotation becomes a row in the table, with its content stored in a text_value column, enabling queries across diverse annotation structures without requiring schema migrations.
Consider a practical query using Amazon Athena to find all video assets with more than 8 audio tracks across an entire media bucket:
SELECT DISTINCT bucket, object_key
FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."annotation"
WHERE name = 'mediainfo'
AND CAST(json_extract_scalar(text_value, '$.audio_tracks') AS INTEGER) > 8This query efficiently scans the annotation table, extracts the relevant field from the JSON content, and identifies objects meeting the specified criteria. For near real-time tracking of annotation changes, the journal table can be queried:
SELECT bucket, key, version_id, record_timestamp, annotation.name
FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."journal"
WHERE record_timestamp >= (current_date - interval '1' day)
AND annotation.name IS NOT NULL
AND record_type IN ('CREATE_ANNOTATION', 'DELETE_ANNOTATION')Such capabilities are invaluable for building event-driven workflows that dynamically respond to new or deleted contextual information. Furthermore, integrating with tools like Amazon SageMaker Unified Studio via the S3 Tables MCP server allows for natural language querying, democratizing data access for a wider range of users.
Broader Impact and Strategic Implications
The introduction of S3 annotations is more than just a new feature; it represents a strategic evolution in how organizations will manage and derive value from their massive datasets. It signifies a move towards truly intelligent data lakes where data is not just stored, but inherently understood and contextually rich from its inception.
For data governance, annotations offer a centralized and consistent mechanism to embed compliance, lineage, and sensitivity information directly with the data, simplifying auditing and regulatory adherence. For data mesh architectures, where data products are discoverable and self-describing, annotations provide the essential metadata layer to achieve this vision.
The billing for annotation storage is straightforward, always at S3 Standard rates, regardless of the parent object’s storage class. This predictable pricing model, combined with the significant operational efficiencies gained from eliminating separate metadata systems, presents a compelling economic case for adoption.
Amazon S3 annotations are now available in all AWS Regions, including the AWS China Regions. Annotation tables are accessible in all AWS Regions where S3 Metadata is available. This widespread availability ensures that organizations globally can immediately begin integrating this powerful capability into their data strategies.
Whether the objective is to empower AI agents to discover data autonomously, manage petabytes of complex media assets, or track detailed compliance context for archived datasets, S3 annotations offer the scale, flexibility, and integration needed to attach rich, mutable metadata directly to objects without the burden of managing separate, costly systems. This innovation reinforces Amazon S3’s position as a foundational service for modern, data-driven enterprises, paving the way for a new era of intelligent data management.
